 My recent talk, Playful Paradox with large numbers, infinity and logic, was a romp through various paradoxical topics in mathematics and logic for an audience of about 150 mathematics and philosophy undergraduate students at Fudan University in Shanghai, and since Fudan is reportedly a top-three university in China, you can expect that the audience was sharp.
My recent talk, Playful Paradox with large numbers, infinity and logic, was a romp through various paradoxical topics in mathematics and logic for an audience of about 150 mathematics and philosophy undergraduate students at Fudan University in Shanghai, and since Fudan is reportedly a top-three university in China, you can expect that the audience was sharp.
For a bit of fun, and in keeping with the theme, we decided to hold a Largest-Number Contest: what is the largest number that one can describe on an ordinary index card?
 My host Ruizhi Yang made and distributed announcement flyers for the contest a week before the talk, with a poster of the talk on one side, and a description of the contest rules on the other, and including a small card to be used for submissions. The rules were as follows:
My host Ruizhi Yang made and distributed announcement flyers for the contest a week before the talk, with a poster of the talk on one side, and a description of the contest rules on the other, and including a small card to be used for submissions. The rules were as follows:
- A submission entry consists of the description of a positive integer written on an ordinary index card, using common mathematical operations and notation or English words and phrases.
- Write legibly, and use at most 100 symbols from the ordinary ASCII character set. Bring your submission to the talk.
- Descriptions that fail to describe a number are disqualified.
- The submission with the largest number wins.
- The prize will be $1 million USD, divided by the winning number itself, rounded to the nearest cent, plus another small token prize.
Example submissions:
The population of Shanghai at this moment.
The submissions were collected at the beginning of my talk, which I began with a nod to Douglas Hofstadter, who once held a similar contest in his column at Scientific American magazine.
To win, I began, it seemed clear that the submitted number must be very large, and since the prize was to be one million dollars divided by the winning number, then this would mean that the prize should become small. So the goal is just to win, and not necessarily to win any money. The real prize is Pride.
So, what kind of numbers should one submit? Of course, anyone could think to write
But we can easily describe much larger numbers. A googol plex is the number
A googol bang means googol !, or googol factorial, the number obtained by multiplying googol
Continuing down this road, how about a googol plex bang, or a googol bang plex? Which of these is larger? Please turn away and think about it for a bit……..Have you got it? I think like this: A googol plex bang has the form
There is an entire hierarchy of such numbers, such as googol bang plex bang bang bang and googol bang bang plex plex plex. Which of these is bigger? Do you have a general algorithm for determining which of two such expressions is larger?
A googol stack is the number
where the height of the exponential stack is googol. Similarly, we may speak of
googol stack bang plex
googol bang plex stack
googol plex stack bang
Which of these is larger? If you think about it, you will see that the stack operator is far more powerful than bang or plex, and so we want to apply it to the biggest possible argument. So the second number is largest, and then the third and then the first, simply because the stack operator will overrule the other effects. Let us call this hierarchy, of all expressions formed by starting with googol and then appending any number of plex, bang or stack operators, as the googol plex bang stack hierarchy.
Question. Is there a feasible computational procedure to determine, of any two expressions in the googol stack bang plex hierarchy, which is larger?
This is an open question in the general case. I had asked this question at math.stackexchange, Help me put these enormous numbers in order, and the best currently known (due to user Deedlit) is that we have a simple algorithm that works for all expressions of length at most googol-2, and also works for all expressions having the same number of operators. But this algorithm breaks down for large expressions of much different lengths, since it seems that one must come to know the exact threshold where an enormous iteration of bangs and plexes can ultimately capture a stack. Of course, in principle one can compute these numbers exactly, given sufficient time and space resources, but the point of the question is to have a feasible algorithm, such as one that takes only polynomial time in the length of the input expressions. And a feasible such general algorithm is not known.
The fact that we seem to have difficulty comparing the relative sizes of expressions even in the simple googol plex bang stack hierarchy suggests that we may find it difficult to select a winning entry in the largest-number contest. And indeed, I’ll explain a bit later why there is no computable procedure to determine the winner of arbitrary size largest-number contests.
The numbers we’ve seen so far are actually rather small, so let’s begin to describe some much larger numbers. The most basic operation on natural numbers is the successor operation
Similarly, multiplication is repeated addition
and exponentiation is repeated multiplication
Similarly, stacks are repeated exponentiation. To simplify the expressions, Knuth introduced his uparrow notation, writing
So googol stack is the same as
In this notation,
where the number of times the stacking process is iterated is googol. This number is a vast number, whose description
But why stop there? We could of course continue with
So that
and so on. These ideas lead ultimately to the main line of the Ackerman function.
So we’ve described some truly vast numbers. But what is the winning entry? After all, there are only finitely many possible things to write on an index card in accordance with the limitation on the number of symbols. Many of these possible entries do not actually describe a number–perhaps someone might submit a piece of poetry or confess their secret love–but nevertheless among the entries that do describe numbers, there are only finitely many. Thus, it would seem that there must be a largest one. Thus, since the rules expressly allow descriptions of numbers in English, it would seem that we have found our winning entry:
The largest number describable on an index card according to the rules of this contest
which uses exactly 86 symbols. We seem to have argued that this expression describes a particular number, and accords with the rules, so we conclude that this is indeed provably the winning entry.
But wait a minute! If the expression above describes a number, then it would seem that the following expression also describes a number:
The largest number describable on an index card according to the rules of this contest, plus one
which uses 96 symbols. And this number would seem to be larger, by exactly one, of the number which we had previously argued must be the largest number that is possible to describe on an index card. Indeed, how are we able to write this description at all? We seem to have described a number, while following certain rules, that is strictly larger than any number which it is possible to describe while following those rules. Contradiction! This conundrum is known as Berry’s paradox, the paradox of “the smallest positive integer not definable in under eleven words.”
Thus, we can see that this formulation of the largest-number contest is really about the Berry paradox, which I shall leave you to ponder further on your own.
I concluded this part of my talk by discussing the fact that even when one doesn’t allow natural language descriptions, but stays close to a formal language, such as the formal language of arithmetic, then the contest ultimately wades into some difficult waters of mathematical logic. It is a mathematical theorem that there is no computable procedure that will correctly determine which of two descriptions, expressed in that formal language, describes the larger natural number. For example, even if we allow descriptions of the form, “the size of the smallest integer solution to this integer polynomial equation
For further reading on this topic, there are a number of online resources:
Googol plex bang stack hierarchy | Largest number contest on MathOverflow
Scott Aaronson on Big Numbers (related: succinctly naming big numbers)
Meanwhile, lets return to our actual contest, for which we collected a number of interesting submissions, on which I’ll comment below. Several students had appreciated the connection between the contest and Berry’s paradox.
 Your number is quite large, since we can surely describe an enormous number of digits of
Your number is quite large, since we can surely describe an enormous number of digits of
 Surely
Surely
 This is charming, and I’m sure that your girlfriend will be very happy to see this. Depending on the units we use to measure your affection, I find it very likely that this number is extremely large indeed, and perhaps you win the contest. (But in order to stay within the rules, we should pick the units so that your affection comes out exactly as a positive integer; in particular, if your affection is actually infinite, as you seem to indicate, then I am afraid that you would be disqualified.) One concern that I have, however, about your delightful entry—please correct me if I am wrong—is this: did you write at first about your affection for your “girlfriends” (plural), and then cross out the extra “s” in order to refer to only one girlfriend? And when you refer to your “girlfriend(s), which values at least
This is charming, and I’m sure that your girlfriend will be very happy to see this. Depending on the units we use to measure your affection, I find it very likely that this number is extremely large indeed, and perhaps you win the contest. (But in order to stay within the rules, we should pick the units so that your affection comes out exactly as a positive integer; in particular, if your affection is actually infinite, as you seem to indicate, then I am afraid that you would be disqualified.) One concern that I have, however, about your delightful entry—please correct me if I am wrong—is this: did you write at first about your affection for your “girlfriends” (plural), and then cross out the extra “s” in order to refer to only one girlfriend? And when you refer to your “girlfriend(s), which values at least
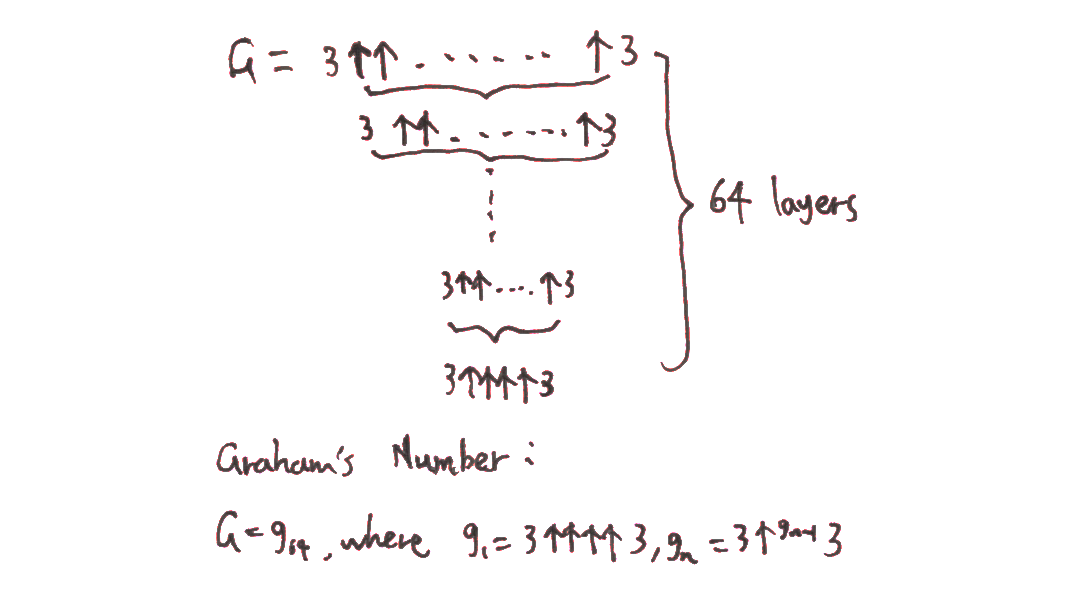 You’ve submitted Graham’s number, an extremely large number that is also popularly known as the largest definite number ever to be used in a published mathematical proof. This number is certainly in the upper vicinity of the numbers we discussed above, obtained by iterating the Knuth uparrow. It is much larger than anything we can easily write in the googol plex bang stack hierarchy. This is essentially in line with iterating the
You’ve submitted Graham’s number, an extremely large number that is also popularly known as the largest definite number ever to be used in a published mathematical proof. This number is certainly in the upper vicinity of the numbers we discussed above, obtained by iterating the Knuth uparrow. It is much larger than anything we can easily write in the googol plex bang stack hierarchy. This is essentially in line with iterating the
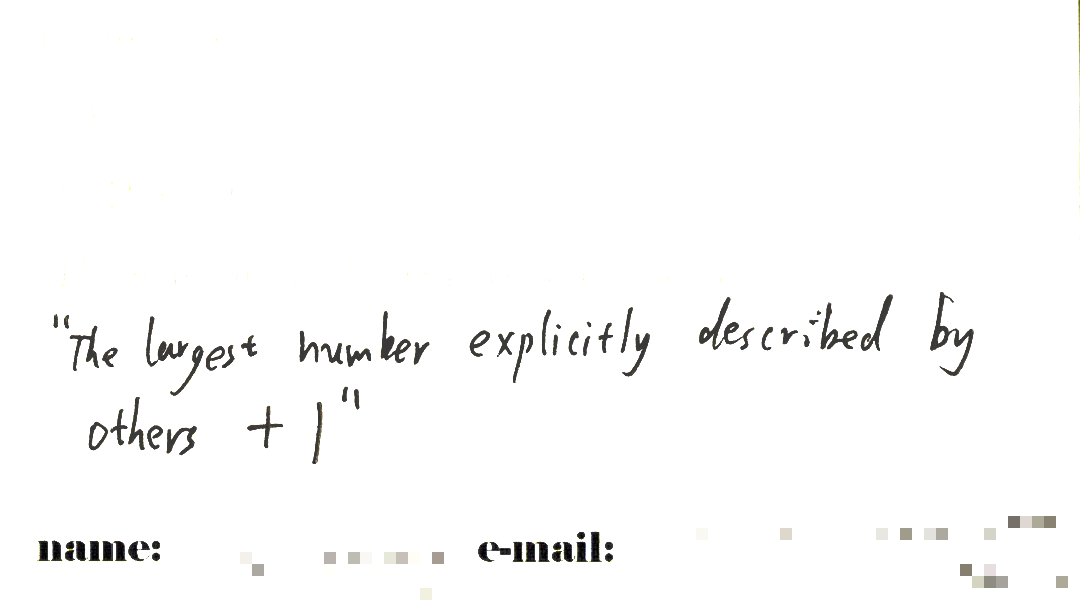 Your clever submission shows that you realize that it isn’t necessary to actually mention the largest possible number to describe, as we discussed in Berry’s paradox above, but it suffices rather to exceed only the largest actually occurring numbers that are described by others in the contest. What are we to do, however, when two people have this same clever idea? If either of them succeeds in describing a number, then it would seem that they both must succeed, but in this case, they must both have described numbers larger than the other. This is the same contradiction at the heart of Berry’s paradox. Another risky feature of this entry is that it presumes that some numbers were in fact described by others. How are we to interpret it if all other submissions are disqualified?
Your clever submission shows that you realize that it isn’t necessary to actually mention the largest possible number to describe, as we discussed in Berry’s paradox above, but it suffices rather to exceed only the largest actually occurring numbers that are described by others in the contest. What are we to do, however, when two people have this same clever idea? If either of them succeeds in describing a number, then it would seem that they both must succeed, but in this case, they must both have described numbers larger than the other. This is the same contradiction at the heart of Berry’s paradox. Another risky feature of this entry is that it presumes that some numbers were in fact described by others. How are we to interpret it if all other submissions are disqualified?
 Your description has the very nice feature that it avoids the self-reference needed in the previous description to refer to all the “other” entries (that is, all the entries that are not “this” one). It avoids the self-reference by speaking of “second-largest” entry, which of course will have to be the largest of the other entries, since this entry is to be one larger. Although it avoids self-reference, nevertheless this description is what would be called impredicative, because it quantifies over a class of objects (the collected entries) of which it is itself a member. Once one interprets things as you seem to intend, however, this entry appears to amount to essentially the same description as the previous entry. Thus, the problematic and paradoxical situation has now actually occurred, making it problematic to conclude that either of these entries has succeeded in describing a definite number. So how are we to resolve it?
Your description has the very nice feature that it avoids the self-reference needed in the previous description to refer to all the “other” entries (that is, all the entries that are not “this” one). It avoids the self-reference by speaking of “second-largest” entry, which of course will have to be the largest of the other entries, since this entry is to be one larger. Although it avoids self-reference, nevertheless this description is what would be called impredicative, because it quantifies over a class of objects (the collected entries) of which it is itself a member. Once one interprets things as you seem to intend, however, this entry appears to amount to essentially the same description as the previous entry. Thus, the problematic and paradoxical situation has now actually occurred, making it problematic to conclude that either of these entries has succeeded in describing a definite number. So how are we to resolve it?
 Your description is very clever, trying to have it both ways. Of course, every participant in the contest wants to win, but you also to win with a very low winning number, so that you can maximize the prize payout. With this submission, of course you hope that all other submissions might be disqualified, in which case you will win with the number 1, achieving the million dollar payout! In the case of our actual contest, however, there are other cards that are qualified, such as the Graham’s number submission, and so your submission seems to be in case 2, making it similar in effect to the previous submission. Like the previous two entries, this card is problematic when two or more players submit the same description. And indeed, even with the other descriptions submitted above, we are already placed into the paradoxical situation that if this card describes a number in its case 2, then it will be larger than some numbers that are larger than it.
Your description is very clever, trying to have it both ways. Of course, every participant in the contest wants to win, but you also to win with a very low winning number, so that you can maximize the prize payout. With this submission, of course you hope that all other submissions might be disqualified, in which case you will win with the number 1, achieving the million dollar payout! In the case of our actual contest, however, there are other cards that are qualified, such as the Graham’s number submission, and so your submission seems to be in case 2, making it similar in effect to the previous submission. Like the previous two entries, this card is problematic when two or more players submit the same description. And indeed, even with the other descriptions submitted above, we are already placed into the paradoxical situation that if this card describes a number in its case 2, then it will be larger than some numbers that are larger than it.
 Your submission is very ambitious, attempting both to win and to win the most money. (I take the description as the lower part of this card, and the upper note is a remark about it.) You seem to realize that there will be ties in the game, with multiple people submitting a winning entry. And indeed, if everyone had submitted this entry, then the winning number would indeed seem to be 1, which is the smallest number that would make them all be one of the members who win the game, so the million dollars would be split amongst that group. Some clumsy person, however, might submit a googol plex bang, however, which would bump up the value of this card to that same value, which although still winning, would win much less money. Your line of reasoning about rationality is very similar to the concept of superrationality defended by Douglas Hofstadter in the context of the prisoner’s dilemma. Perhaps one might also be tempted to say something like:
Your submission is very ambitious, attempting both to win and to win the most money. (I take the description as the lower part of this card, and the upper note is a remark about it.) You seem to realize that there will be ties in the game, with multiple people submitting a winning entry. And indeed, if everyone had submitted this entry, then the winning number would indeed seem to be 1, which is the smallest number that would make them all be one of the members who win the game, so the million dollars would be split amongst that group. Some clumsy person, however, might submit a googol plex bang, however, which would bump up the value of this card to that same value, which although still winning, would win much less money. Your line of reasoning about rationality is very similar to the concept of superrationality defended by Douglas Hofstadter in the context of the prisoner’s dilemma. Perhaps one might also be tempted to say something like:
the smallest number that makes me win, with the largest possible prize payout to me.
with the idea that you’d get a bigger prize solely for yourself if you avoided a tie situation by adding one more, so as to get the whole prize for yourself. But if this reasoning is correct, then one would seem to land again in the clutches of the Berry paradox.
To my readers: please make your submissions or comments below!

Pingback: Playful paradox with large numbers, infinity and logic, Shanghai, June 2013 | Joel David Hamkins
the googolth iterate of (maxi-min number of beta moves normalizing a lambda term of size at most N) from googol
—
I wanted to actually spell out “size” — I mean number of abstractions plus number of applications, so perhaps this should be disqualified for ambiguity.
Thanks very much for your entry in the contest! Could you kindly provide a link that explains the process more fully? I’d like to know how your number relates to some of the other numbers we’ve mentioned…
I’m afraid I don’t understand what you’re asking me; I was trying to pin-down a particular case of the Busy Beaver problem (without saying “Busy Beaver” as being vague), of course; but I don’t think I actually managed to do that. It seems obvious, though I daren’t presume to declare, that the number (if it were made precise) should be larger than anything one could describe an algorithm to calculate given the space constraints (such as, say g!, or an Ackerman) though of course other people could surely find more impressive short conventional numbers to use in place of “googol”. E.g., googol! still fits in the character limit (not counting spaces).
I see; thanks a lot!
Sorry, maybe I’m not smart enough (I’m new in computation theory and I study it only as an hobby), but the conclusion is that noone can win due to the Berry paradox?
Well, the Berry paradox is clearly a complicating factor, indicating that one must take control of the formal language in order to have a sensible contest. But then, the conclusion is that the contest is saturated (in the general case) with difficult decidability questions, because if the formal language is capable of handling even some simple purely mathematical descriptions (e.g. the smallest integer solution of such-and-such diophantine system), then the question of who wins will be computably undecidable. And worse, because it will also often be independent of whatever background theory one works in, the question of which description describes a larger number becomes very troublesome. Depending on one’s mathematical philosophy, there may simply be no fact of the matter as to which number is larger. For these reasons, I believe that once one takes the contest seriously, it becomes inherently problematic and paradoxical; the contest itself evaporates. Since in light of these issues one can no longer take it seriously, I view it instead merely as a fun context in which to discuss large numbers and these other troublesome issues.
I had seen this overall conclusion, but it is now much clearer. thanks
But I wonder if there exists a class of solutions (descriptions of positive integers) that makes possible the existence of a winner. What features should have this class?
If one severely limits the kinds of allowed descriptions, then the undecidability issues retreat, and one can compute a winner. In another sense, for any specific-size instance of the contest, then since there are only finitely many possible things to submit, the full decision problem (however one wants to decide it), will be a computably decidable question. The undecidability issues only arise in the general case, where one doesn’t know the size of the index card in advance. Or another way to say it: undecidibility arises for the question of whether there is a decision procedure that is uniform in the size of the index card. But meanwhile, the independence phenomenon can arise even for specific finite sizes of the contest. So one should pick a small enough index card or a limited enough language so that one can in fact have a definite answer for the comparison of any possible submissions.
If I could scan a card, it would contain these words:
The highest number whose intersection with the highest number contained on this card is the empty set.
Thanks for the submission! But if we understand the intersection of numbers as it is with the finite ordinals, and if you have indeed described a number, then I think it must be 0, since any other number has nonempty intersection with itself. Meanwhile, the rules specify that the entry must be positive. So I think either you haven’t described a number, or you haven’t followed the rules.
I see what you mean. I wasn’t being very clear. What I’m after is the number of elements actually contained on the card, considered by any means (the real numbers, the number of alphabetic characters and so on). Then use those same means to consider the elements not on the card, which must be larger, since the card is smaller than the universe, while the means of considering the elements on the card must have already existed in the universe in order for the elements on the card to have come to exist. Does that get me any further?
10↑⇑ googol is nowhere near the size of Graham’s #.
You state that it’s larger but you are incorrect.
In fact this 10^^^googol is less than g_2 in the sequence, g, in which g_64 = Graham’s number.
My submission to your challenge would be:
f_(zeta_nought)(3), where zeta_nought = supremum of (epsilon_nought, epsilon_(epsilon_nought), …), and epsilon_(n+1) = supremum(epsilon_n, epsilon_n^epsilon_n, …), and epsilon_nought = supremum of tetrations of omega, and omega = supremum of natural numbers.
then we define f_a(n) = f_a[n](n), for limit ordinals a, where a[n] is the nth element of the fundamental sequence for a.
and f_(k+1)(n) = f_k^n(n), where f^(i+1)(n) (the ‘i+1’th functional power of f) = f(f^i(n))
and f_0(n) = n+1
successive functions in the “f family” are diagonalizations of their respective previous function.
this utterly blows away anything that’s been submitted on this page or discussed by you, though i fear due to your inability to understand the vast difference between your 10 triple arrow googol and graham’s number that you won’t see this.
simple proof though, for the comparitively small limit ordinal, epsilon_nought, we have f_(epsilon nought)(2):
epsilon_nought = sup{w, w^w, …}
epsilon_nought[2] = w^w
w^w = sup{w^1, w^2, …}
w^w[2] = w^2
w^2 = sup{w*1, w*2, …}
w^2[s] = w*2
w*2 = sup{w+1, w+2, …}
w*2[2] = w+2
f_(w+2)(2) = f_(w+1)(f_(w+1)(2))
= f_(w+1)(f_w(f_w(2))) = f_(w+1)(f_8(8))
meanwhile Graham’s # < f_w^64(6) < f_w^64(64) = f_(w+1)(64) << f_(w+1)(f_8(8)), where << means something like "computationally vastly less than"
i've been verbose in my description, but as you can hopefully see, this is all easily unambiguously definable in 500 characters or less.
and if you don't understand limit ordinals (which I'm sure you don't) and insist on everything being finite, even though infinite ordinals evaluate perfectly well to finite values when their fundamental sequence is evaluated, let me give you something quick and simple that also surpasses anything mentioned on this page
a_0 = b_0 = 10
a_(n+1) = a_n ^^^…^^^ a_n, where there are a_n ^'s
b_(n+1) = a_(b_n)
b_10
even b_2 leaves graham's # in the dust
and b as a sequence dominates conway's chained arrow notation which dominates knuth's up arrow notation.
Thank you for your contest entry.
Regarding your initial remarks, I believe you are mistaken, and I stand by what I wrote, namely, that Graham’s number
My claim is not difficult to verify, since Graham’s number
I note that your
One must admit that it is a little funny that you expressed skepticism about my ability to understand limit ordinals, yet you messed up the definition of
Finally, let me add that I don’t really care for the tone of your comment. I think you will find that you get a better reception in mathematical communication if you treat people with polite respect. You mention my “inability to understand” some simple things and that you are sure that I “don’t understand limit ordinals,” but this is frankly ludicrous in light of the rest of the content of this website. Have you had a look at it?
For some reason, “↑⇑”, is what was pasted when I highlighted your triple up arrow. Even now as I’m highlighting it, it’s pasting the “↑⇑” again.
Later in the evening, upon more thought, I decided my submission would actually be far more powerful if my b_n was defined instead as such:
b_(n+1) = a_(a_(a_…._a_10, where there are b_n subscriptings of a.
I believe you are incorrect in stating that I didn’t completely define the limit ordinals, the fundamental sequences of which are required for my larger answer to be evaluated.
It is possible to trace the fundamental sequence (for arbitrary entries) of epsilon_(epsilon_0) all the way back down to omega, via the basic reduction methods I outlined.
Example:
e_(e_0) = sup{e_w, e_(w^w), e_(w^w^w),…}
I may be misunderstanding your criticism here but I believe I defined the ordinals sufficient for this small application.
I’m aware this is a relatively small ordinal and didn’t want to get into Feferman-Schütte, or the CK ordinal because their definition varies too much for my taste.
I would have gotten to w_1^CK eventually and probably even invoked Rayo to put the nail in the coffin of computability so to speak.
It looks like I did breeze over your notation too quickly though. I see you were indeed correct in your statement that the notation you employed quickly exceeds Graham’s number.
My tone ensured you would respond. And maybe you would have regardless. Reading your reply, in fact, I can say with almost certainty that you would have replied. But I wasn’t able to judge that at the time. It’s my usual way of engaging people and it works every time, always results in lively discussion in which both parties learn a lot, and keeps people on their toes :p
a_(a_(a_…._a_0*
When one defines a function
I’m glad that you agree my claim was correct.
Finally, in order to discourage your regrettable policy of engaging people by means of insults, which I think is a very bad one, I shan’t be replying any further.
Good day.
X#X, where X is the XKCD number (defined as the value of the Ackermann function with Graham’s number for both arguments), and the operator # is defined as follows:
We start with the table of hyper-operators, where each operator is the iteration N times of the operator above it.
0: Incrementation
1: Addition
2: Multiplication
3: Exponentiation
4: Tetration
Donald Knuth has defined an operator called the up-arrow, /|\, which is the Nth operation in the table above. We can use this to define a new table:
0: /|\
1. N /|\s
2. N groups of N /|\s
3. N groups of N groups of N/|\s
We can then define a new table using the same method, and so on. # is defined as the Xth number of the Xth table defined by this method.
As an aside, what if there was a contest, similar to this one to define an operator X that had the largest value of 3X3?
Thanks for your submission! Your move about iterating the previous operations is the same as my move from
So from the original submissions, we have a lower limit (Graham’s number) which is relatively easy to beat with the traditional (Graham’s number +1), however there are three more tricky submissions.
“The largest number explicitly described by others + 1”, I intend to not be explicit when describing my number, thereby not being noticed by this rule. Perhaps a set of numbers, all of which are sufficiently large but one is chosen at random by the reader will suffice to not be explicit about my entry. Each number in the set could be the same incremented by its position in the set
“Second largest of collected positive numbers plus one.” Well my answer was not collected, but I think that is perhaps a little facetious, however this number is clearly dominated by the “Second largest of collected positive numbers plus two”, so as long as that is actually the second largest number then those two rules can fight it out for second place, assuming neither of them actually makes it to first place. “The sum of the second and third place entries” would be sufficient to guarantee that, however it would be tied for first place with:
“The least number that makes me one of the members who win the game”. Now the only definition of “win” we have was the condition to be applied to the largest number, however the “..least number..” part is clearly a reference to winning the prize. Now given that there is no such number (given the Graham’s entry earlier) that is less than 100,000,000 (the largest possible number that can win a prize) and also large enough to win [a prize], there are no numbers that fit this criterion, so I believe it to not be a number. If we discount the prize aspect then we are simply looking for a number that “makes me one of the members who win the game”. Now clearly the implication is that there might be one or more numbers that are tied for first place, and by asking for the least number you are essentially guaranteeing that. If you are not tied for first place (..one of the members) then your number is not the least that will guarantee it. Since you are at most going to be first equal, you cannot actually win, since winning requires you to submit the largest number, not the equal largest. Agen therefore I am forced to conclude that this submission cannot define a number.
Therefore I would like to describe: “A set of numbers, with one to be chosen at random by the reader as be my entry, all of which are larger than the sum of second and third highest numbers submitted by others” and I hope someone else will submit the “Second largest of collective positive numbers plus two” to save me faking a second entry 🙂
Rayo^Rayo^Rayo(9!!)(9)(9)
with f^n being f iterated n times
and Rayo being the function described here : http://googology.wikia.com/wiki/Rayo%27s_function
How does this number compare?
(G1,000,000↑↑G1,000,000)↑↑(G1,000,000↑↑G1,000,000)
Using Knuth’s up-arrow notation.
Assuming that Graham’s Number = G64
I could explain it if necessary.
I’m fairly certain I could explain it on 1 side of a 3×5 index card.
Is there a world record for hand writing numbers in sequence beginning at one and going forward : 1, 2, 3, …..
Here is an entry: Let’s introduce chain notation, aka /#\. Chain notation has the following rules.
(# is rest of array)
1. /#,1\ = /#\
2. /a,b,c\ = a^(c)b
3. /#,y,z\ = /#,/#,y,z-1\
If we look at just these three rules, we can state our entry to be /googol,googol,googol,googol,googol\, which is much larger than Graham’s Number.
However, I can diagonalize on this by introducing (c)/a,b\.
Rules for Vulcanized Chain Notation:
1. (1)/#\=/#\
2. (n)/a,b\=(n-1)/#,b\ with a b’s
3. You solve for chain notation normally if it is not listed under these two rules.
Using these rules and the original chain notation rules, I proclaim (10^100)/10^100,10^100\. (2)/10,#\ already diagonalizes over /#\, and this does it a googol times.
The largest number, if any, that can be described on an average index card is “The number satisfying the description “The largest number, if any, that can be described on an index card.”