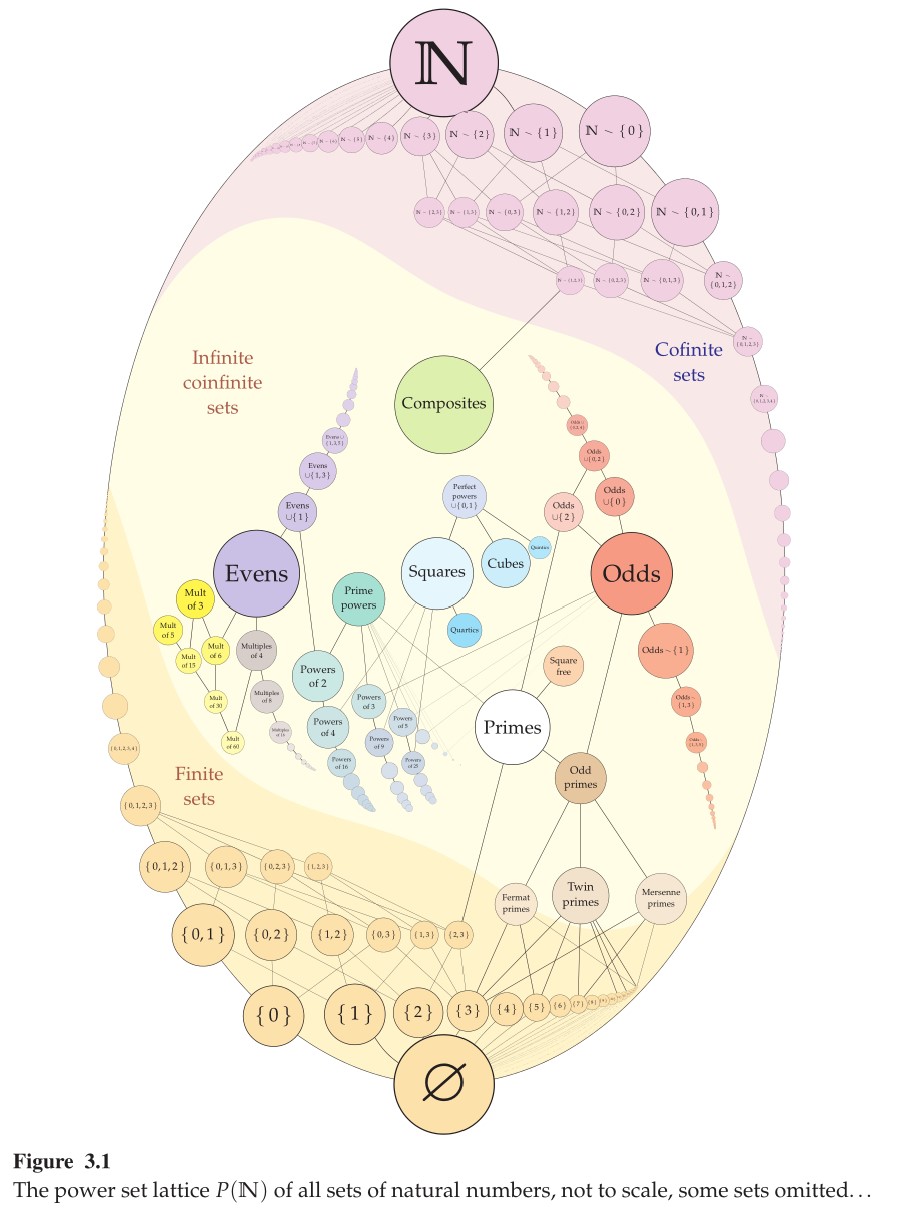
A theory admits quantifier-elimination when every assertion is logically equivalent over the theory to a quantifier-free assertion. This is quite a remarkable property when it occurs, because it reveals a severe limitation on the range of concepts that can be expressed in the theory—a quantifier-free assertion, after all, is able to express only combinations of the immediate atomic facts at hand. As a result, we are generally able to prove quantifier-elimination results for a theory only when we already have a profound understanding of it and its models, and the quantifier-elimination result itself usually leads quickly to classification of the definable objects, sets, and relations in the theory and its models. In this way, quantifier-elimination results often showcase our mastery over a particular theory and its models. So let us present a few quantifier-elimination results, exhibiting our expertise over some natural theories.
Endless dense linear orders
$\def\<#1>{\left\langle#1\right\rangle}\newcommand\Q{\mathbb{Q}}\newcommand\R{\mathbb{R}}\newcommand\N{\mathbb{N}}\newcommand\bottom{\mathord{\perp}}\newcommand{\Th}{\mathop{\rm Th}}\newcommand{\unaryminus}{-}\newcommand\Z{\mathbb{Z}}\newcommand\divides{\mid}$Consider first the theory of an endless dense linear order, such as the rational order $\<\Q,<>$. In light of Cantor’s theorems on the universality of the rational line and the categoricity theorem for countable endless dense linear orders, we already have a fairly deep understanding of this theory and this particular model.
Consider any two rational numbers $x,y$ in the structure $\<\Q,<>$. What can one say about them? Well, we can certainly make the atomic assertions that $x$ to a Boolean combination of these assertions.
Theorem. The theory of the rational order $\<\Q,<>$ admits elimination of quantifiers—every assertion $\varphi(x,\ldots)$ is logically equivalent in the rational order to a quantifier-free assertion.
Proof. To see this, observe simply by Cantor’s categoricity theorem for countable dense linear orders that any pair $x<y$ in $\Q$ is automorphic to any other such pair $x'<y’$, and similarly for pairs with $x=y$ or $y<x$. Consequently, $\varphi(x,y)$ either holds of all pairs with $x<y$ or of none of them, of all pairs with $x=y$ or none, and of all pairs with $y<x$ or none. The assertion $\varphi(x,y)$ is therefore equivalent to the disjunction of the three atomic relations for which it is realized, including $\top$ as the disjunction of all three atomic possibilities and $\bottom$ as the empty disjunction.
More generally, a similar observation applies to assertions $\varphi(x_1,\ldots,x_n)$ with more free variables. By Cantor’s theorem, every $n$-tuple of points in $\Q$ is automorphic with any other such $n$-tuple of points having the same atomic order relations. Therefore any assertion holding of one such $n$-tuple holds of all $n$-tuples with that same atomic type, and consequently every assertion $\varphi(x_1,\ldots,x_n)$ is logically equivalent in $\<\Q,<>$ to a disjunction of those combinations of atomic relations amongst the variables $x_1,\ldots,x_n$ for which it holds. In particular, every assertion is equivalent in $\<\Q,<>$ to a quantifier-free assertion. In short, the theory of this model $\Th(\<\Q,<>)$ admits elimination of quantifiers. $\Box$
What about other endless dense linear orders? The argument we have given so far is about the theory of this particular model $\<\Q,<>$. In fact, the theory of the rational order is exactly the theory of endless dense linear orders, because this theory is complete, which one can see as an immediate consequence of the categoricity result of Cantor’s theorem and the downward Löwenheim-Skolem theorem. In my book, I have not yet proved the Löwenheim-Skolem theorem at this stage, however, and so let me give a direct proof of quantifier-elimination in the theory of endless dense linear orders, from which we can also derive the completeness of this theory.
Theorem. In the theory of endless dense linear orders, every statement is logically equivalent to a quantifier-free statement.
Proof. To clarify, the quantifier-free statement will have the same free variables as the original assertion, provided we allow $\bottom$ and $\top$ as logical constants. We argue by induction on formulas. The claim is of course already true for the atomic formulas, and it is clearly preserved under Boolean connectives. So it suffices inductively to eliminate the quantifier from $\exists x\, \varphi(x,\ldots)$, where $\varphi$ is itself quantifier-free. We can place $\varphi$ in disjunctive normal form, a disjunction of conjunction clauses, where each conjunction clause is a conjunction of literals, that is, atomic or negated atomic assertions. Since the atomic assertions $x<y$, $x=y$ and $y<x$ are mutually exclusive and exhaustive, the negation of any one of them is equivalent to the disjunction of the other two. Thus we may eliminate any need for negation. By redistributing conjunction over disjunction as much as possible, we reduce to the case of $\exists x\,\varphi$, where $\varphi$ is in disjunctive normal form without any negation. The existential quantifier distributes over disjunction, and so we reduce to the case $\varphi$ is a conjunction of atomic assertions. We may eliminate any instance of $x=x$ or $y=y$, since these impose no requirement. We may assume that the variable $x$ occurs in each conjunct, since otherwise that conjunct commutes outside the quantifier. If $x=y$ occurs in $\varphi$ for some variable $y$ not identical to $x$, then the existential claim is equivalent to $\varphi(y,\ldots)$, that is, by replacing every instance of $x$ with $y$, and we have thus eliminated the quantifier. If $x<x$ occurs as one of the conjuncts, this is not satisfiable and so the assertion is equivalent to $\bottom$. Thus we have reduced to the case where $\varphi$ is a conjunction of assertions of the form $x<y_i$ and $z_j<x$. If only one type of these occurs, then the assertion $\exists x\,\varphi$ is outright provable in the theory by the endless assumption and thus equivalent to $\top$. Otherwise, both types $x<y_i$ and $z_j<x$ occur, and in this case the existence of an $x$ obeying this conjunction of assertions is equivalent over the theory of endless dense linear orders to the quantifier-free conjunction $\bigwedge_{i,j}z_j<y_i$, since there will be an $x$ between them in this case and only in this case. Thus, we have eliminated the quantifier $\exists x$, and so by induction every formula is equivalent over this theory to a quantifier-free formula. $\Box$
Corollary. The theory of endless dense linear orders is complete.
Proof. If $\sigma$ is any sentence in this theory, then by theorem above, it is logically equivalent to a Boolean combination of quantifier-free assertions with the same variables. Since $\sigma$ is a sentence and there are no quantifier-free atomic sentences except $\bottom$ and $\top$, it follows that $\sigma$ is equivalent over the theory to a Boolean combination of $\bottom$ or $\top$. All such sentences are equivalent either to $\bottom$ or $\top$, and thus either $\sigma$ is entailed by the theory or $\neg\sigma$ is, and so the theory is complete. $\Box$
Corollary. In any endless dense linear order, the definable sets (allowing parameters) are precisely the finite unions of intervals.
Proof. By intervals we mean a generalized concept allowing either open or closed endpoints, as well as rays, in any of the forms:
$$(a,b)\qquad [a,b]\qquad [a,b)\qquad (a,b]\qquad (a,\infty)\qquad [a,\infty)\qquad (\unaryminus\infty,b)\qquad (\unaryminus\infty,b]$$
Of course any such interval is definable, since $(a,b)$ is defined by $(a<x)\wedge(x<b)$, taking the endpoints $a$ and $b$ as parameters, and $(-\infty,b]$ is defined by $(x<b)\vee (x=b)$, and so on. Thus, finite unions of intervals are also definable by taking a disjunction.
Conversely, any putative definition $\varphi(x,y_1,\ldots,y_n)$ is equivalent to a Boolean combination of atomic assertions concerning $x$ and the parameters $y_i$. Thus, whenever it is true for some $x$ between, above, or below the parameters $y_i$, it will be true of all $x$ in that same interval, and so the set that is defined will be a finite union of intervals having the parameters $y_i$ as endpoints, with the intervals being open or closed depending on whether the parameters themselves satisfy the formula or not. $\Box$
Theory of successor
Let us next consider the theory of a successor function, as realized for example in the Dedekind model, $\<\N,S,0>$, where $S$ is the successor
function $Sn=n+1$. The theory has the following three axioms:
$$\forall x\, (Sx\neq 0)$$
$$\forall x,y\, (Sx=Sy\implies x=y)$$
$$\forall x\, \bigl(x\neq 0\implies \exists y\,(Sy=x)\bigr).$$
There are no cycles in the successor operation.
$$\forall x\, (x\neq Sx)$$
$$\forall x\, (x\neq SSx)$$
$$\forall x\, (x\neq SSSx)$$
$$\vdots$$
In the Dedekind model, every individual is definable, since $x=n$ just in case $x=SS\cdots S0$, where we have $n$ iterative applications of $S$. So this is a pointwise definable model, and hence also Leibnizian. Note the interplay between the $n$ of the object theory and $n$ of the metatheory in the claim that every individual is definable.
What definable subsets of the Dedekind model can we think of? Of course, we can define any particular finite set, since the numbers are definable as individuals. For example, we can define the set ${1,5,8}$ by saying, “either $x$ has the defining property of $1$ or it has the defining property of $5$ or it has the defining property of $8$.” Thus any finite set is definable, and by negating such a formula, we see also that any cofinite set—the complement of a finite set—is definable. Are there any other definable sets? For example, can we define the set of even numbers? How could we prove that we cannot? The Dedekind structure has no automorphisms, since all the individuals are definable, and so we cannot expect to use automorphism to show that the even numbers are not definable as a set. We need a deeper understanding of definability and truth in this structure.
Theorem. The theory of a successor function admits elimination of quantifiers—every assertion is equivalent in this theory to a quantifier-free assertion.
Proof. By induction on formulas. The claim is already true for atomic assertions, since they have no quantifiers, and quantifier-free assertions are clearly closed under the Boolean connectives. So it suffices by induction to eliminate the quantifier from assertions of the form $\exists x\, \varphi(x,\ldots)$, where $\varphi$ is quantifier free. We may place $\varphi$ in disjunctive normal form, and since the quantifier distributes over disjunction, we reduce to the case that $\varphi$ is a conjunction of atomic and negated atomic assertions. We may assume that $x$ appears in each atomic conjunct, since otherwise we may bring that conjunct outside the quantifier. We may furthermore assume that $x$ appears on only one side of each atomic clause, since otherwise the statement is either trivially true as with $SSx=SSx$ or $Sx\neq SSx$, or trivially false as with $Sx=SSx$. Consider for example:
$$\exists x\,\bigl[(SSSx=y)\wedge (SSy=SSSz)\wedge (SSSSSx=SSSw)\wedge{}$$
$$\hskip1in{}\wedge (Sx\neq SSSSw)\wedge (SSSSy\neq SSSSSz)\bigr]$$
We can remove duplicated $S$s occurring on both sides of an equation. If $x=S^ky$ appears, we can get rid of $x$ and replace all occurrences with $S^ky$. If $S^nx=y$ appears, can add $S$’s everywhere and then replace any occurrence of $S^nx$ with $y$. If only inequalities appear, then the statement is simply true.
For example, since the third clause in the formula above is equivalent to $SSx=w$, we may use that to omit any need to refer to $x$, and the formula overall is equivalent to
$$(Sw=y)\wedge (y=Sz)\wedge (w\neq SSSSSw)\wedge (y\neq Sz),$$ which has no quantifiers.
Since the method is completely general, we have proved that the theory of successor admits elimination of quantifiers. $\Box$
It follows that the definable sets in the Dedekind model $\<\N,S,0>$, using only the first-order language of this structure, are precisely the finite and cofinite sets.
Corollary. The definable sets in $\<\N,S,0>$ are precisely the finite and cofinite sets
Proof. This is because an atomic formula defines a finite set, and the collection of finite or cofinite sets is closed under negation and Boolean combinations. Since every formula is equivalent to a quantifier-free formula, it follows that every formula is a Boolean combination of atomic formulas, and hence defines a finite or cofinite set. $\Box$
In particular, the concepts of being even or being odd are not definable from the successor operation in $\<\N,S,0>$, since the set of even numbers is neither finite nor cofinite.
Corollary. The theory of a successor function is complete—it is the theory of the standard model $\<\N,S,0>$.
Proof. If $\sigma$ is a sentence in the language of successor, then by the quantifier-elimination theorem it is equivalent to a quantifier-free assertion in the language with the successor function $S$ and constant symbol $0$. But the only quantifier-free sentences in this language are Boolean combinations of equations of the form $S^n0=S^k0$. Since all such equations are settled by the theory, the sentence itself is settled by the theory, and so the theory is complete. $\Box$
We saw that the three axioms displayed on the previous page were true in the Dedekind model $\<\N,S,0>$. Are there any other models of these axioms? Yes, there are. For example, we can add another $\Z$-chain of successors on the side, as with $\N+\Z$ or $\N\sqcup\Z$, although we shall see that the order is not definable. What are the definable elements in the enlarged structure? Still $0$ and all its finite successors are definable as before. But no elements of the $\Z$-chains can be definable, because we may perform an automorphism of the structure that translates elements within the $\Z$-chain by a fixed amount.
Let me prove next that the theory implies the induction axiom schema.
Corollary. The theory of successor (the three axioms) implies the induction axiom schema in the language of successor, that is, the following assertion for any assertion $\varphi(x)$:
$$\left[\varphi(0)\wedge\bigl(\forall x\,\bigl(\varphi(x)\implies\varphi(Sx)\bigr)\right]\implies\forall x\,\varphi(x)$$
Proof. Consider the set defined by $\varphi(x)$. By the earlier corollary, it must be eventually periodic in the standard model $\<\N,S,0>$. But by the induction assumption stated in the theorem, it must hold of every number in the standard model. So the standard model thinks that $\forall x\,\varphi(x)$. But the theory of the standard model is the theory of successor, which is complete. So the theory of successor entails that $\varphi$ is universal, as desired. $\Box$
In other words, in the trivial theory of successor–the three axioms—we get the corresponding induction axiom for free.
Presburger arithmetic
Presburger arithmetic is the theory of addition on the natural numbers, that is, the theory of the structure $\<\N,+,0,1>$. The numbers $0$ and $1$ are actually definable here from addition alone, since $0$ is the unique additive identity, and $1$ is the only number $u$ that is not expressible as a sum $x+y$ with both $x\neq u$ and $y\neq u$. So we may view this model if desired as a definitional expansion of $\<\N,+>$, with addition only. The number $2$ is similarly definable as $1+1$, and indeed any number $n$ is definable as $1+\cdots+1$, with $n$ summands, and so this is a pointwise definable model and hence also Leibnizian.
What are the definable subsets? We can define the even numbers, of course, since $x$ is even if and only if $\exists y\,(y+y=x)$. We can similarly define congruence modulo $2$ by $x\equiv_2 y\iff \exists z\,\bigl[(z+z+x=y)\vee (z+z+y=x)\bigr]$. More generally, we can express the relation of congruence modulo $n$ for any fixed $n$ as follows:
$$x\equiv_n y\quad\text{ if and only if }\exists z\,\bigl[(\overbrace{z+\cdots+z}^n+x=y)\vee(\overbrace{z+\cdots+z}^n+y=x)\bigr].$$
What I claim is that this exhausts what is expressible.
Theorem. Presburger arithmetic in the definitional expansion with all congruence relations, that is, the theory of the structure
$$\<\N,+,0,1,\equiv_2,\equiv_3,\equiv_4,\ldots>$$
admits elimination of quantifiers. In particular, every assertion in the language of $\<\N,+,0,1>$ is equivalent to a quantifer-free assertion in the language with the congruence relations.
Proof. We consider Presburger arithmetic in the language with addition $+$, with all the congruence relations $\equiv_n$ for every $n\geq 2$, and the constants $0$ and $1$. We prove quantifier-elimination in this language by induction on formulas. As before the claim already holds for atomic assertions and is preserved by Boolean connectives. So it suffices to eliminate the quantifier from assertions of the form $\exists x\,\varphi(x,\ldots)$, where $\varphi$ is quantifier-free. By placing $\varphi$ into disjunctive normal form and distributing the quantifier over the disjunction, we may assume that $\varphi$ is a conjunction of atomic and negated atomic assertions. Note that negated congruences are equivalent to a disjunction of positive congruences, such as in the case:
$$x\not\equiv_4 y\quad\text{ if and only if }\quad (x+1\equiv_4y)\vee(x+1+1\equiv_4y)\vee (x+1+1+1\equiv_4 y).$$
We may therefore assume there are no negated congruences in $\varphi$. By canceling like terms on each side of an equation or congruence, we may assume that $x$ occurs on only one side. We may assume that $x$ occurs nontrivially in every conjunct of $\varphi$, since otherwise this conjunct commutes outside the quantifier. Since subtraction modulo $n$ is the same as adding $n-1$ times, we may also assume that all congruences occurring in $\varphi$ have the form $kx\equiv_n t$, where $kx$ denotes the syntactic expression $x+\cdots+x$ occurring in the formula, with $k$ summands, and $t$ is a term not involving the variable $x$. Thus, $\varphi$ is a conjunction of expressions each having the form $kx\equiv_n t$, $ax+r=s$, or $bx+u\neq v$, where $ax$ and $bx$ similarly denote the iterated sums $x+\cdots+x$ and $r,s,u,v$ are terms not involving $x$.
If indeed there is a conjunct of the equality form $ax+r=s$ occurring in $\varphi$, then we may omit the quantifier as follows. Namely, in order to fulfill the existence assertion, we know that $x$ will have to solve $ax+r=s$, and so in particular $r\equiv_a s$, which ensures the existence of such an $x$, but also in this case any inequality $bx+u\neq v$ can be equivalently expressed as $abx+au\neq av$, which since $ax+r=s$ is equivalent to $bs+au\neq av+br$, and this does does not involve $x$; similarly, any congruence $kx\equiv_n t$ is equivalent to $akx\equiv_{an}at$, which is equivalent to $s\equiv_{an} r+at$, which again does not involve $x$. Thus, when there is an equality involving $x$ present in $\varphi$, then we can use that fact to express the whole formula in an equivalent manner not involving $x$.
So we have reduced to the case $\exists x\,\varphi$, where $\varphi$ is a conjunction of inequalities $bs+u\neq v$ and congruences $kx\equiv_n t$. We can now ignore the inequalities, since if the congruence system has a solution, then it will have infinitely many solutions, and so there will be an $x$ solving any finitely given inequalities. So we may assume that $\varphi$ is simply a list of congruences of the form $kx\equiv_n t$, and the assertion is that this system of congruences has a solution. But there are only finitely many congruences mentioned, and so by working modulo the least common multiple of the bases that occur, there are only finitely many possible values for $x$ to be checked. And so we can simply replace $\varphi$ with a disjunction over these finitely many values $i$, replacing $x$ in each conjunction with $1+\cdots+1$, using $i$ copies of $1$, for each $i$ up to the least common multiples of the bases that arise in the congruences appearing in $\varphi$. If there is an $x$ solving the system, then one of these values of $i$ will work, and conversely.
So we have ultimately succeeded in expressing $\exists x\,\varphi$ in a quantifier-free manner, and so by induction every assertion in Presburger arithmetic is equivalent to a quantifier-free assertion in the language allowing addition, congruences, and the constants $0$ and $1$. $\Box$
Corollary. The definable sets in $\<\N,+,0,1>$ are exactly the eventually periodic sets.
Proof. Every periodic set is definable, since one can specify the set up to the period $p$, and then express the invariance modulo $p$. Any finite deviation from a definable set also is definable, since every individual number is definable. So every eventually period set is definable. Conversely, every definable set is defined by a quantifier-free assertion in the language of $\<\N,+,0,1,\equiv_2,\equiv_3,\equiv_4,\ldots>$. We may place the definition in disjunctive normal form, and again replace negated congruences with a disjunction of positive congruences. For large enough values of $x$, the equalities and inequalities appearing in the definition become irrelevant, and so the definition eventually agrees with a finite union of solutions of congruence systems. Every such system is periodic with a period at most the least common multiple of the bases of the congruences appearing in it. And so every definable set is eventually periodic, as desired. $\Box$
Corollary. Multiplication is not definable in $\<\N,+,0,1>$. Indeed, the squaring operation is not definable, and neither is the divisibility relation $p\divides q$.
Proof. If we could define multiplication, or even the squaring operation, then we would be able to define the set of perfect squares, but this is not eventually periodic. Similarly, if we could define the divides relation $p\divides q$, then we could define the set of prime numbers, which is not eventually periodic. $\Box$
Real-closed field
Let us lastly consider the ordered real field $\<\R,+,\cdot,0,1,<>$. I want to mention (without proof) that a deep theorem of Tarski shows that this structure admits elimination of quantifiers: every assertion is equivalent in this structure to a quantifier-free assertion. In fact all that is need is that this is a real-closed field, an ordered field in which every odd-degree polynomial has a root and every positive number has a square root.
We can begin to gain insight to this fact by reaching into the depths of our high-school education. Presented with an equation $ax^2+bx+c=0$ in the integers, we know by the quadratic formula that the solution is $x=\left(-b\pm\sqrt{b^2-4ac}\right)/2a$, and in particular, there is a solution in the real numbers if and only if $b^2-4ac\geq 0$, since otherwise a negative discriminant means the solution is a complex number. In other words,
$$\exists x\,(ax^2+bx+c=0)\quad\text{ if and only if }\quad b^2-4ac\geq 0.$$
The key point is that this an elimination of quantifiers result, since we have eliminated the quantifier $\exists x$.
Tarski’s theorem proves more generally that every assertion in the language of ordered fields is equivalent in real-closed fields to a quantifier-free assertion. Furthermore, there is a computable procedure to find the quantifier-free equivalent, as well as a computable procedure to determine the truth of any quantifier-free assertion in the theory of real-closed fields.
What I find incredible is that it follows from this that there is a computable procedure to determine the truth of any first-order assertion of Cartesian plane geometry, since all such assertions are expressible in the language of $\<\R,+,\cdot,0,1,<>$. Amazing! I view this as an incredible culmination of two thousand years of mathematical investigation: we now have an algorithm to determine by rote procedure the truth of any statement in Cartesian geometry. Meanwhile, a counterpoint is that the decision procedure, unfortunately, is not computationally feasible, however, since it takes more than exponential time, and it is a topic of research to investigate the computational running time of the best algorithms.