This brief unpublished note (11 pages) contains an overview of the Gödel fixed-point lemma, along with several generalizations and applications, written for use in the Week 3 lecture of the Graduate Philosophy of Logic seminar that I co-taught with Volker Halbach at Oxford in Hilary term 2021. The theme of the seminar was self-reference, truth, and consistency strengths, and in this lecture we discussed the nature of Gödel’s fixed-point lemma and generalizations, with various applications in logic.
Gödel’s fixed-point lemma An application to the Gödel incompleteness theorem
Finite self-referential schemes An application to nonindependent disjunctions of independent sentences
Gödel-Carnap fixed point lemma Deriving the double fixed-point lemma as a consequence An application to the provability version of Yablo’s paradox
Kleene recursion theorem An application involving computable numbers An application involving the universal algorithm An application to Quine programs and Ouroborous chains
Welcome to Cantor’s Ice Cream Shoppe! A huge choice of flavors—pile your cone high with as many scoops as you want!
Have two scoops, or three, four, or more! Why not infinitely many? Would you like 𝜔 many scoops, or 𝜔⋅2+5 many scoops? You can have any countable ordinal number of scoops on your cone.
And furthermore, after ordering your scoops, you can order more scoops to be placed on top—all I ask is that you let me know how many such extra orders you plan to make. Let’s simply proceed transfinitely. You can announce any countable ordinal 𝜂, which will be the number of successive orders you will make; each order is a countable ordinal number of ice cream scoops to be placed on top of whatever cone is being assembled.
In fact, I’ll even let you change your mind about 𝜂 as we proceed, so as to give you more orders to make a taller cone.
So the process is:
You pick a countable ordinal 𝜂, which is the number of orders you will make.
For each order, you can pick any countable ordinal number of scoops to be added to the top of your ice-cream cone.
After making your order, you can freely increase 𝜂 to any larger countable ordinal, giving you the chance to make as many additional orders as you like.
At each limit stage of the ordering process, the ice cream cone you are assembling has all the scoops you’ve ordered so far, and we set the current 𝜂 value to the supremum of the values you had chosen so far.
If at any stage, you’ve used up your 𝜂 many orders, then the process has completed, and I serve you your ice cream cone. Enjoy!
Question. Can you arrange to achieve uncountably many scoops on your cone?
Although at each stage we place only countably many ice cream scoops onto the cone, nevertheless we can keep giving ourselves extra stages, as many as we want, simply by increasing 𝜂. Can you describe a systematic process of increasing the number of steps that will enable you to make uncountably many orders? This would achieve an unountable ice cream cone.
What is your solution? Give it some thought before proceeding. My solution appears below.
Alas, I claim that at Cantor’s Ice Cream Shoppe you cannot make an ice cream cone with uncountably many scoops. Specifically, I claim that there will inevitably come a countable ordinal stage at which you have used up all your orders.
Suppose that you begin by ordering 𝛽0 many scoops, and setting a large value 𝜂0 for the number of orders you will make. You subsequently order 𝛽1 many additional scoops, and then 𝛽2 many on top of that, and so on. At each stage, you may also have increased the value of 𝜂0 to 𝜂1 and then 𝜂2 and so on. Probably all of these are enormous countable ordinals, making a huge ice cream cone.
At each stage 𝛼, provided 𝛼<𝜂𝛼, then you can make an order of 𝛽𝛼 many scoops on top of your cone, and increase 𝜂𝛼 to 𝜂𝛼+1, if desired, or keep it the same.
At a limit stage 𝜆, your cone has ∑𝛼<𝜆𝛽𝛼 many scoops, and we update the 𝜂 value to the supremum of your earlier declarations 𝜂𝜆=sup𝛼<𝜆𝜂𝛼.
What I claim now is that there will inevitably come a countable stage 𝜆 for which 𝜆=𝜂𝜆, meaning that you have used up all your orders with no possibility to further increase 𝜂. To see this, consider the sequence 𝜂0≤𝜂𝜂0≤𝜂𝜂𝜂0≤⋯ We can define the sequence recursively by 𝜆0=𝜂0 and 𝜆𝑛+1=𝜂𝜆𝑛. Let 𝜆=sup𝑛<𝜔𝜆𝑛, the limit of this sequence. This is a countable supremum of countable ordinals and hence countable. But notice that 𝜂𝜆=sup𝑛<𝜔𝜂𝜆𝑛=sup𝑛<𝜔𝜆𝑛+1=𝜆. That is, 𝜂𝜆=𝜆 itself, and so your orders have run out at 𝜆, with no possibility to add more scoops or to increase 𝜂. So your order process completed at a countable stage, and you have therefore altogether only a countable ordinal number of scoops of ice cream. I’m truly very sorry at your pitiable impoverishment.
I’d like to introduce and discuss the otherworldly cardinals, a large cardinal notion that frequently arises in set-theoretic analysis, but which until now doesn’t seem yet to have been given its own special name. So let us do so here.
I was put on to the topic by Jason Chen, a PhD student at UC Irvine working with Toby Meadows, who brought up the topic recently on Twitter:
Do these cardinals have special names: α's such that there is some β with V_α being an elementary substructure of V_β (so they form a proper subset of worldly cardinals); and a stratified version: α's such that there is some β, with V_α being a Σ_n-elementary substructure of V_β.
In response, I had suggested the otherworldly terminology, a play on the fact that the two cardinals will both be worldly, and so we have in essence two closely related worlds, looking alike. We discussed the best way to implement the terminology and its extensions. The main idea is the following:
Main Definition. An ordinal 𝜅 is otherworldly if 𝑉𝜅≺𝑉𝜆 for some ordinal 𝜆>𝜅. In this case, we say that 𝜅 is otherworldly to𝜆.
It is an interesting exercise to see that every otherworldly cardinal 𝜅 is in fact also worldly, which means 𝑉𝜅⊧ZFC, and from this it follows that 𝜅 is a strong limit cardinal and indeed a ℶ-fixed point and even a ℶ-hyperfixed point and more.
Theorem. Every otherworldly cardinal is also worldly.
Proof. Suppose that 𝜅 is otherworldly, so that 𝑉𝜅≺𝑉𝜆 for some ordinal 𝜆>𝜅. It follows that 𝜅 must in fact be a cardinal, since otherwise it would be the order type of a relation on a set in 𝑉𝜅, which would be isomorphic to an ordinal in 𝑉𝜆 but not in 𝑉𝜅. And since 𝜔 is not otherworldly, we see that 𝜅 must be an uncountable cardinal. Since 𝑉𝜅 is transitive, we get now easily that 𝑉𝜅 satisfies extensionality, regularity, union, pairing, power set, separation and infinity. The only axiom remaining is replacement. If 𝜑(𝑎,𝑏) obeys a functional relation in 𝑉𝜅 for all 𝑎∈𝐴, where 𝐴∈𝑉𝜅, then 𝑉𝜆 agrees with that, and also sees that the range is contained in 𝑉𝜅, which is a set in 𝑉𝜆. So 𝑉𝜅 agrees that the range is a set. So 𝑉𝜅 fulfills the replacement axiom. ◻
Corollary. A cardinal is otherworldly if and only if it is fully correct in a worldly cardinal.
Proof. Once you know that otherworldly cardinals are worldly, this amounts to a restatement of the definition. If 𝑉𝜅≺𝑉𝜆, then 𝜆 is worldly, and 𝑉𝜅 is correct in 𝑉𝜆. ◻
Let me prove next that whenever you have an otherworldly cardinal, then you will also have a lot of worldly cardinals, not just these two.
Theorem. Every otherworldly cardinal 𝜅 is a limit of worldly cardinals. What is more, every otherworldly cardinal is a limit of worldly cardinals having exactly the same first-order theory as 𝑉𝜅, and indeed, the same 𝛼-order theory for any particular 𝛼<𝜅.
Proof. If 𝑉𝜅≺𝑉𝜆, then 𝑉𝜆 can see that 𝜅 is worldly and has the theory 𝑇 that it does. So 𝑉𝜆 thinks, about 𝑇, that there is a cardinal whose rank initial segment has theory 𝑇. Thus, 𝑉𝜅 also thinks this. And we can find arbitrarily large 𝛿 up to 𝜅 such that 𝑉𝛿 has this same theory. This argument works whether one uses the first-order theory, or the second-order theory or indeed the 𝛼-order theory for any 𝛼<𝜅. ◻
Theorem. If 𝜅 is otherworldly, then for every ordinal 𝛼<𝜅 and natural number 𝑛, there is a cardinal 𝛿<𝜅 with 𝑉𝛿≺Σ𝑛𝑉𝜅 and the 𝛼-order theory of 𝑉𝛿 is the same as 𝑉𝜅.
Proof. One can do the same as above, since 𝑉𝜆 can see that 𝑉𝜅 has the 𝛼-order theory that it does, while also agreeing on Σ𝑛 truth with 𝑉𝜆, so 𝑉𝜅 will agree that there should be such a cardinal 𝛿<𝜅. ◻
Definition. We say that a cardinal is totally otherworldly, if it is otherworldly to arbitrarily large ordinals. It is otherworldly beyond 𝜃, if it is otherworldly to some ordinal larger than 𝜃. It is otherworldly up to 𝛿, if it is otherworldly to ordinals cofinal in 𝛿.
Theorem. Every inaccessible cardinal 𝛿 is a limit of otherworldly cardinals that are each otherworldly up to and to 𝛿.
Proof. If 𝛿 is inaccessible, then a simple Löwenheim-Skolem construction shows that 𝑉𝜅 is the union of a continuous elementary chain 𝑉𝜅0≺𝑉𝜅1≺⋯≺𝑉𝜅𝛼≺⋯≺𝑉𝜅 Each of the cardinals 𝜅𝛼 arising on this chain is otherworldly up to and to 𝛿. ◻
Theorem. Every totally otherworldly cardinal is Σ2 correct, meaning 𝑉𝜅≺Σ2𝑉. Consequently, every totally otherworldly cardinal is larger than the least measurable cardinal, if it exists, and larger than the least superstrong cardinal, if it exists, and larger than the least huge cardinal, if it exists.
Proof. Every Σ2 assertion is locally verifiable in the 𝑉𝛼 hierarchy, in that it is equivalent to an assertion of the form ∃𝜂𝑉𝜂⊧𝜓 (for more information, see my post about Local properties in set theory). Thus, every true Σ2 assertion is revealed inside any sufficiently large 𝑉𝜆, and so if 𝑉𝜅≺𝑉𝜆 for arbitrarily large 𝜆, then 𝑉𝜅 will agree on those truths. ◻
I was a little confused at first about how two totally otherwordly cardinals interact, but now everything is clear with this next result. (Thanks to Hanul Jeon for his helpful comment below.)
Theorem. If 𝜅<𝛿 are both totally otherworldly, then 𝜅 is otherworldly up to 𝛿, and hence totally otherworldly in 𝑉𝛿.
Proof. Since 𝛿 is totally otherworldly, it is Σ2 correct. Since for every 𝛼<𝛿 the cardinal 𝜅 is otherworldly beyond 𝛼, meaning 𝑉𝜅≺𝑉𝜆 for some 𝜆>𝛼, then since this is a Σ2 feature of 𝜅, it must already be true inside 𝑉𝛿. So such a 𝜆 can be found below 𝛿, and so 𝜅 is otherworldly up to 𝛿. ◻
Theorem. If 𝜅 is totally otherworldly, then 𝜅 is a limit of otherworldly cardinals, and indeed, a limit of otherworldly cardinals having the same theory as 𝑉𝜅.
Proof. Assume 𝜅 is totally otherworldly, let 𝑇 be the theory of 𝑉𝜅, and consider any 𝛼<𝜅. Since there is an otherworldly cardinal above 𝛼 with theory 𝑇, namely 𝜅, and because this is a Σ2 fact about 𝛼 and 𝑇, it follows that there must be such a cardinal above 𝛼 inside 𝑉𝜅. So 𝜅 is a limit of otherworldly cardinals with the same theory as 𝑉𝜅. ◻
The results above show that the consistency strength of the hypotheses are ordered as follows, with strict increases in consistency strength as you go up (assuming consistency):
ZFC + there is an inaccessible cardinal
ZFC + there is a proper class of totally otherworldly cardinals
ZFC + there is a totally otherworldly cardinal
ZFC + there is a proper class of otherworldly cardinals
ZFC + there is an otherworldly cardinal
ZFC + there is a proper class of worldly cardinals
ZFC + there is a worldly cardinal
ZFC + there is a transitive model of ZFC
ZFC + Con(ZFC)
ZFC
We might consider the natural strengthenings of otherworldliness, where one wants 𝑉𝜅≺𝑉𝜆 where 𝜆 is itself otherworldly. That is, 𝜅 is the beginning of an elementary chain of three models, not just two. This is different from having merely that 𝑉𝜅≺𝑉𝜆 and 𝑉𝜅≺𝑉𝜂 for some 𝜂>𝜆, because perhaps 𝑉𝜆 is not elementary in 𝑉𝜂, even though 𝑉𝜅 is. Extending successively is a more demanding requirement.
One then naturally wants longer and longer chains, and ultimately we find ourselves considering various notions of rank in the rank elementary forest, which is the relation 𝜅⪯𝜆⟺𝑉𝜅≺𝑉𝜆. The otherworldly cardinals are simply the non-maximal nodes in this order, while it will be interesting to consider the nodes that can be extended to longer elementary chains.
Consider the real numbers ℝ and the complex numbers ℂ and the question of whether these structures are interpretable in one another as fields.
What does it mean to interpret one mathematical structure in another? It means to provide a definable copy of the first structure in the second, by providing a definable domain of 𝑘-tuples (not necessarily just a domain of points) and definable interpretations of the atomic operations and relations, as well as a definable equivalence relation, a congruence with respect to the operations and relations, such that the first structure is isomorphic to the quotient of this definable structure by that equivalent relation. All these definitions should be expressible in the language of the host structure.
One may proceed recursively to translate any assertion in the language of the interpreted structure into the language of the host structure, thereby enabling a complete discussion of the first structure purely in the language of the second.
For an example, we can define a copy of the integer ring ⟨ℤ,+,⋅⟩ inside the semi-ring of natural numbers ⟨ℕ,+,⋅⟩ by considering every integer as the equivalence class of a pair of natural numbers (𝑛,𝑚) under the same-difference relation, by which (𝑛,𝑚)≡(𝑢,𝑣)⟺𝑛−𝑚=𝑢−𝑣⟺𝑛+𝑣=𝑢+𝑚. Integer addition and multiplication can be defined on these pairs, well-defined with respect to same difference, and so we have interpreted the integers in the natural numbers.
Similarly, the rational field ℚ can be interpreted in the integers as the quotient field, whose elements can be thought of as integer pairs (𝑝,𝑞) written more conveniently as fractions 𝑝𝑞, where 𝑞≠0, considered under the same-ratio relation 𝑝𝑞≡𝑟𝑠⟺𝑝𝑠=𝑟𝑞. The field structure is now easy to define on these pairs by the familiar fractional arithmetic, which is well-defined with respect to that equivalence. Thus, we have provided a definable copy of the rational numbers inside the integers, an interpretation of ℚ in ℤ.
The complex field ℂ is of course interpretable in the real field ℝ by considering the complex number 𝑎+𝑏𝑖 as represented by the real number pair (𝑎,𝑏), and defining the operations on these pairs in a way that obeys the expected complex arithmetic.
(𝑎,𝑏)+(𝑐,𝑑)=(𝑎+𝑐,𝑏+𝑑)(𝑎,𝑏)⋅(𝑐,𝑑)=(𝑎𝑐−𝑏𝑑,𝑎𝑑+𝑏𝑐)
Thus, we interpret the complex number field ℂ inside the real field ℝ.
Question. What about an interpretation in the converse direction? Can we interpret ℝ in ℂ?
Although of course the real numbers can be viewed as a subfield of the complex numbers ℝ⊂ℂ,this by itself doesn’t constitute an interpretation, unless the submodel is definable. And in fact, ℝ is not a definable subset of ℂ. There is no purely field-theoretic property 𝜑(𝑥), expressible in the language of fields, that holds in ℂ of all and only the real numbers 𝑥. But more: not only is ℝ not definable in ℂ as a subfield, we cannot even define a copy of ℝ in ℂ in the language of fields. We cannot interpret ℝ in ℂ in the language of fields.
Theorem. As fields, the real numbers ℝ are not interpretable in the complex numbers ℂ.
We can of course interpret the real numbers ℝ in a structure slightly expanding ℂ beyond its field structure. For example, if we consider not merely ⟨ℂ,+,⋅⟩ but add the conjugation operation ⟨ℂ,+,⋅,𝑧↦¯𝑧⟩, then we can identify the reals as the fixed-points of conjugation 𝑧=¯𝑧. Or if we add the real-part or imaginary-part operators, making the coordinate structure of the complex plane available, then we can of course define the real numbers in ℂ as those complex numbers with no imaginary part. The point of the theorem is that in the pure language of fields, we cannot define the real subfield nor can we even define a copy of the real numbers in ℂ as any kind of definable quotient structure.
The theorem is well-known to model theorists, a standard observation, and model theorists often like to prove it using some sophisticated methods, such as stability theory. The main issue from that point of view is that the order in the real numbers is definable from the real field structure, but the theory of algebraically closed fields is too stable to allow it to define an order like that.
But I would like to give a comparatively elementary proof of the theorem, which doesn’t require knowledge of stability theory. After a conversation this past weekend with Jonathan Pila, Boris Zilber and Alex Wilkie over lunch and coffee breaks at the Robin Gandy conference, here is such an elementary proof, based only on knowledge concerning the enormous number of automorphisms of ℂ, a consequence of the categoricity of the complex field, which itself follows from the fact that algebraically closed fields of a given characteristic are determined by their transcedence degree over their prime subfield. It follows that any two transcendental elements of ℂ are automorphic images of one another, and indeed, for any element 𝑧∈ℂ any two complex numbers transcendental over ℚ(𝑧) are automorphic in ℂ by an automorphism fixing 𝑧.
Proof of the theorem. Suppose that we could interpret the real field ℝ inside the complex field ℂ. So we would define a domain of 𝑘-tuples 𝑅⊆ℂ𝑘 with an equivalence relation ≃ on it, and operations of addition and multiplication on the equivalence classes, such that the real field was isomorphic to the resulting quotient structure 𝑅/≃. There is absolutely no requirement that this structure is a submodel of ℂ in any sense, although that would of course be allowed if possible. The + and × of the definable copy of ℝ in ℂ might be totally strange new operations defined on those equivalence classes. The definitions altogether may involve finitely many parameters ⃗𝑝=(𝑝1,…,𝑝𝑛), which we now fix.
As we mentioned, the complex number field ℂ has an enormous number of automorphisms, and indeed, any two 𝑘-tuples ⃗𝑥 and ⃗𝑦 that exhibit the same algebraic equations over ℚ(⃗𝑝) will be automorphic by an automorphism fixing ⃗𝑝. In particular, this means that there are only countably many isomorphism orbits of the 𝑘-tuples of ℂ. Since there are uncountably many real numbers, this means that there must be two ≃-inequivalent 𝑘-tuples in the domain 𝑅 that are automorphic images in ℂ, by an automorphism 𝜋:ℂ→ℂ fixing the parameters ⃗𝑝. Since 𝜋 fixes the parameters of the definition, it will take 𝑅 to 𝑅 and it will respect the equivalence relation and the definition of the addition and multiplication on 𝑅/≃. Therefore, 𝜋 will induce an automorphism of the real field ℝ, which will be nontrivial precisely because 𝜋 took an element of one ≃-equivalence class to another.
The proof is now completed by the observation that the real field ⟨ℝ,+,⋅⟩ is rigid; it has no nontrivial automorphisms. This is because the order is definable (the positive numbers are precisely the nonzero squares) and the individual rational numbers must be fixed by any automorphism and then every real number is determined by its cut in the rationals. So there can be no nontrivial automorphism of ℝ, and we have a contradiction. So ℝ is not interpretable in ℂ. ◻
Let me introduce to you the topic of modal model theory, injecting some ideas from modal logic into the traditional subject of model theory in mathematical logic.
For example, we may consider the class of all models of some first-order theory, such as the class of all graphs, or the class of all groups, or all fields or what have you. In general, we have Mod(𝑇), where 𝑇 is a first-order theory in some language 𝐿.
We may consider Mod(𝑇) as a potentialist system, a Kripke model of possible worlds, where each model accesses the larger models, of which it is a submodel. So ◊𝜑 is true at a model 𝑀, if there is a larger model 𝑁 in which 𝜑 holds, and ◻𝜑 is true at 𝑀, if 𝜑 holds in all larger models.
In this way, we enlarge the language 𝐿 to include these modal operators. Let ◊(𝐿) be the language obtained by closing 𝐿 under the modal operators and Boolean connectives; and let 𝐿◊ also close under quantification. The difference is whether a modal operator falls under the scope of a quantifier.
Recently, in a collaborative project with Wojciech Aleksander Wołoszyn, we made some progress, which I’d like to explain. (We also have many further results, concerning the potentialist validities of various natural instances of Mod(𝑇), but those will wait for another post.)
Theorem. If models 𝑀 and 𝑁 are elementarily equivalent, that is, if they have the same theory in the language of 𝐿, then they also have the same theory in the modal language ◊(𝐿).
Proof. We show that whenever 𝑀≡𝑁 in the language of 𝐿, then 𝑀⊧𝜑⟺𝑁⊧𝜑 for sentences 𝜑 in the modal language ◊(𝐿), by induction on 𝜑.
Of course, by assumption the statement is true for sentences 𝜑 in the base language 𝐿. And the property is clearly preserved by Boolean combinations. What remains is the modal case. Suppose that 𝑀≡𝑁 and 𝑀⊧◊𝜑. So there is some extension model 𝑀⊂𝑊⊧𝜑.
Since 𝑀≡𝑁, it follows by the Keisler-Shelah theorem that 𝑀 and 𝑁 have isomorphic ultrapowers ∏𝜇𝑀≅∏𝜇𝑁, for some ultrafilter 𝜇. It is easy to see that isomorphic structures satisfy exactly the same modal assertions in the class of all models of a theory. Since 𝑀⊂𝑊, it follows that the ultrapower of 𝑀 is extended to (a copy of) the ultrapower of 𝑊, and so ∏𝜇𝑀⊧◊𝜑, and therefore also ∏𝜇𝑁⊧◊𝜑. From this, since 𝑁 embeds into its ultrapower ∏𝜇𝑁, it follows also that 𝑁⊧◊𝜑, as desired. ◻
Corollary. If one model elementarily embeds into another 𝑀≺𝑁, in the language 𝐿 of these structures, then this embedding is also elementary in the language ◊(𝐿).
Proof. To say 𝑀≺𝑁 in language 𝐿 is the same as saying that 𝑀≡𝑁 in the language 𝐿𝑀, where we have added constants for every element of 𝑀, and interpreted these constants in 𝑁 via the embedding. Thus, by the theorem, it follows that 𝑀≡𝑁 in the language ◊(𝐿𝑀), as desired. ◻
For example, every model 𝑀 is elementarily embedding into its ultrapowers ∏𝜇𝑀, in the language ◊(𝐿).
We’d like to point out next that these results do not extend to elementary equivalence in the full modal language 𝐿◊.
For a counterexample, let’s work in the class of all simple graphs, in the language with a binary predicate for the edge relation. (We’ll have no parallel edges, and no self-edges.) So the accessibility relation here is the induced subgraph relation.
Lemma. The 2-colorability of a graph is expressible in ◊(𝐿). Similarly for 𝑘-colorability for any finite 𝑘.
Proof. A graph is 2-colorable if we can partition its vertices into two sets, such that a vertex is in one set if and only if all its neighbors are in the other set. This can be effectively coded by adding two new vertices, call them red and blue, such that every node (other than red and blue) is connected to exactly one of these two points, and a vertex is connected to red if and only if all its neighbors are connected to blue, and vice versa. If the graph is 2-colorable, then there is an extension realizing this statement, and if there is an extension realizing the statement, then (even if more than two points were added) the original graph must be 2-colorable. ◻
A slightly more refined observation is that for any vertex 𝑥 in a graph, we can express the assertion, “the component of 𝑥 is 2-colorable” by a formula in the language ◊(𝐿). We simply make the same kind of assertion, but drop the requirement that every node gets a color, and insist only that 𝑥 gets a color and the coloring extends from a node to any neighbor of the node, thereby ensuring the full connected component will be colored.
Theorem. There are two graphs that are elementary equivalent in the language 𝐿 of graph theory, and hence also in the language ◊(𝐿), but they are not elementarily equivalent in the full modal language 𝐿◊.
Proof. Let 𝑀 be a graph consisting of disjoint copies of a 3-cycle, a 5-cycle, a 7-cycle, and so on, with one copy of every odd-length cycle. Let 𝑀∗ be an ultrapower of 𝑀 by a nonprincipal ultrafilter.
Thus, 𝑀∗ will continue to have one 3-cycle, one 5-cycle, one 7-cycle and on on, for all the finite odd-length cycles, but then 𝑀∗ will have what it thinks are non-standard odd-length cycles, except that it cannot formulate the concept of “odd”. What it actually has are a bunch of ℤ-chains.
In particular, 𝑀∗ thinks that there is an 𝑥 whose component is 2-colorable, since a ℤ-chain is 2-colorable.
But 𝑀 does not think that there is an 𝑥 whose component is 2-colorable, because an odd-length finite cycle is not 2-colorable. ◻.
Since we used an ultrapower, the same example also shows that the corollary above does not generalize to the full modal language. That is, we have 𝑀 embedding elementarily into its ultrapower 𝑀∗, but it is not elementary in the language 𝐿◊.
Let us finally notice that the Łoś theorem for ultraproducts fails even in the weaker modal language ◊(𝐿).
Theorem. There are models 𝑀𝑖 for 𝑖∈ℕ and a sentence 𝜑 in the language of these models, such that every nonprincipal ultraproduct ∏𝜇𝑀𝑖 satisfies ◊𝜑, but no 𝑀𝑖 satisfies ◊𝜑. .
Proof. In the class of all graphs, using the language of graph theory, let the 𝑀𝑖 be all the odd-length cycles. The ultraproduct ∏𝜇𝑀𝑖 consists entirely of ℤ-chains. In particular, the ultraproduct graph is 2-colorable, but none of the 𝑀𝑖 are 2-colorable. ◻
I saw the following image on Twitter and Reddit, an image suggesting an entire class of infinitary analogues of the game Connect-Four. What fun! Let’s figure it out!
I’m not sure to whom the image or the idea is due. Please comment if you have information. (See comments below for current information.)
Update: Please read my essay Infinite Connect Four for my current thinking on this topic, which grew out of this blog post, but the new ideas in that essay give ultimately a far more satisfactory analysis.
The rules will naturally generalize those in Connect-Four. Namely, starting from an empty board, the players take turns placing their coins into the 𝜔×4 grid. When a coin is placed in a column, it falls down to occupy the lowest available cell. Let us assume for now that the game proceeds for 𝜔 many moves, whether or not the board becomes full, and the goal is to make a connected sequence in a row of 𝜔 many coins of your color (you don’t have to fill the whole row, but rather a connected infinite segment of it suffices). A draw occurs when neither or both players achieve their goals.
In the 𝜔×6 version of the game that is shown, and indeed in the 𝜔×𝑛 version for any finite 𝑛, I claim that neither player can force a win; both players have drawing strategies.
Theorem. In the game Connect-𝜔 on a board of size 𝜔×𝑛, where 𝑛 is finite, neither player has a winning strategy; both players have drawing strategies.
Proof. For a concrete way to see this, observe that either player can ensure that there are infinitely many of their coins on the bottom row: they simply place a coin into some far-out empty column. This blocks a win for the opponent on the bottom row. Next, observe that neither player can afford to follow the strategy of always answering those moves on top, since this would lead to a draw, with a mostly empty board. Thus, it must happen that infinitely often we are able to place a coin onto the second row. This blocks a win for the opponent on the second row. And so on. In this way, either players can achieve infinitely many of their coins on each row, thereby blocking any row as a win for their opponent. So both players have drawing strategies. ◻
Let me point out that on a board of size 𝜔×𝑛, where 𝑛 is odd, we can also make this conclusion by a strategy-stealing argument. Specifically, I argue first that the first player can have no winning strategy. Suppose 𝜎 is a winning strategy for the first player on the 𝜔×𝑛 board, with 𝑛 odd, and let us describe a strategy for the second player. After the first move, the second player mentally ignores a finite left-initial segment of the playing board, which includes that first move and with a odd number of cells altogether in it (and hence an even number of empty cells remaining); the second player will now aim to win on the now-empty right-side of the board, by playing as though playing first in a new game, using strategy 𝜎. If the first player should ever happen to play on the ignored left side of the board, then the second player can answer somewhere there (it doesn’t matter where). In this way, the second player plays with 𝜎 as though he is the first player, and so 𝜎 cannot be winning for the first player, since in this way the second player would win in this stolen manner.
Similarly, let us argue by strategy-stealing that the second player cannot have a winning strategy on the board 𝜔×𝑛 for odd finite 𝑛. Suppose that 𝜏 is a winning strategy for the second player on such a board. Let the first player always play at first in the left-most column. Because 𝑛 is odd, the second player will eventually have to play first in the second or later columns, leaving an even number of empty cells in the first column (perhaps zero). At this point, the first player can play as though he was the second player on the right-side board containing only that fresh move. If the opponent plays again to the left, then our player can also play in that region (since there were an even number of empty cells). Thus, the first player can steal the strategy 𝜏, and so it cannot be winning for the second player.
I am unsure about how to implement the strategy stealing arguments when 𝑛 is even. I shall give this more thought. In any case, the theorem for this case was already proved directly by the initial concrete argument, and in this sense we do not actually need the strategy stealing argument for this case.
Meanwhile, it is natural also to consider the 𝑛×𝜔 version of the game, which has only finitely many columns, each infinite. The players aim to get a sequence of 𝜔-many coins in a column. This is clearly impossible, as the opponent can prevent a win by always playing atop the most recent move. Thus:
Theorem. In the game Connect-𝜔 on a board of size 𝑛×𝜔, where 𝑛 is finite, neither player has a winning strategy; both players have drawing strategies.
Perhaps the most natural variation of the game, however, occurs with a board of size 𝜔×𝜔. In this version, like the original Connect-Four, a player can win by either making a connected row of 𝜔 many coins, or a connected column or a connected diagonal of 𝜔 many coins. Note that we orient the 𝜔 size column upwards, so that there is no top cell, but rather, one plays by selecting a not-yet-filled column and then occupying the lowest available cell in that column.
Theorem. In the game Connect-𝜔 on a board of size 𝜔×𝜔, neither player has a winning strategy. Both players have drawing strategies.
Proof. Consider the strategy-stealing arguments. If the first player has a winning strategy 𝜎, then let us describe a strategy for the second player. After the first move, the second player will ignore finitely many columns at the left, including that first actual move, aiming to play on the empty right-side of the board as though the first player using stolen strategy 𝜎 (but with colors swapped). This will work fine, as long as the first player also plays on that part of the board. Whenever the first player plays on the ignored left-most part, simply respond by playing atop. This prevents a win in that part of the part, and so the second player will win on the right-side by pretending to be first there. So there can be no such winning strategy 𝜎 for the first player.
If the second player has a winning strategy 𝜏, then as before let the first player always play in the first column, until 𝜏 directs the second player to play in another column, which must eventually happen if 𝜏 is winning. At that moment, the first player can pretend to be second on the subboard omitting the first column. So 𝜏 cannot have been winning after all for the second player. ◻
In the analysis above, I was considering the game that proceeded in time 𝜔, with 𝜔 many moves. But such a play of the game may not actually have filled the board completely. So it is natural to consider a version of the game where the players continue to play transfinitely, if the board is not yet full.
So let us consider now the transfinite-play version of the game, where play proceeds transfinitely through the ordinals, until either the board is filled or one of the players has achieved the winning goal. Let us assume that the first player also plays first at limit stages, at 𝜔 and 𝜔⋅2 and 𝜔2, and so on, if game play should happen to proceed for that long.
The concrete arguments that I gave above continue to work for the transfinite-play game on the boards of size 𝜔×𝑛 and 𝑛×𝜔.
Theorem. In the transfinite-play version of Connect-𝜔 on boards of size 𝜔×𝑛 or 𝑛×𝜔, where 𝑛 is finite, neither player can have a winning strategy. Indeed, both players can force a draw while also filling the board in 𝜔 moves.
Proof. It is clear that on the 𝑛×𝜔 board, either player can force each column to have infinitely many coins of their color, and this fills the board, while also preventing a win for the opponent, as desired.
On the 𝜔×𝑛 board, consider a variation of the strategy I described above. I shall simply always play in the first available empty column, thereby placing my coin on the bottom row, until the opponent also plays in a fresh column. At that moment, I shall play atop his coin, thereby placing another coin in the second row; immediately after this, I also play subsequently in the left-most available column (so as to force the board to be filled). I then continue playing in the bottom row, until the opponent also does, which she must, and then I can add another coin to the second row and so on. By always playing the first-available second-row slot with all-empty second rows to the right, I can ensure that the opponent will eventually also make a second-row play (since otherwise I will have a winning condition on the second row), and at such a moment, I can also make a third-row play. By continuing in this way, I am able to place infinitely many coins on each row, while also forcing that the board becomes filled. ◻
Unfortunately, the transfinite-play game seems to break the strategy-stealing arguments, since the play is not symmetric for the players, as the first player plays first at limit stages.
Nevertheless, following some ideas of Timothy Gowers in the comments below, let me show that the second player has a drawing strategy.
Theorem. In the transfinite-play version of Connect-𝜔 on a board of size 𝜔×𝜔, the second player has a drawing strategy.
Proof. We shall arrange that the second player will block all possible winning configurations for the first player, or to have column wins for each player. To block all row wins, the second player will arrange to occupy infinitely many cells in each row; to block all diagonal wins, the second player will aim to occupy infinitely many cells on each possible diagonal; and to block the column wins, the second player will aim either to have infinitely many cells on each column or to copy a winning column of the opponent on another column.
To achieve these things, we simply play as follows. Take the columns in successive groups of three. On the first column in each block of three, that is on the columns indexed 3𝑚, the second player will always answer a move by the first player on this column. In this way, the second player occupies every other cell on these columns—all at the same height. This will block all diagonal wins, because every diagonal winning configuration will need to go through such a cell.
On the remaining two columns in each group of three, columns 3𝑚+1 and 3𝑚+2, let the second player simply copy moves of the opponent on one of these columns by playing on the other. These moves will therefore be opposite colors, but at the same height. In this way, the second player ensures that he has infinitely many coins on each row, blocking the row wins. And also, this strategy ensures that in these two columns, at any limit stage, either neither player has achieved a winning configuration or both have.
Thus, we have produced a drawing strategy for the second player. ◻
Thus, there is no advantage to going first. What remains is to determine if the first player also has a drawing strategy, or whether the second player can actually force a win.
Gowers explains in the comments below also how to achieve such a copying mechanism to work on a diagonal, instead of just on a column.
I find it also fascinating to consider the natural generalizations of the game to larger ordinals. We may consider the game of Connect-𝛼 on a board of size 𝜅×𝜆, for any ordinals 𝛼,𝜅,𝜆, with transfinite play, proceeding until the board is filled or the winning conditions are achieved. Clearly, there are some instances of this game where a player has a winning strategy, such as the original Connect-Four configuration, where the first player wins, and presumably many other instances.
Question. In which instances of Connect-𝛼 on a board of size 𝜅×𝜆 does one of the players have a winning strategy?
It seems to me that the groups-of-three-columns strategy described above generalizes to show that the second player has at least a drawing strategy in Connect-𝛼 on board 𝜅×𝜆, whenever 𝛼 is infinite.
I have been reading Alan Turing’s paper, On computable numbers, with an application to the entsheidungsproblem, an amazing classic, written by Turing while he was a student in Cambridge. This is the paper in which Turing introduces and defines his Turing machine concept, deriving it from a philosophical analysis of what it is that a human computer is doing when carrying out a computational task.
The paper is an incredible achievement. He accomplishes so much: he defines and explains the machines; he proves that there is a universal Turing machine; he shows that there can be no computable procedure for determining the validities of a sufficiently powerful formal proof system; he shows that the halting problem is not computably decidable; he argues that his machine concept captures our intuitive notion of computability; and he develops the theory of computable real numbers.
What I was extremely surprised to find, however, and what I want to tell you about today, is that despite the title of the article, Turing adopts an incorrect approach to the theory of computable numbers. His central definition is what is now usually regarded as a mistaken way to proceed with this concept.
Let me explain. Turing defines that a computable real number is one whose decimal (or binary) expansion can be enumerated by a finite procedure, by what we now call a Turing machine. You can see this in the very first sentence of his paper, and he elaborates on and confirms this definition in detail later on in the paper.
He subsequently develops the theory of computable functions of computable real numbers, where one considers computable functions defined on these computable numbers. The computable functions are defined not on the reals themselves, however, but on the programs that enumerate the digits of those reals. Thus, for the role they play in Turing’s theory, a computable real number is not actually regarded as a real number as such, but as a program for enumerating the digits of a real number. In other words, to have a computable real number in Turing’s theory is to have a program for enumerating the digits of a real number. And it is this aspect of Turing’s conception of computable real numbers where his approach becomes problematic.
One specific problem with Turing’s approach is that on this account, it turns out that the operations of addition and multiplication for computable real numbers are not computable operations. Of course this is not what we want.
The basic mathematical fact in play is that the digits of a sum of two real numbers 𝑎+𝑏 is not a continuous function of the digits of 𝑎 and 𝑏 separately; in some cases, one cannot say with certainty the initial digits of 𝑎+𝑏, knowing only finitely many digits, as many as desired, of 𝑎 and 𝑏.
To see this, consider the following sum 𝑎+𝑏 0.343434343434⋯+0.656565656565⋯0.999999999999⋯
If you add up the numbers digit-wise, you get 9 in every place. That much is fine, and of course we should accept either 0.9999⋯ or 1.0000⋯ as correct answers for 𝑎+𝑏 in this instance, since those are both legitimate decimal representations of the number 1.
The problem, I claim, is that we cannot assign the digits of 𝑎+𝑏 in a way that will depend only on finitely many digits each of 𝑎 and 𝑏. The basic problem is that if we inspect only finitely many digits of 𝑎 and 𝑏, then we cannot be sure whether that pattern will continue, whether there will eventually be a carry or not, and depending on how the digits proceed, the initial digits of 𝑎+𝑏 can be affected.
In detail, suppose that we have committed to the idea that the initial digits of 𝑎+𝑏 are 0.999, on the basis of sufficiently many digits of 𝑎 and 𝑏. Let 𝑎′ and 𝑏′ be numbers that agree with 𝑎 and 𝑏 on those finite parts of 𝑎 and 𝑏, but afterwards have all 7s. In this case, the sum 𝑎′+𝑏′ will involve a carry, which will turn all the nines up to that point to 0, with a leading 1, making 𝑎′+𝑏′ strictly great than 1 and having decimal representation 1.000⋯00005555⋯. Thus, the initial-digits answer 0.999 would be wrong for 𝑎′+𝑏′, even though 𝑎′ and 𝑏′ agreed with 𝑎 and 𝑏 on the sufficiently many digits supposedly justifying the 0.999 answer. On the other hand, if we had committed ourselves to 1.000 for 𝑎+𝑏, on the basis of finite parts of 𝑎 and 𝑏 separately, then let 𝑎″ and 𝑏″ be all 2s beyond that finite part, in which case 𝑎″+𝑏″ is definitely less than 1, making 1.000 wrong.
Therefore, there is no algorithm to compute the digits of 𝑎+𝑏 continuously from the digits of 𝑎 and 𝑏 separately. It follows that there can be no computable algorithm for computing the digits of 𝑎+𝑏, given the programs that compute 𝑎 and 𝑏 separately, which is how Turing defines computable functions on the computable reals. (This consequence is a subtly different and stronger claim, but one can prove it using the Kleene recursion theorem. Namely, let 𝑎=.343434⋯ and then consider the program to enumerate a number 𝑏, which will begin with 0.656565 and keep repeating 65 until it sees that the addition program has given the initial digits for 𝑎+𝑏, and at this moment our program for 𝑏 will either switch to all 7s or all 2s in such a way so as to refute the result. The Kleene recursion theorem is used in order to know that indeed there is such a self-referential program enumerating 𝑏.)
One can make similar examples showing that multiplication and many other very simple functions are not computable, if one insists that a computable number is an algorithm enumerating the digits of the number.
So what is the right definition of computable number? Turing was right that in working with computable real numbers, we want to be working with the programs that compute them, rather than the reals themselves somehow. What is needed is a better way of saying that a given program computes a given real.
The right definition, widely used today, is that we want an algorithm not to compute exactly the digits of the number, but rather, to compute approximations to the number, as close as desired, with a known degree of accuracy. One can define a computable real number as a computable sequence of rational numbers, such that the 𝑛𝑡ℎ number is within 1/2𝑛 of the target number. This is equivalent to being able to compute rational intervals around the target real, of size less than any specified accuracy. And there are many other equivalent ways to do it. With this concept of computable real number, then the operations of addition, multiplication, and so on, all the familiar operations on the real numbers, will be computable.
But let me clear up a confusing point. Although I have claimed that Turing’s original definition of computable real number is incorrect, and I have explained how we usually define this concept today, the mathematical fact is that a real number 𝑥 has a computable presentation in Turing’s sense (we can compute the digits of 𝑥) if and only if it has a computable presentation in the contemporary sense (we can compute rational approximations to any specified accuracy). Thus, in terms of which real numbers we are talking about, the two approaches are extensionally the same.
Let me quickly prove this. If a real number 𝑥 is computable in Turing’s sense, so that we can compute the digits of 𝑥, then we can obviously compute rational approximations to any desired accuracy, simply by taking sufficiently many digits. And conversely, if a real number 𝑥 is computable in the contemporary sense, so we can compute rational approximations to any specified accuracy, then either it is itself a rational number, in which case we can certainly compute the digits of 𝑥, or else it is irrational, in which case for any specified digit place, we can wait until we have a rational approximation forcing it to one side or the other, and thereby come to know this digit. (Note: there are issues of intuitionistic logic occurring here, precisely because we cannot tell from the approximation algorithm itself which case we are in.) Note also that this argument works in any desired base.
So there is something of a philosophical problem here. The issue isn’t that Turing has misidentified particular reals as being computable or non-computable or has somehow got the computable reals wrong extensionally as a subset of the real numbers, since every particular real number has Turing’s kind of representation if and only if it has the approximation kind of representation. Rather, the problem is that because we want to deal with computable real numbers by working with the programs that represent them, Turing’s approach means that we cannot regard addition as a computable function on the computable reals. There is no computable procedure that when given two programs for enumerating the digits of real numbers 𝑎 and 𝑏 returns a program for enumerating the digits of the sum 𝑎+𝑏. But if you use the contemporary rational-approximation representation of computable real number, then you can computably produce a program for the sum, given programs for the input reals. This is the sense in which Turing’s approach is wrong.
I’d like to discuss the issue of error and error propagation in the constructions of classical geometry. How does error propagate in these constructions? How sensitive are the familiar classical constructions to small errors in the use of the straightedge or compass?
Let me illustrate what I have in mind by considering the classical construction of Apollonius of the perpendicular bisector of a line segment 𝐴𝐵. One forms two circles, centered at 𝐴 and 𝐵 respectively, each with radius 𝐴𝐵. These arcs intersect at points 𝑃 and 𝑄, respectively, which form the perpendicular bisector, meeting the original segment at the midpoint 𝐶.
That is all fine and good, and one can easily prove that indeed 𝑃𝑄 is perpendicular to 𝐴𝐵 and that 𝐶 is the midpoint of 𝐴𝐵, as desired.
When carrying out such a construction in practice, however, there will inevitably be some small errors. We do not expect to implement it exactly, with infinite precision, but rather, we expect some small errors in the placement of the compass or straightedge, and perhaps these errors may accumulate and they propagate through the construction. What I would like to discuss is the sensitivity of this construction and the other classical constructions to these small errors.
For example, suppose that we are given points 𝐴 and 𝐵. When we seek to construct the circle centered at 𝐴 with radius 𝐴𝐵, we place the point of the compass at 𝐴, and this placement may have some small error deviating from 𝐴, landing somewhere in the blue circle. Similarly, the writing (or etching) implement end of the compass is placed at 𝐵, with its own possibly different error, landing the orange circle at 𝐵. The arc actually resulting will be some arc arising with some such small errors, like this:
We may represent the space of all arcs that could arise in conformance with those error bounds as the blurred orange arc below. This image was created simply by drawing many dozens of such arcs in orange, with various choices for the center and radius within the error circles, and blending the results together.
We carry out the same construction with similar errors for the other arc, centered at 𝐵 and passing through 𝐴. These arcs overlap in the darker orange regions above and below, determining the points 𝑃 and 𝑄.
The actual arcs we draw and the corresponding vertical will land somewhere inside these blurred regions, perhaps like this:
Note that in this particular case, the resulting line 𝑃𝑄 is noticably non-perpendicular to 𝐴𝐵, and the resulting point 𝐶 is noticably not the midpoint. Consider the space of all the bisectors 𝑃𝑄 that might arise in conformance with our errors on 𝐴 and 𝐵, showing the result as the vertical red shaded region. The darker red region is the space of possible points 𝐶 that we might have constructed as the “midpoint” 𝐶, in conformance with the error estimates.
Given the size of the original error bounds on the points 𝐴 and 𝐵, it may be surprising that even such a standard simple construction as this — constructing the perpendicular bisector and midpoint of a segment — appears to have comparatively large error propagation, since the shaded red region 𝐶 is quite large and includes many points that one would not say are close to being the midpoint. In this sense, the Apollonius perpendicular bisector construction appears to be sensitive to the errors of compass placement.
Is there a better construction? For example, in terms of improving the accuracy at least of the perpendicularity of 𝑃𝑄 to 𝐴𝐵, it would seem to help to use a much larger circle, which would lower the variation in the resulting “right” angle. But this is partly because we have so far assumed that compass error arises only with the placement of the points of the compass, and not during the course of actually drawing the arc. But of course, one can imagine that errors arise from a flexing of the compass during use, causing it to deviate from circularity, or from slippage, which might reasonably be expected to cause increasing error with the length or degree of the arc, and so on, and such a model of error might have greater errors with large circles.
One could in principle carry out similar analyses for any geometric construction, and use the corresponding results to compare the sensitivity of various methods for constructing the same object, as well as modeling different sources of error. The goal might be to mount a precise analysis of all the standard constructions and compare competing constructions for accuracy.
There is a literature of papers doing precisely this, and I will try to post some references later (or please do so in the comments, if you have some good ones).
Another approach to error estimation would be to think of the errors at points 𝐴 and 𝐵 as probability distributions, centered at 𝐴 and 𝐵 and with a certain variation; and one then gets corresponding distributions for the points 𝑃 and 𝑄, which are not rigid shapes as in my diagrams, but qualitatively similar distributions spread out in that region, and a resulting probability distribution for the point 𝐶.
Finally, let me mention that one might hope to improve the accuracy of a construction, simply by repeating it and averaging the result, or by some other convergence algorithm. For example, as a first step, we might simply perform the Apollonius bisector construction twice, producing midpoint candidates 𝐶0 and 𝐶1, and we could proceed simply find the midpoint of 𝐶0𝐶1 as a further presumably more accurate midpoint. Or we could iterate in some other manner and hope to converge to the actual midpoint. For example, we could produce seven midpoint candidates, and take the resulting median point.
I’d like to explain to you how to draw chessboards by hand in perfect perspective, using only a straightedge. In this post, I’ll explain how to construct chessboards of any size, starting with the size of the basic unit square.
This post follows up on the post I made yesterday about how to draw a chessboard in perspective view, using only a straightedge. That method was a subdivision method, where one starts with the boundary of the desired board, and then subdivides to make a chessboard. Now, we start with the basic square and build up. This method is actually quite efficient for quickly making very large boards in perspective view.
I want to emphasize that this is something that you can actually do, right now. It’s fun! All you need is a piece of paper, a pencil and a straightedge. I’ll wait right here while you gather your materials. Use a ruler or a chop stick (as I did) or the edge of a notebook or the lid of a box. Sit at your table and draw a huge chessboard in perspective. You can totally do this.
Start with a horizon, having two points at infinity (orange), at left and right, and a third point midway between them (brown), which we will call the diagonal infinity. Also, mark the front corner of your chess board (blue).
Extend the front corner to the points at infinity. And then mark off (red) a point that will be a measure of the grid spacing in the chessboard. This will the be size of the front square.
You can extend that point to infinity at the right. This delimits the first rank of the chessboard.
Next, extend the front corner of the board to the diagonal infinity.
The intersection of that diagonal with the previous line determines a point, which when extended to infinity at the left, produces the first square of the chessboard.
And that line determines a new point on the leading rank edge. Extend that point up to the diagonal infinity, which determines another point on the second rank line.
Extend that line to infinity at the left, which determines another point on the leading rank edge.
Continuing in this way, one can produce as many first rank squares as desired. Go ahead and do that. At each step, you extend up to the diagonal infinity, which determines a new point, which when extended to infinity at the left determines another point, and so on.
If you should now reflect on the current diagram, you may notice that we have actually determined many further points in the grid than we have mentioned — and thanks to my daughter Hypatia for noticing this simplification — for there is a whole triangle of further intersection points between the files and the diagonals.
We can use these points (and we do not need them all) to construct the rest of the board, by drawing out the lines to infinity at the right. Thus, we construct the whole chessboard:
One can construct a perspective chessboard of any size this way, and one can simply continue with the construction and make it larger, if desired.
It will look a little better if you add a point at infinity down below (and do so directly below the diagonal point at infinity, but a good distance down below the board), and extend the board downward one level. The corresponding diagram on yesterday’s post might be helpful.
You can now color the tile pattern, and you’ll have a chessboard in perfect perspective view.
If you keep going, you can make extremely large chessboards. In time, I hope that you will come to learn how to complete an infinite chess board in finite time.
Let me show you how to hand-draw an image of a chessboard in perspective, using only a straightedge. There is no need to measure any distances or to make calculations of any kind. All you need is a straightedge, paper and your pen or pencil.
Imagine the vast doodling potential! A person who happens to be stuck in a lecture on some other less interesting topic could easily make one or more elaborate chessboards in perfect perspective, using only a straightedge! Please carry out the construction and then share your resulting images. I would love to see them.
To begin, give yourself a horizon at the top of the page, with two points at infinity (in orange), and also two points (blue) that will become the front and back corner of your chessboard. You can play around with different arrangements of these points, which will lead ultimately to different perspective views.
Using your straightedge, draw the lines from those reference points to the points at infinity. The resulting enclosed region will ultimately become the main chess board. One can alternatively think of starting with the front edges of the desired board, and then setting a horizon and using that to determine the points at infinity, and then adding the back edges. If you like, you can add a third point at infinity down below, and a front bottom reference point (blue), to give the board some thickness. Construct the lines to the bottom point at infinity.
The result is now the main outline of your chessboard as a rectangular solid.
Next, construct the center point of the top face, by drawing the two diagonals and finding the intersection point. I call this the center point, because it is the point that represents in the perspective view the actual center point of the chessboard, even though this point is not in the “center” of the quadrilateral representing the board. It is remarkable that one can find that point without needing to measure or calculate anything, simply because the two straight lines of the diagonal of the chessboard intersect at that point, and this remains true in the perspective view. This is the key idea that enables the entire construction method to proceed with only a straightedge.
Construct the midpoint lines by drawing the lines from that centerpoint to the points at infinity.
Now you have the chessboard with the main midlines drawn.
Construct the center points of the two diagonal squares, by intersecting the diagonals of each of them.
Construct the lines that extend those points to the points at infinity.
Thus, you have constructed the main 4 x 4 grid.
You can extend the grid lines down to the bottom point at infinity like so:
One can stop with the 4 x 4 board, if desired. Simply add suitable shading, and you’ve completed the 4 x 4 chessboard in perspective.
Alternatively, one can continue with one more iteration to construct the 8 x 8 board. From the 4 x 4 grid (with no shading yet) simply construct the center points of the squares on the main diagonal, and extend those lines to infinity. This will enable you to draw the 8 x 8 grid lines, and after shading, you’ll have the complete chessboard.
The initial arrangement of points affects the nature of the perspective view. Having the points at infinity very far away will produce something closer to orthoprojection; having them close produces a more extreme perspective, which simulates a view from a vantage point extremely close to the board.
Please give the construction a try! All you need is paper, pencil and a straightedge! Provide links below in the comments to photos of your creations.
In recent work, Alfredo Roque Freire and I have realized that the axiom of well-ordered replacement is equivalent to the full replacement axiom, over the Zermelo set theory with foundation.
The well-ordered replacement axiom is the scheme asserting that if 𝐼 is well-ordered and every 𝑖∈𝐼 has unique 𝑦𝑖 satisfying a property 𝜙(𝑖,𝑦𝑖), then {𝑦𝑖∣𝑖∈𝐼} is a set. In other words, the image of a well-ordered set under a first-order definable class function is a set.
Alfredo had introduced the theory Zermelo + foundation + well-ordered replacement, because he had noticed that it was this fragment of ZF that sufficed for an argument we were mounting in a joint project on bi-interpretation. At first, I had found the well-ordered replacement theory a bit awkward, because one can only apply the replacement axiom with well-orderable sets, and without the axiom of choice, it seemed that there were not enough of these to make ordinary set-theoretic arguments possible.
But now we know that in fact, the theory is equivalent to ZF.
Theorem. The axiom of well-ordered replacement is equivalent to full replacement over Zermelo set theory with foundation.
ZF=Z+foundation+well-orderedreplacement
Proof. Assume Zermelo set theory with foundation and well-ordered replacement.
Well-ordered replacement is sufficient to prove that transfinite recursion along any well-order works as expected. One proves that every initial segment of the order admits a unique partial solution of the recursion up to that length, using well-ordered replacement to put them together at limits and overall.
Applying this, it follows that every set has a transitive closure, by iteratively defining ∪𝑛𝑥 and taking the union. And once one has transitive closures, it follows that the foundation axiom can be taken either as the axiom of regularity or as the ∈-induction scheme, since for any property 𝜙, if there is a set 𝑥 with ¬𝜙(𝑥), then let 𝐴 be the set of elements 𝑎 in the transitive closure of {𝑥} with ¬𝜙(𝑎); an ∈-minimal element of 𝐴 is a set 𝑎 with ¬𝜙(𝑎), but 𝜙(𝑏) for all 𝑏∈𝑎.
Another application of transfinite recursion shows that the 𝑉𝛼 hierarchy exists. Further, we claim that every set 𝑥 appears in the 𝑉𝛼 hierarchy. This is not immediate and requires careful proof. We shall argue by ∈-induction using foundation. Assume that every element 𝑦∈𝑥 appears in some 𝑉𝛼. Let 𝛼𝑦 be least with 𝑦∈𝑉𝛼𝑦. The problem is that if 𝑥 is not well-orderable, we cannot seem to collect these various 𝛼𝑦 into a set. Perhaps they are unbounded in the ordinals? No, they are not, by the following argument. Define an equivalence relation 𝑦∼𝑦′ iff 𝛼𝑦=𝛼𝑦′. It follows that the quotient 𝑥/∼ is well-orderable, and thus we can apply well-ordered replacement in order to know that {𝛼𝑦∣𝑦∈𝑥} exists as a set. The union of this set is an ordinal 𝛼 with 𝑥⊆𝑉𝛼 and so 𝑥∈𝑉𝛼+1. So by ∈-induction, every set appears in some 𝑉𝛼.
The argument establishes the principle: for any set 𝑥 and any definable class function 𝐹:𝑥→Ord, the image 𝐹”𝑥 is a set. One proves this by defining an equivalence relation 𝑦∼𝑦′↔𝐹(𝑦)=𝐹(𝑦′) and observing that 𝑥/∼ is well-orderable.
We can now establish the collection axiom, using a similar idea. Suppose that 𝑥 is a set and every 𝑦∈𝑥 has a witness 𝑧 with 𝜙(𝑦,𝑧). Every such 𝑧 appears in some 𝑉𝛼, and so we can map each 𝑦∈𝑥 to the smallest 𝛼𝑦 such that there is some 𝑧∈𝑉𝛼𝑦 with 𝜙(𝑦,𝑧). By the observation of the previous paragraph, the set of 𝛼𝑦 exists and so there is an ordinal 𝛼 larger than all of them, and thus 𝑉𝛼 serves as a collecting set for 𝑥 and 𝜙, verifying this instance of collection.
From collection and separation, we can deduce the replacement axiom ◻
I’ve realized that this allows me to improve an argument I had made some time ago, concerning Transfinite recursion as a fundamental principle. In that argument, I had proved that ZC + foundation + transfinite recursion is equivalent to ZFC, essentially by showing that the principle of transfinite recursion implies replacement for well-ordered sets. The new realization here is that we do not need the axiom of choice in that argument, since transfinite recursion implies well-ordered replacement, which gives us full replacement by the argument above.
Corollary. The principle of transfinite recursion is equivalent to the replacement axiom over Zermelo set theory with foundation.
I was recently asked this interesting question on set-theoretic geology by Iian Smythe, a set-theory post-doc at Rutgers University; the problem arose in the context of one of this current research projects.
Question. Assume that two product forcing extensions are the same 𝑀[𝐺][𝐾]=𝑀[𝐻][𝐾], where 𝑀[𝐺] and 𝑀[𝐻] are forcing extensions of 𝑀 by the same forcing notion ℙ, and 𝐾⊂ℚ∈𝑀 is both 𝑀[𝐺] and 𝑀[𝐻]-generic with respect to this further forcing ℚ. Can we conclude that 𝑀[𝐺]=𝑀[𝐻]? Can we make this conclusion at least in the special case that ℙ is adding a Cohen real and ℚ is collapsing the continuum?
It seems natural to hope for a positive answer, because we are aware of many such situations that arise with forcing, where indeed 𝑀[𝐺]=𝑀[𝐻]. Nevertheless, the answer is negative. Indeed, we cannot legitimately make this conclusion even when both steps of forcing are adding merely a Cohen real. And such a counterexample implies that there is a counterexample of the type mentioned in the question, simply by performing further collapse forcing.
Theorem. For any countable model 𝑀 of set theory, there are 𝑀-generic Cohen reals 𝑐, 𝑑 and 𝑒, such that
The Cohen reals 𝑐 and 𝑒 are mutually generic over 𝑀.
The Cohen reals 𝑑 and 𝑒 are mutually generic over 𝑀.
These two pairs produce the same forcing extension 𝑀[𝑐][𝑒]=𝑀[𝑑][𝑒].
But the intermediate models are different 𝑀[𝑐]≠𝑀[𝑑].
Proof. Fix 𝑀, and let 𝑐 and 𝑒 be any two mutually generic Cohen reals over 𝑀. Let us view them as infinite binary sequences, that is, as elements of Cantor space. In the extension 𝑀[𝑐][𝑒], let 𝑑=𝑐+𝑒mod2, in each coordinate. That is, we get 𝑑 from 𝑐 by flipping bits, but only on coordinates that are 1 in 𝑒. This is the same as applying a bit-flipping automorphism of the forcing, which is available in 𝑀[𝑒], but not in 𝑀. Since 𝑐 is 𝑀[𝑒]-generic by reversing the order of forcing, it follows that 𝑑 also is 𝑀[𝑒]-generic, since the automorphism is in 𝑀[𝑒]. Thus, 𝑑 and 𝑒 are mutually generic over 𝑀. Further, 𝑀[𝑐][𝑒]=𝑀[𝑑][𝑒], because 𝑀[𝑒][𝑐]=𝑀[𝑒][𝑑], as 𝑐 and 𝑑 were isomorphic generic filters by an isomorphism in 𝑀[𝑒]. But finally, 𝑀[𝑐] and 𝑀[𝑑] are not the same, because from 𝑐 and 𝑑 together we can construct 𝑒, because we can tell exactly which bits were flipped. ◻
If one now follows the 𝑒 forcing with collapse forcing, one achieves a counterexample model of the type mentioned in the question, namely, with 𝑀[𝑐][𝑒∗𝐾]=𝑀[𝑑][𝑒∗𝐾], but 𝑀[𝑐]≠𝑀[𝑑].
I have a feeling that my co-authors on a current paper in progress, Set-theoretic blockchains, on the topic of non-amalgamation in the generic multiverse, will tell me that the argument above is an instance of some of the theorems we prove in the latter part of that paper. (Miha, please tell me in the comments, if you see this, or tell me where I have seen this argument before; I think I made this argument or perhaps seen it before.) The paper is [bibtex key=”HabicHamkinsKlausnerVernerWilliams2018:Set-theoretic-blockchains”].
I have found a new proof of the Barwise extension theorem, that wonderful yet quirky result of classical admissible set theory, which says that every countable model of set theory can be extended to a model of ZFC+𝑉=𝐿.
Barwise Extension Theorem. (Barwise 1971) Every countable model of set theory 𝑀⊧ZF has an end-extension to a model of ZFC+𝑉=𝐿.
The Barwise extension theorem is both (i) a technical culmination of the pioneering methods of Barwise in admissible set theory and infinitary logic, including the Barwise compactness and completeness theorems and the admissible cover, but also (ii) one of those rare mathematical theorems that is saturated with significance for the philosophy of mathematics and particularly the philosophy of set theory. I discussed the theorem and its philosophical significance at length in my paper, The multiverse perspective on the axiom of constructibility, where I argued that it can change how we look upon the axiom of constructibility and whether this axiom should be considered ‘restrictive,’ as it often is in set theory. Ultimately, the Barwise extension theorem shows how wrong a model of set theory can be, if we should entertain the idea that the set-theoretic universe continues growing beyond it.
Regarding my new proof, below, however, what I find especially interesting about it, if not surprising in light of (i) above, is that it makes no use of Barwise compactness or completeness and indeed, no use of infinitary logic at all! Instead, the new proof uses only classical methods of descriptive set theory concerning the representation of Π11 sets with well-founded trees, the Levy and Shoenfield absoluteness theorems, the reflection theorem and the Keisler-Morley theorem on elementary extensions via definable ultrapowers. Like the Barwise proof, my proof splits into cases depending on whether the model 𝑀 is standard or nonstandard, but another interesting thing about it is that with my proof, it is the 𝜔-nonstandard case that is easier, whereas with the Barwise proof, the transitive case was easiest, since one only needed to resort to the admissible cover when 𝑀 was ill-founded. Barwise splits into cases on well-founded/ill-founded, whereas in my argument, the cases are 𝜔-standard/𝜔-nonstandard.
To clarify the terms, an end-extension of a model of set theory ⟨𝑀,∈𝑀⟩ is another model ⟨𝑁,∈𝑁⟩, such that the first is a substructure of the second, so that 𝑀⊆𝑁 and ∈𝑀=∈𝑁↾𝑀, but further, the new model does not add new elements to sets in 𝑀. In other words, 𝑀 is an ∈-initial segment of 𝑁, or more precisely: if 𝑎∈𝑁𝑏∈𝑀, then 𝑎∈𝑀 and hence 𝑎∈𝑀𝑏.
Set theory, of course, overflows with instances of end-extensions. For example, the rank-initial segments 𝑉𝛼 end-extend to their higher instances 𝑉𝛽, when 𝛼<𝛽; similarly, the hierarchy of the constructible universe 𝐿𝛼⊆𝐿𝛽 are end-extensions; indeed any transitive set end-extends to all its supersets. The set-theoretic universe 𝑉 is an end-extension of the constructible universe 𝐿 and every forcing extension 𝑀[𝐺] is an end-extension of its ground model 𝑀, even when nonstandard. (In particular, one should not confuse end-extensions with rank-extensions, also known as top-extensions, where one insists that all the new sets have higher rank than any ordinal in the smaller model.)
Let’s get into the proof.
Proof. Suppose that 𝑀 is a model of ZF set theory. Consider first the case that 𝑀 is 𝜔-nonstandard. For any particular standard natural number 𝑘, the reflection theorem ensures that there are arbitrarily high 𝐿𝑀𝛼 satisfying ZFC𝑘+𝑉=𝐿, where ZFC𝑘 refers to the first 𝑘 axioms of ZFC in a fixed computable enumeration by length. In particular, every countable transitive set 𝑚∈𝐿𝑀 has an end-extension to a model of ZFC𝑘+𝑉=𝐿. By overspill (that is, since the standard cut is not definable), there must be some nonstandard 𝑘 for which 𝐿𝑀 thinks that every countable transitive set 𝑚 has an end-extension to a model of ZFC𝑘+𝑉=𝐿, which we may assume is countable. This is a Π12 statement about 𝑘, which will therefore also be true in 𝑀, by the Shoenfield absolutenss theorem. It will also be true in all the elementary extensions of 𝑀, as well as in their forcing extensions. And indeed, by the Keisler-Morley theorem, the model 𝑀 has an elementary top extension 𝑀+. Let 𝜃 be a new ordinal on top of 𝑀, and let 𝑚=𝑉𝑀+𝜃 be the 𝜃-rank-initial segment of 𝑀+, which is a top-extension of 𝑀. Let 𝑀+[𝐺] be a forcing extension in which 𝑚 has become countable. Since the Π12 statement is true in 𝑀+[𝐺], there is an end-extension of ⟨𝑚,∈𝑀+⟩ to a model ⟨𝑁,∈𝑁⟩ that 𝑀+[𝐺] thinks satisfies ZFC𝑘+𝑉=𝐿. Since 𝑘 is nonstandard, this theory includes all the ZFC axioms, and since 𝑚 end-extends 𝑀, we have found an end-extension of 𝑀 to a model of ZFC+𝑉=𝐿, as desired.
It remains to consider the case where 𝑀 is 𝜔-standard. By the Keisler-Morley theorem, let 𝑀+ be an elementary top-extension of 𝑀. Let 𝜃 be an ordinal of 𝑀+ above 𝑀, and consider the corresponding rank-initial segment 𝑚=𝑉𝑀+𝜃, which is a transitive set in 𝑀+ that covers 𝑀. If ⟨𝑚,∈𝑀+⟩ has an end-extension to a model of ZFC+𝑉=𝐿, then we’re done, since such a model would also end-extend 𝑀. So assume toward contradiction that there is no such end-extension of 𝑚. Let 𝑀+[𝐺] be a forcing extension in which 𝑚 has become countable. The assertion that 𝑚 has no end-extension to a model of ZFC+𝑉=𝐿 is actually true and hence true in 𝑀+[𝐺]. This is a Π11 assertion there about the real coding 𝑚. Every such assertion has a canonically associated tree, which is well-founded exactly when the statement is true. Since the statement is true in 𝑀+[𝐺], this tree has some countable rank 𝜆 there. Since these models have the standard 𝜔, the tree associated with the statement is the same for us as inside the model, and since the statement is actually true, the tree is actually well founded. So the rank 𝜆 must come from the well-founded part of the model.
If 𝜆 happens to be countable in 𝐿𝑀+, then consider the assertion, “there is a countable transitive set, such that the assertion that it has no end-extension to a model of ZFC+𝑉=𝐿 has rank 𝜆.” This is a Σ1 assertion, since it is witnessed by the countable transitive set and the ranking function of the tree associated with the non-extension assertion. Since the parameters are countable, it follows by Levy reflection that the statement is true in 𝐿𝑀+. So 𝐿𝑀+ has a countable transitive set, such that the assertion that it has no end-extension to a model of ZFC+𝑉=𝐿 has rank 𝜆. But since 𝜆 is actually well-founded, the statement would have to be actually true; but it isn’t, since 𝐿𝑀+ itself is such an extension, a contradiction.
So we may assume 𝜆 is uncountable in 𝑀+. In this case, since 𝜆 was actually well-ordered, it follows that 𝐿𝑀 is well-founded beyond its 𝜔1. Consider the statement “there is a countable transitive set having no end-extension to a model of ZFC+𝑉=𝐿.” This is a Σ12 sentence, which is true in 𝑀+[𝐺] by our assumption about 𝑚, and so by Shoenfield absoluteness, it is true in 𝐿𝑀+ and hence also 𝐿𝑀. So 𝐿𝑀 thinks there is a countable transitive set 𝑏 having no end-extension to a model of ZFC+𝑉=𝐿. This is a Π11 assertion about 𝑏, whose truth is witnessed in 𝐿𝑀 by a ranking of the associated tree. Since this rank would be countable in 𝐿𝑀 and this model is well-founded up to its 𝜔1, the tree must be actually well-founded. But this is impossible, since it is not actually true that 𝑏 has no such end-extension, since 𝐿𝑀 itself is such an end-extension of 𝑏. Contradiction. ◻
One can prove a somewhat stronger version of the theorem, as follows.
Theorem. For any countable model 𝑀 of ZF, with an inner model 𝑊⊧ZFC, and any statement 𝜙 true in 𝑊, there is an end-extension of 𝑀 to a model of ZFC+𝜙. Furthermore, one can arrange that every set of 𝑀 is countable in the extension model.
In particular, one can find end-extensions of ZFC+𝑉=𝐿+𝜙, for any statement 𝜙 true in 𝐿𝑀.
Proof. Carry out the same proof as above, except in all the statements, ask for end-extensions of ZFC+𝜙, instead of end-extensions of ZFC+𝑉=𝐿, and also ask that the set in question become countable in that extension. The final contradictions are obtained by the fact that the countable transitive sets in 𝐿𝑀 do have end-extensions like that, in which they are countable, since 𝑊 is such an end-extension. ◻
For example, we can make the following further examples.
Corollaries.
Every countable model 𝑀 of ZFC with a measurable cardinal has an end-extension to a model 𝑁 of ZFC+𝑉=𝐿[𝜇].
Every countable model 𝑀 of ZFC with extender-based large cardinals has an end-extension to a model 𝑁 satisfying ZFC+𝑉=𝐿[⃗𝐸].
Every countable model 𝑀 of ZFC with infinitely many Woodin cardinals has an end-extension to a model 𝑁 of ZF+AD+𝑉=𝐿(ℝ).
And in each case, we can furthermore arrange that every set of 𝑀 is countable in the extension model 𝑁.
This proof grew out of a project on the Σ1-definable universal finite set, which I am currently undertaking with Kameryn Williams and Philip Welch.
Consider what I call the Sudoku game, recently introduced in the MathOverflow question Who wins two-player Sudoku? posted by Christopher King (user PyRulez). Two players take turns placing numbers on a Sudoku board, obeying the rule that they must never explicitly violate the Sudoku condition: the numbers on any row, column or sub-board square must never repeat. The first player who cannot continue legal play loses. Who wins the game? What is the winning strategy?
The game is not about building a global Sudoku solution, since a move can be legal in this game even when it is not part of any global Sudoku solution, provided only that it doesn’t yet explicitly violate the Sudoku condition. Rather, the Sudoku game is about trying to trap your opponent in a maximal such position, a position which does not yet explicitly violate the Sudoku condition but which cannot be further extended.
In my answer to the question on MathOverflow, I followed an idea suggested to me by my daughter Hypatia, namely that on even-sized boards 𝑛2×𝑛2 where 𝑛 is even, then the second player can win with a mirroring strategy: simply copy the opponent’s moves in reflected mirror image through the center of the board. In this way, the second player ensures that the position on the board is always symmetric after her play, and so if the previous move was safe, then her move also will be safe by symmetry. This is therefore a winning strategy for the second player, since any violation of the Sudoku condition will arise on the opponent’s play.
This argument works on even-sized boards precisely because the reflection of every row, column and sub-board square is a totally different row, column and sub-board square, and so any new violation of the Sudoku conditions would reflect to a violation that was already there. The mirror strategy definitely does not work on the odd-sized boards, including the main 9×9 case, since if the opponent plays on the central row, copying directly would immediately introduce a Sudoku violation.
After posting that answer, Orson Peters (user orlp) pointed out that one can modify it to form a winning strategy for the first player on odd-sized boards, including the main 9×9 case. In this case, let the first player begin by playing 5 in the center square, and then afterwards copy the opponent’s moves, but with the ten’s complement at the reflected location. So if the opponent plays 𝑥, then the first player plays 10−𝑥 at the reflected location. In this way, the first player can ensure that the board is ten’s complement symmetric after her moves. The point is that again this is sufficient to know that she will never introduce a violation, since if her 10−𝑥 appears twice in some row, column or sub-board square, then 𝑥 must have already appeared twice in the reflected row, column or sub-board square before that move.
This idea is fully general for odd-sized Sudoku boards 𝑛2×𝑛2, where 𝑛 is odd. If 𝑛=2𝑘−1, then the first player starts with 𝑘 in the very center and afterward plays the 2𝑘-complement of her opponent’s move at the reflected location.
Conclusion.
On even-sized Sudoku boards, the second player wins the Sudoku game by the mirror copying strategy.
On odd-sized Sudoku boards, the first players wins the Sudoku game by the complement-mirror copying strategy.
Note that on the even boards, the second player could also play complement mirror copying just as successfully.
What I really want to tell you about, however, is the infinite Sudoku game (following a suggestion of Sam Hopkins). Suppose that we try to play the Sudoku game on a board whose subboard squares are ℤ×ℤ, so that the full board is a ℤ×ℤ array of those squares, making ℤ2×ℤ2 altogether. (Or perhaps you might prefer the board ℕ2×ℕ2?)
One thing to notice is that on an infinite board, it is no longer possible to get trapped at a finite stage of play, since every finite position can be extended simply by playing a totally new label from the set of labels; such a move would never lead to a new violation of the explicit Sudoku condition.
For this reason, I should like to introduce the Sudoku Solver-Spoiler game variation as follows. There are two players: the Sudoku Solver and the Sudoku Spoiler. The Solver is trying to build a global Sudoku solution on the board, while the Spoiler is trying to prevent this. Both players must obey the Sudoku condition that labels are never to be explicitly repeated in any row, column or sub-board square. On an infinite board, the game proceeds transfinitely, until the board is filled or there are no legal moves. The Solver wins a play of the game, if she successfully builds a global Sudoku solution, which means not only that every location has a label and there are no repetitions in any row, column or sub-board square, but also that every label in fact appears in every row, column and sub-board square. That is, to count as a solution, the labels on any row, column and sub-board square must be a bijection with the set of labels. (On infinite boards, this is a stronger requirement than merely insisting on no repetitions.)
The Solver-Spoiler game makes sense in complete generality on any set 𝑆, whether finite or infinite. The sub-boards are 𝑆2=𝑆×𝑆, and one has an 𝑆×𝑆 array of them, so 𝑆2×𝑆2 for the whole board. Every row and column has the same size as the sub-board square 𝑆2, and the set of labels should also have this size.
Upon reflection, one realizes that what matters about 𝑆 is just its cardinality, and we really have for every cardinal 𝜅 the 𝜅-Sudoku Solver-Spoiler game, whose board is 𝜅2×𝜅2, a 𝜅×𝜅 array of 𝜅×𝜅 sub-boards. In particular, the game ℤ2×ℤ2 is actually isomorphic to the game ℕ2×ℕ2, despite what might feel initially like a very different board geometry.
What I claim is that the Solver has a winning strategy in the all the infinite Sudoku Solver-Spoiler games, in a very general and robust manner.
Theorem. For every infinite cardinal 𝜅, the Solver has a winning strategy to win the 𝜅-Sudoku Solver-Spoiler game.
The strategy will win in 𝜅 many moves, producing a full Sudoku solution.
The Solver can win whether she goes first or second, starting from any legal position of size less than 𝜅.
The Solver can win even when the Spoiler is allowed to play finitely many labels at once on each turn, or fewer than 𝜅 many moves (if 𝜅 is regular), even if the Solver is only allowed one move each turn.
In the countably infinite Sudoku game, the Solver can win even if the Spoiler is allowed to make infinitely many moves at once, provided only that the resulting position can in principle be extended to a full solution.
Proof. Consider first the countably infinite Sudoku game, and assume the initial position is finite and that the Spoiler will make finitely many moves on each turn. Consider what it means for the Solver to win at the limit. It means, first of all, that there are no explicit repetitions in any row, column or sub-board. This requirement will be ensured since it is part of the rules for legal play not to violate it. Next, the Solver wants to ensure that every square has a label on it and that every label appears at least once in every row, every column and every sub-board. If we think of these as individual specific requirements, we have countably many requirements in all, and I claim that we can arrange that the Solver will simply satisfy the 𝑛𝑡ℎ requirement on her 𝑛𝑡ℎ play. Given any finite position, she can always find something to place in any given square, using a totally new label if need be. Given any finite position, any row and any particular label 𝑘, since can always find a place on that row to place the label, which has no conflict with any column or sub-board, since there are infinitely many to choose from and only finitely many conflicts. Similarly with columns and sub-boards. So each of the requirements can always be fulfilled one-at-a-time, and so in 𝜔 many moves she can produce a full solution.
The argument works equally well no matter who goes first or if the Spoiler makes arbitrary finite play, or indeed even infinite play, provided that the play is part of some global solution (perhaps a different one each time), since on each move the Solve can simply meet the requirement by using that solution at that stage.
An essentially similar argument works when 𝜅 is uncountable, although now the play will proceed for 𝜅 many steps. Assuming 𝜅2=𝜅, a consequence of the axiom of choice, there are 𝜅 many requirements to meet, and the Solve can meet requirement 𝛼 on the 𝛼𝑡ℎ move. If 𝜅 is regular, we can again allow the Spoiler to make arbitrary size-less-than-𝜅 size moves, so that at any stage of play before 𝜅 the position will still be size less than 𝜅. (If 𝜅 is singular, one can allow Spoiler to make finitely many moves at once or indeed even some uniform bounded size 𝛿<𝜅 many moves at once. ◻
I find it interesting to draw out the following aspect of the argument:
Observation. Every finite labeling of an infinite Sudoku board that does not yet explicitly violate the Sudoku condition can be extended to a global solution.
Similarly, any size less than 𝜅 labeling that does not yet explicitly violate the Sudoku condition can be extended to a global solution of the 𝜅-Sudoku board for any infinite cardinal 𝜅.
What about asymmetric boards? It has come to my attention that people sometimes look at asymmetric Sudoku boards, whose sub-boards are not square, such as in the six-by-six Sudoku case. In general, one could take Sudoku boards to consist of a 𝜆×𝜅 array of sub-boards of size 𝜅×𝜆, where 𝜅 and 𝜆 are cardinals, not necessarily the same size and not necessarily both infinite or both finite. How does this affect the arguments I’ve given?
In the finite (𝑛×𝑚)×(𝑚×𝑛) case, if one of the numbers is even, then it seems to me that the reflection through the origin strategy works for the second player just as before. And if both are odd, then the first player can again play in the center square and use the mirror-complement strategy to trap the opponent. So that analysis will work fine.
In the case (𝜅×𝜆)×(𝜆×𝜅) where 𝜆≤𝜅 and 𝜅=𝜆𝜅 is infinite, then the proof of the theorem seems to break, since if 𝜆<𝜅, then with only 𝜆 many moves, say putting a common symbol in each of the 𝜆 many rectangles across a row, we can rule out that symbol in a fixed row. So this is a configuration of size less than 𝜅 that cannot be extended to a full solution. For this reason, it seems likely to me that the Spoiler can win the Sudoko Solver-Spoiler game in the infinite asymmetric case.
Finally, let’s consider the Sudoku Solver-Spoiler game in the purely finite case, which actually is a very natural game, perhaps more natural than what I called the Sudoku game above. It seems to me that the Spoiler should be able to win the Solver-Spoiler game on any nontrivial finite board. But I don’t yet have an argument proving this. I asked a question on MathOverflow: The Sudoku game: Solver-Spoiler variation.
I was fascinated recently to discover something I hadn’t realized about relative interpretability in set theory, and I’d like to share it here. Namely,
Different set theories extending ZF are never bi-interpretable!
For example, ZF and ZFC are not bi-interpretable, and neither are ZFC and ZFC+CH, nor ZFC and ZFC+¬CH, despite the fact that all these theories are equiconsistent. The basic fact is that there are no nontrivial instances of bi-interpretation amongst the models of ZF set theory. This is surprising, and could even be seen as shocking, in light of the philosophical remarks one sometimes hears asserted in the philosophy of set theory that what is going on with the various set-theoretic translations from large cardinals to determinacy to inner model theory, to mention a central example, is that we can interpret between these theories and consequently it doesn’t much matter which context is taken as fundamental, since we can translate from one context to another without loss.
The bi-interpretation result shows that these interpretations do not and cannot rise to the level of bi-interpretations of theories — the most robust form of mutual relative interpretability — and consequently, the translations inevitably must involve a loss of information.
To be sure, set theorists classify the various set-theoretic principles and theories into a hierarchy, often organized by consistency strength or by other notions of interpretative power, using forcing or definable inner models. From any model of ZF, for example, we can construct a model of ZFC, and from any model of ZFC, we can construct models of ZFC+CH or ZFC+¬CH and so on. From models with sufficient large cardinals we can construct models with determinacy or inner-model-theoretic fine structure and vice versa. And while we have relative consistency results and equiconsistencies and even mutual interpretations, we will have no nontrivial bi-interpretations.
(I had proved the theorem a few weeks ago in joint work with Alfredo Roque Freire, who is visiting me in New York this year. We subsequently learned, however, that this was a rediscovery of results that have evidently been proved independently by various authors. Albert Visser proves the case of PA in his paper, “Categories of theories and interpretations,” Logic in Tehran, 284–341, Lect. Notes Log., 26, Assoc. Symbol. Logic, La Jolla, CA, 2006, (pdf, see pp. 52-55). Ali Enayat gave a nice model-theoretic argument for showing specifically that ZF and ZFC are not bi-interpretable, using the fact that ZFC models can have no involutions in their automorphism groups, but ZF models can; and he proved the general version of the theorem, for ZF, second-order arithmetic 𝑍2 and second-order set theory KM in his 2016 article, A. Enayat, “Variations on a Visserian theme,” in Liber Amicorum Alberti : a tribute to Albert Visser / Jan van Eijck, Rosalie Iemhoff and Joost J. Joosten (eds.) Pages, 99-110. ISBN, 978-1848902046. College Publications, London. The ZF version was apparently also observed independently by Harvey Friedman, Visser and Fedor Pakhomov.)
Meanwhile, let me explain our argument. Recall from model theory that one theory 𝑆 is interpreted in another theory 𝑇, if in any model of the latter theory 𝑀⊧𝑇, we can define (and uniformly so in any such model) a certain domain 𝑁⊂𝑀𝑘 and relations and functions on that domain so as to make 𝑁 a model of 𝑆. For example, the theory of algebraically closed fields of characteristic zero is interpreted in the theory of real-closed fields, since in any real-closed field 𝑅, we can consider pairs (𝑎,𝑏), thinking of them as 𝑎+𝑏𝑖, and define addition and multiplication on those pairs in such a way so as to construct an algebraically closed field of characteristic zero.
Two theories are thus mutually interpretable, if each of them is interpretable in the other. Such theories are necessarily equiconsistent, since from any model of one of them we can produce a model of the other.
Note that mutual interpretability, however, does not insist that the two translations are inverse to each other, even up to isomorphism. One can start with a model of the first theory 𝑀⊧𝑇 and define the interpreted model 𝑁⊧𝑆 of the second theory, which has a subsequent model of the first theory again ¯𝑀⊧𝑇 inside it. But the definition does not insist on any particular connection between 𝑀 and ¯𝑀, and these models need not be isomorphic nor even elementarily equivalent in general.
By addressing this, one arrives at a stronger and more robust form of mutual interpretability. Namely, two theories 𝑆 and 𝑇 are bi-interpretable, if they are mutually interpretable in such a way that the models can see that the interpretations are inverse. That is, for any model 𝑀 of the theory 𝑇, if one defines the interpreted model 𝑁⊧𝑆 inside it, and then defines the interpreted model ¯𝑀 of 𝑇 inside 𝑁, then 𝑀 is isomorphic to ¯𝑀 by a definable isomorphism in 𝑀, and uniformly so (and the same with the theories in the other direction). Thus, every model of one of the theories can see exactly how it itself arises definably in the interpreted model of the other theory.
For example, the theory of linear orders ≤ is bi-interpretable with the theory of strict linear order <, since from any linear order ≤ we can define the corresponding strict linear order < on the same domain, and from any strict linear order < we can define the corresponding linear order ≤, and doing it twice brings us back again to the same order.
For a richer example, the theory PA is bi-interpretable with the finite set theory ZF¬∞, where one drops the infinity axiom from ZF and replaces it with the negation of infinity, and where one has the ∈-induction scheme in place of the foundation axiom. The interpretation is via the Ackerman encoding of hereditary finite sets in arithmetic, so that 𝑛𝐸𝑚 just in case the 𝑛𝑡ℎ binary digit of 𝑚 is 1. If one starts with the standard model ℕ, then the resulting structure ⟨ℕ,𝐸⟩ is isomorphic to the set ⟨HF,∈⟩ of hereditarily finite sets. More generally, by carrying out the Ackermann encoding in any model of PA, one thereby defines a model of ZF¬∞, whose natural numbers are isomorphic to the original model of PA, and these translations make a bi-interpretation.
We are now ready to prove that this bi-interpretation situation does not occur with different set theories extending ZF.
Theorem. Distinct set theories extending ZF are never bi-interpretable. Indeed, there is not a single model-theoretic instance of bi-interpretation occurring with models of different set theories extending ZF.
Proof. I mean “distinct” here in the sense that the two theories are not logically equivalent; they do not have all the same theorems. Suppose that we have a bi-interpretation instance of the theories 𝑆 and 𝑇 extending ZF. That is, suppose we have a model ⟨𝑀,∈⟩⊧𝑇 of the one theory, and inside 𝑀, we can define an interpreted model of the other theory ⟨𝑁,∈𝑁⟩⊧𝑆, so the domain of 𝑁 is a definable class in 𝑀 and the membership relation ∈𝑁 is a definable relation on that class in 𝑀; and furthermore, inside ⟨𝑁,∈𝑁⟩, we have a definable structure ⟨¯𝑀,∈¯𝑀⟩ which is a model of 𝑇 again and isomorphic to ⟨𝑀,∈𝑀⟩ by an isomorphism that is definable in ⟨𝑀,∈𝑀⟩. So 𝑀 can define the map 𝑎↦¯𝑎 that forms an isomorphism of ⟨𝑀,∈𝑀⟩ with ⟨¯𝑀,∈¯𝑀⟩. Our argument will work whether we allow parameters in any of these definitions or not.
I claim that 𝑁 must think the ordinals of ¯𝑀 are well-founded, for otherwise it would have some bounded cut 𝐴 in the ordinals of ¯𝑀 with no least upper bound, and this set 𝐴 when pulled back pointwise by the isomorphism of 𝑀 with ¯𝑀 would mean that 𝑀 has a cut in its own ordinals with no least upper bound; but this cannot happen in ZF.
If the ordinals of 𝑁 and ¯𝑀 are isomorphic in 𝑁, then all three models have isomorphic ordinals in 𝑀, and in this case, ⟨𝑀,∈𝑀⟩ thinks that ⟨𝑁,∈𝑁⟩ is a well-founded extensional relation of rank Ord. Such a relation must be set-like (since there can be no least instance where the predecessors form a proper class), and so 𝑀 can perform the Mostowski collapse of ∈𝑁, thereby realizing 𝑁 as a transitive class 𝑁⊆𝑀 with ∈𝑁=∈𝑀↾𝑁. Similarly, by collapsing we may assume ¯𝑀⊆𝑁 and ∈¯𝑀=∈𝑀↾¯𝑀. So the situation consists of inner models ¯𝑀⊆𝑁⊆𝑀 and ⟨¯𝑀,∈𝑀⟩ is isomorphic to ⟨𝑀,∈𝑀⟩ in 𝑀. This is impossible unless all three models are identical, since a simple ∈𝑀-induction shows that 𝜋(𝑦)=𝑦 for all 𝑦, because if this is true for the elements of 𝑦, then 𝜋(𝑦)={𝜋(𝑥)∣𝑥∈𝑦}={𝑥∣𝑥∈𝑦}=𝑦. So ¯𝑀=𝑁=𝑀 and so 𝑁 and 𝑀 satisfy the same theory, contrary to assumption.
If the ordinals of ¯𝑀 are isomorphic to a proper initial segment of the ordinals of 𝑁, then a similar Mostowski collapse argument would show that ⟨¯𝑀,∈¯𝑀⟩ is isomorphic in 𝑁 to a transitive set in 𝑁. Since this structure in 𝑁 would have a truth predicate in 𝑁, we would be able to pull this back via the isomorphism to define (from parameters) a truth predicate for 𝑀 in 𝑀, contrary to Tarski’s theorem on the non-definability of truth.
The remaining case occurs when the ordinals of 𝑁 are isomorphic in 𝑁 to an initial segment of the ordinals of ¯𝑀. But this would mean that from the perspective of 𝑀, the model ⟨𝑁,∈𝑁⟩ has some ordinal rank height, which would mean by the Mostowski collapse argument that 𝑀 thinks ⟨𝑁,∈𝑁⟩ is isomorphic to a transitive set. But this contradicts the fact that 𝑀 has an injection of 𝑀 into 𝑁. ◻
It follows that although ZF and ZFC are equiconsistent, they are not bi-interpretable. Similarly, ZFC and ZFC+CH and ZFC+¬CH are equiconsistent, but no pair of them is bi-interpretable. And again with all the various equiconsistency results concerning large cardinals.
A similar argument works with PA to show that different extensions of PA are never bi-interpretable.




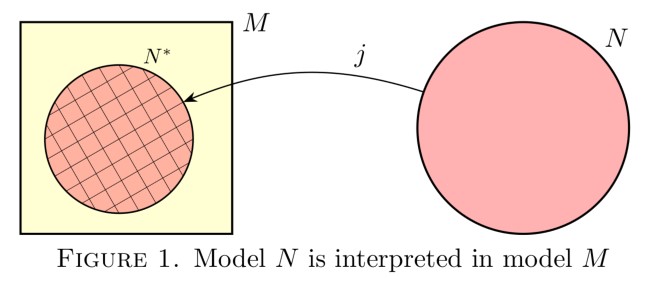



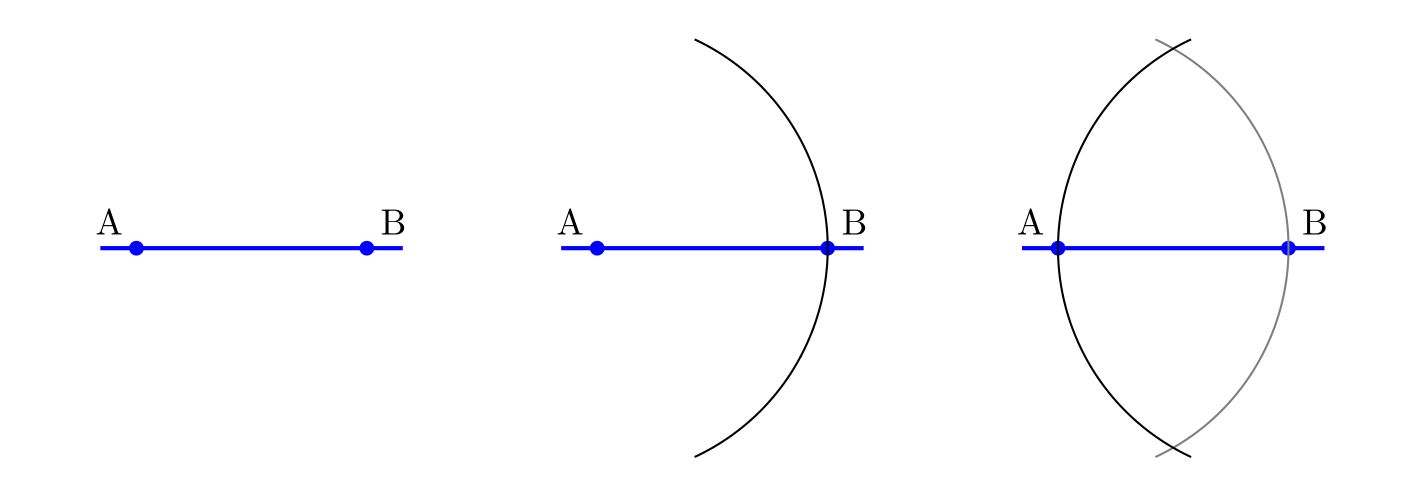


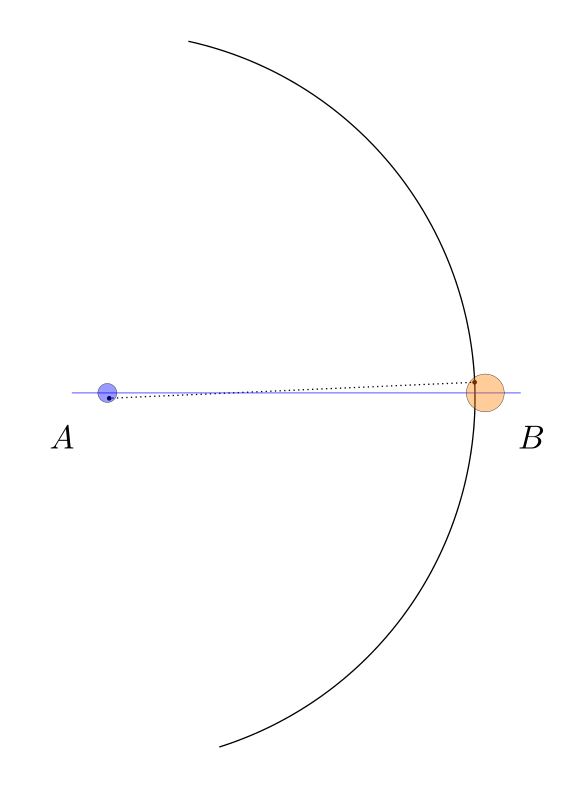
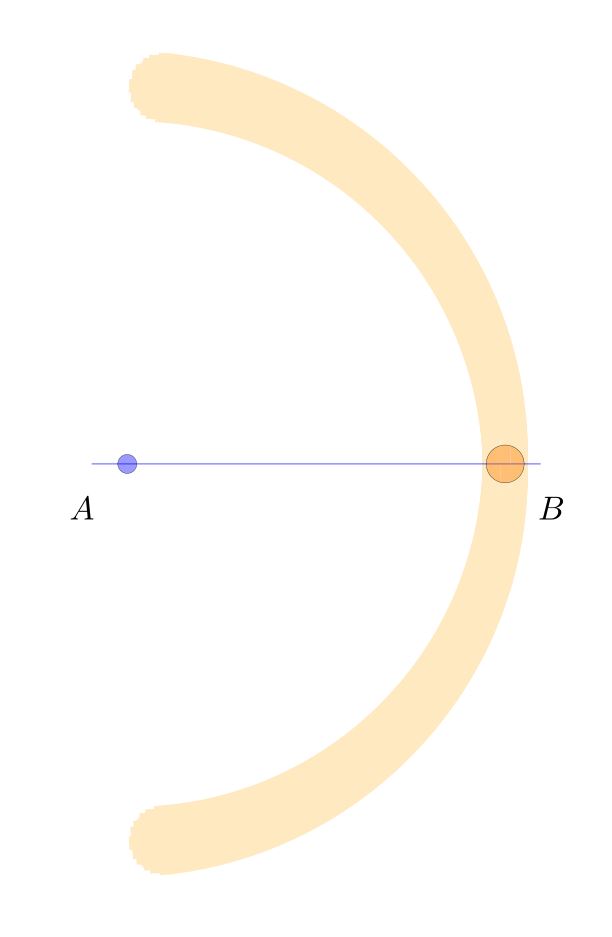





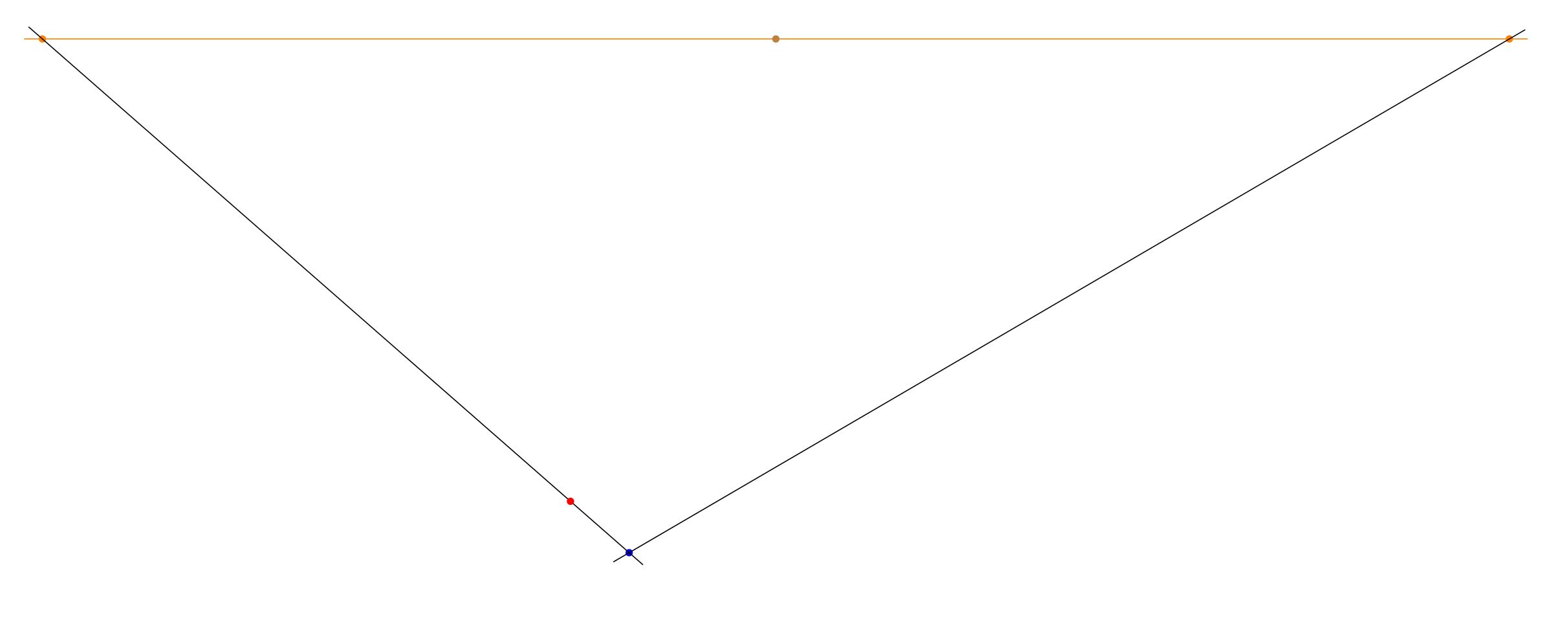


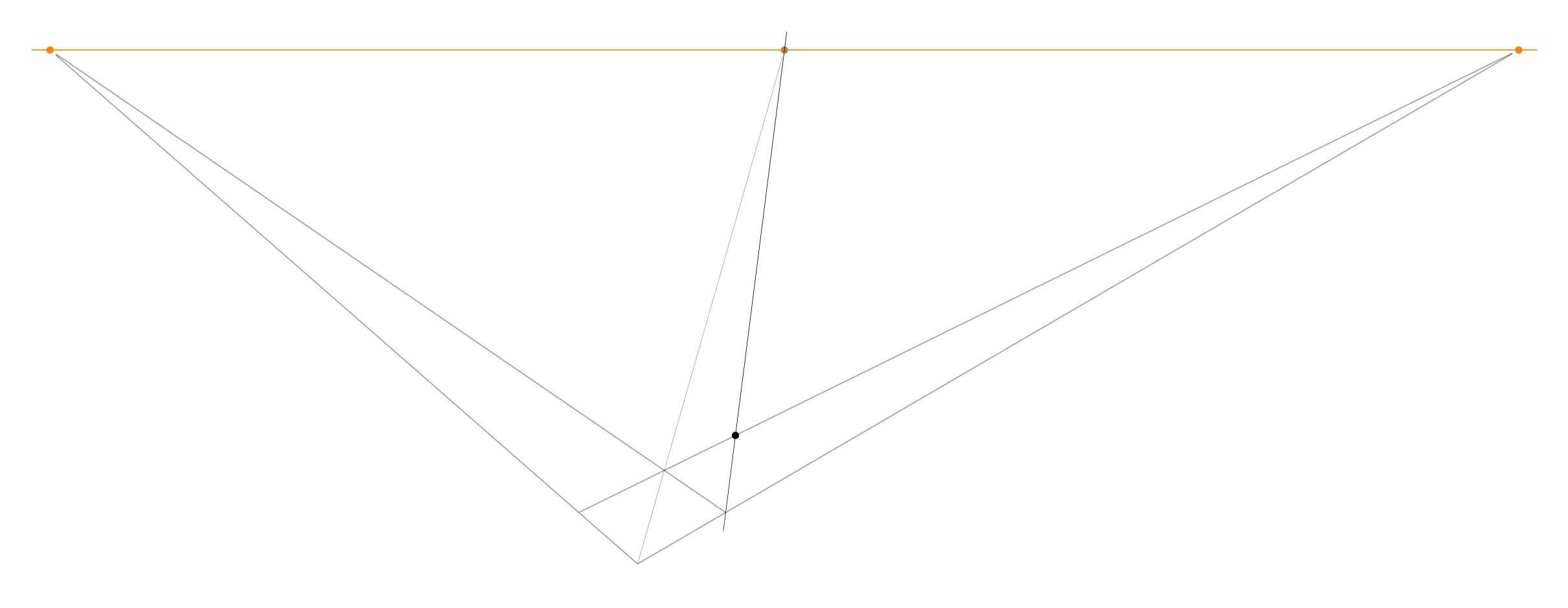


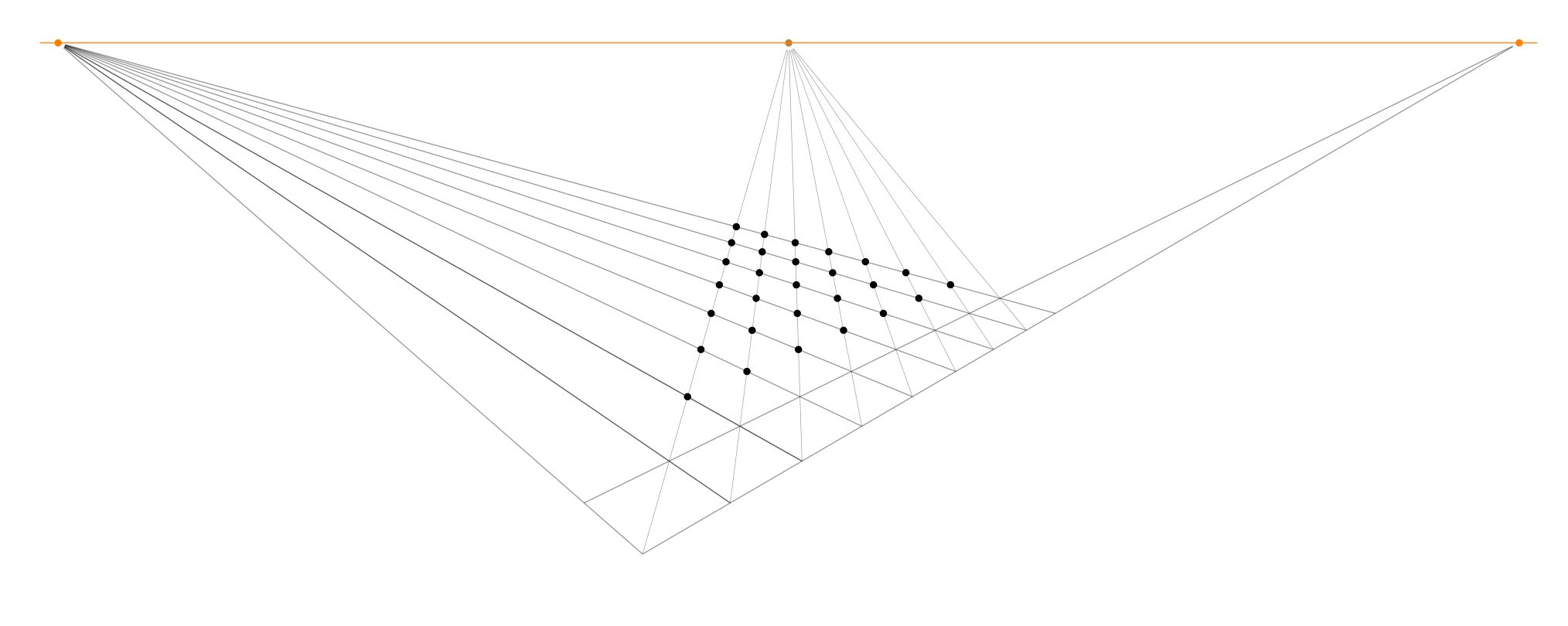

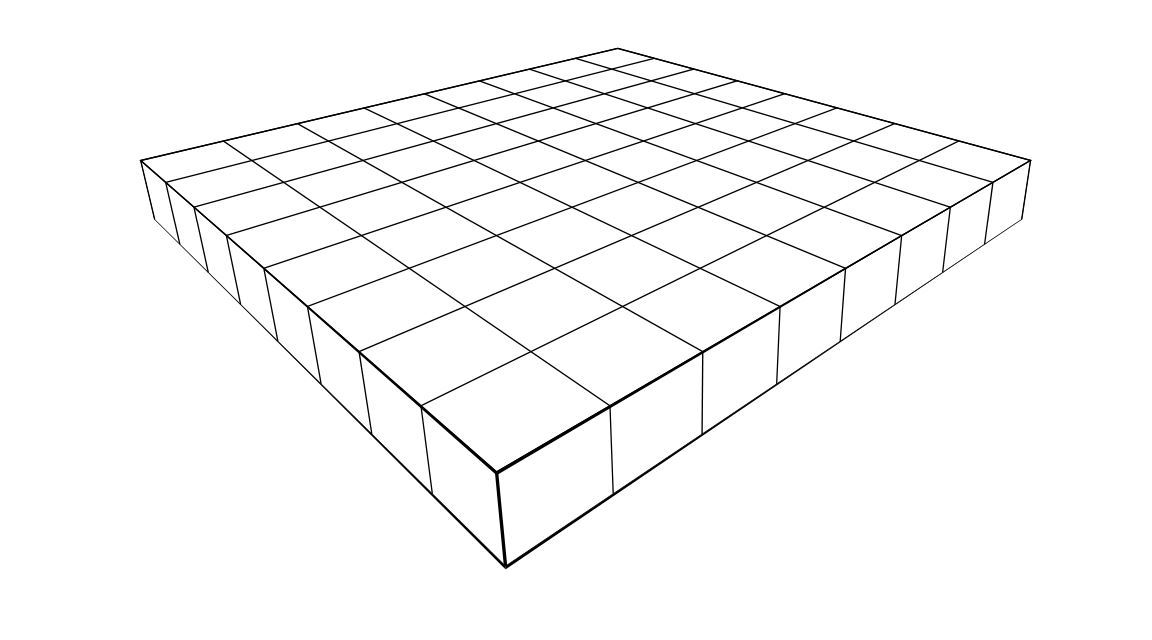




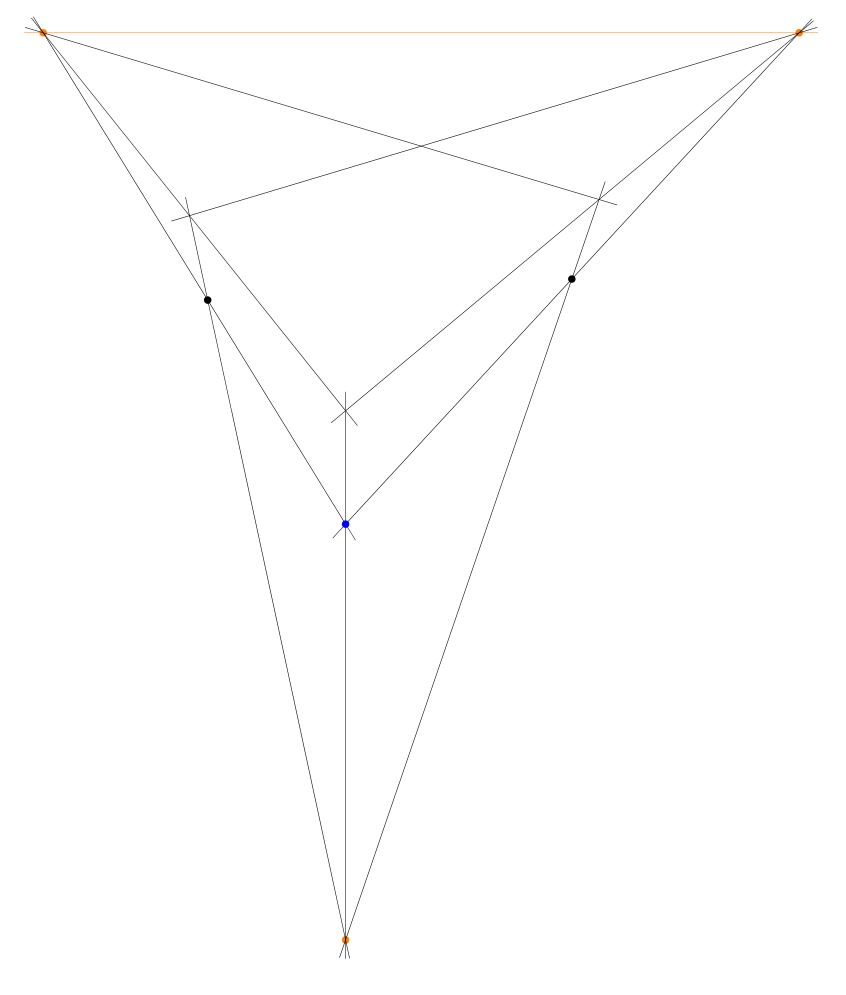



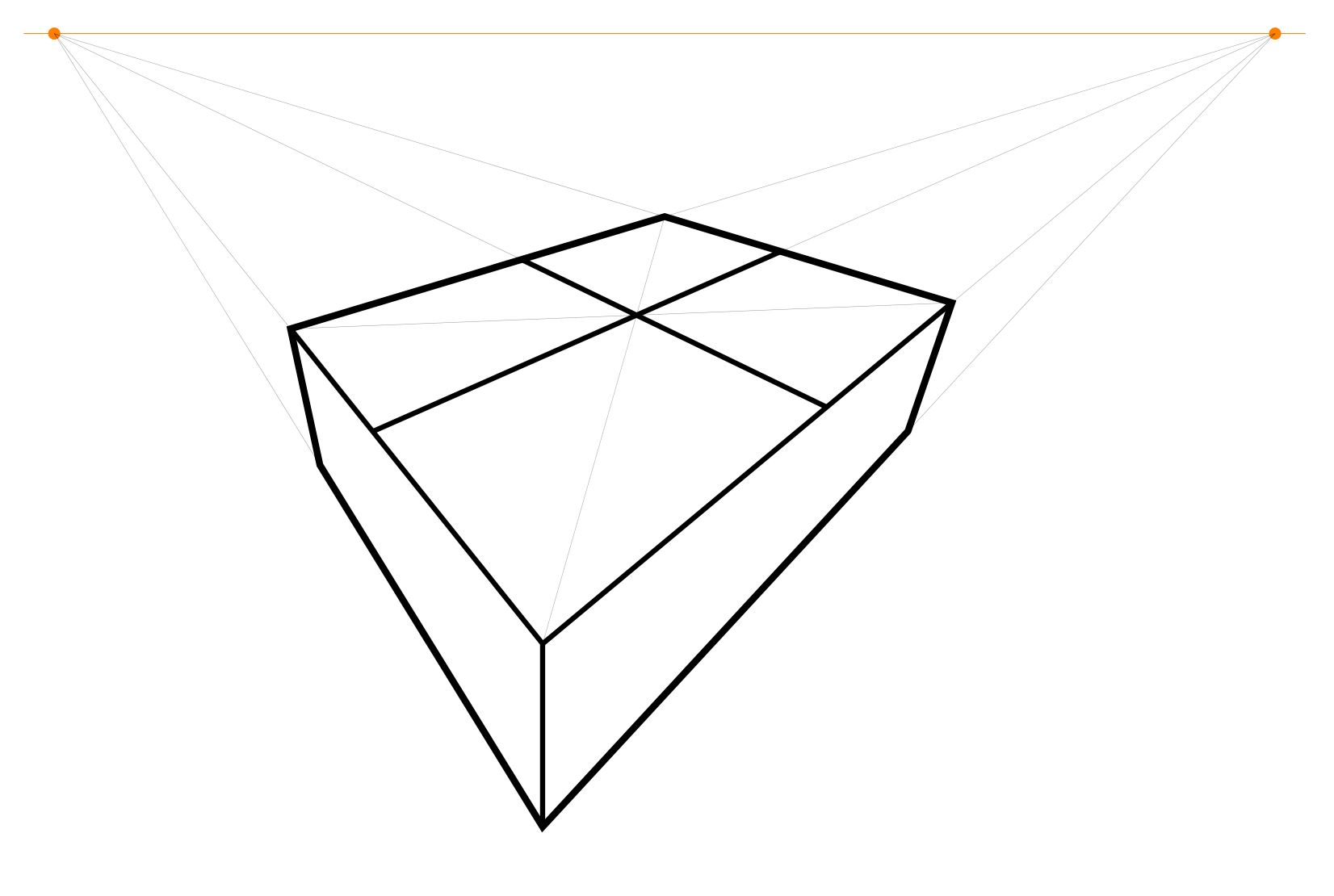

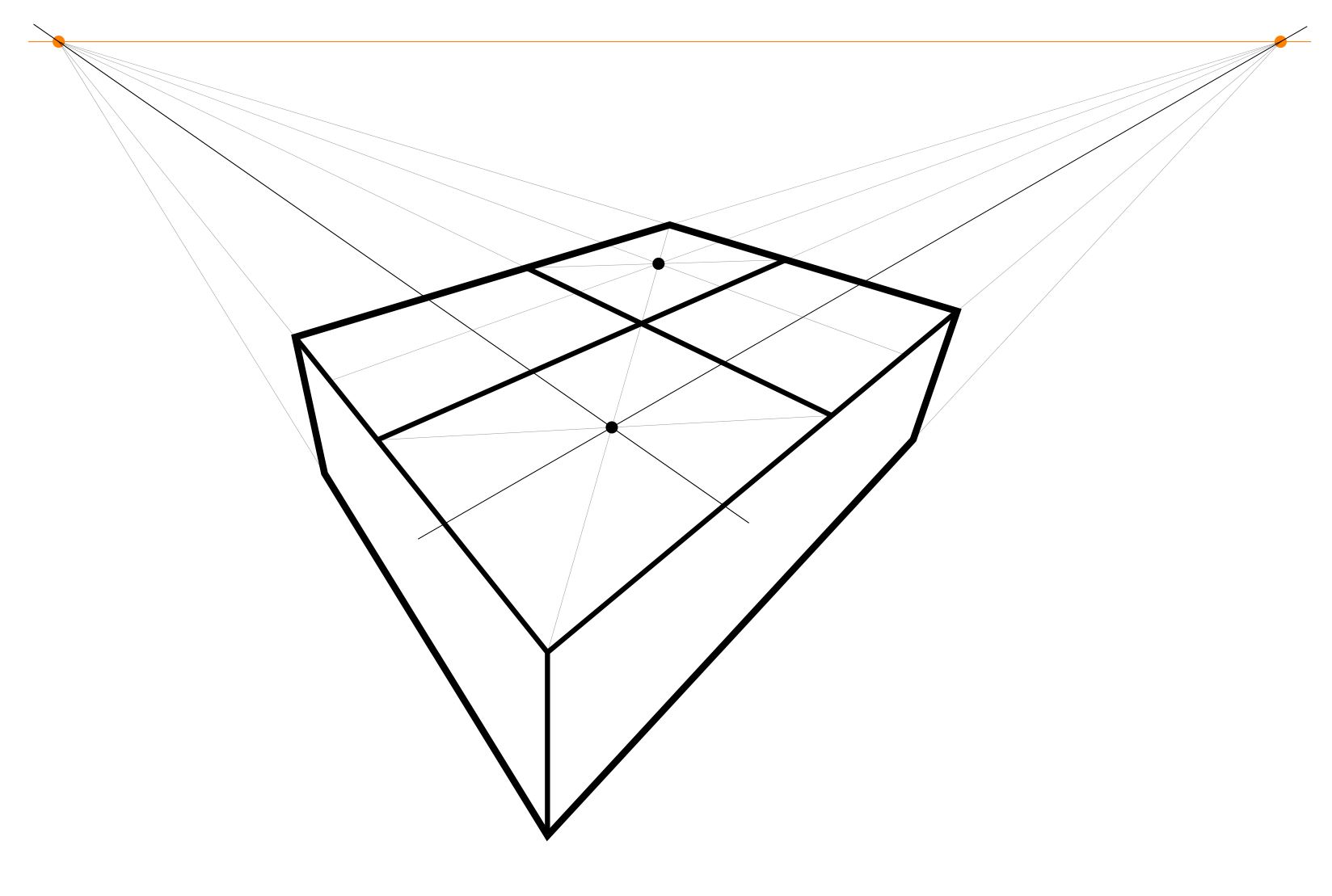
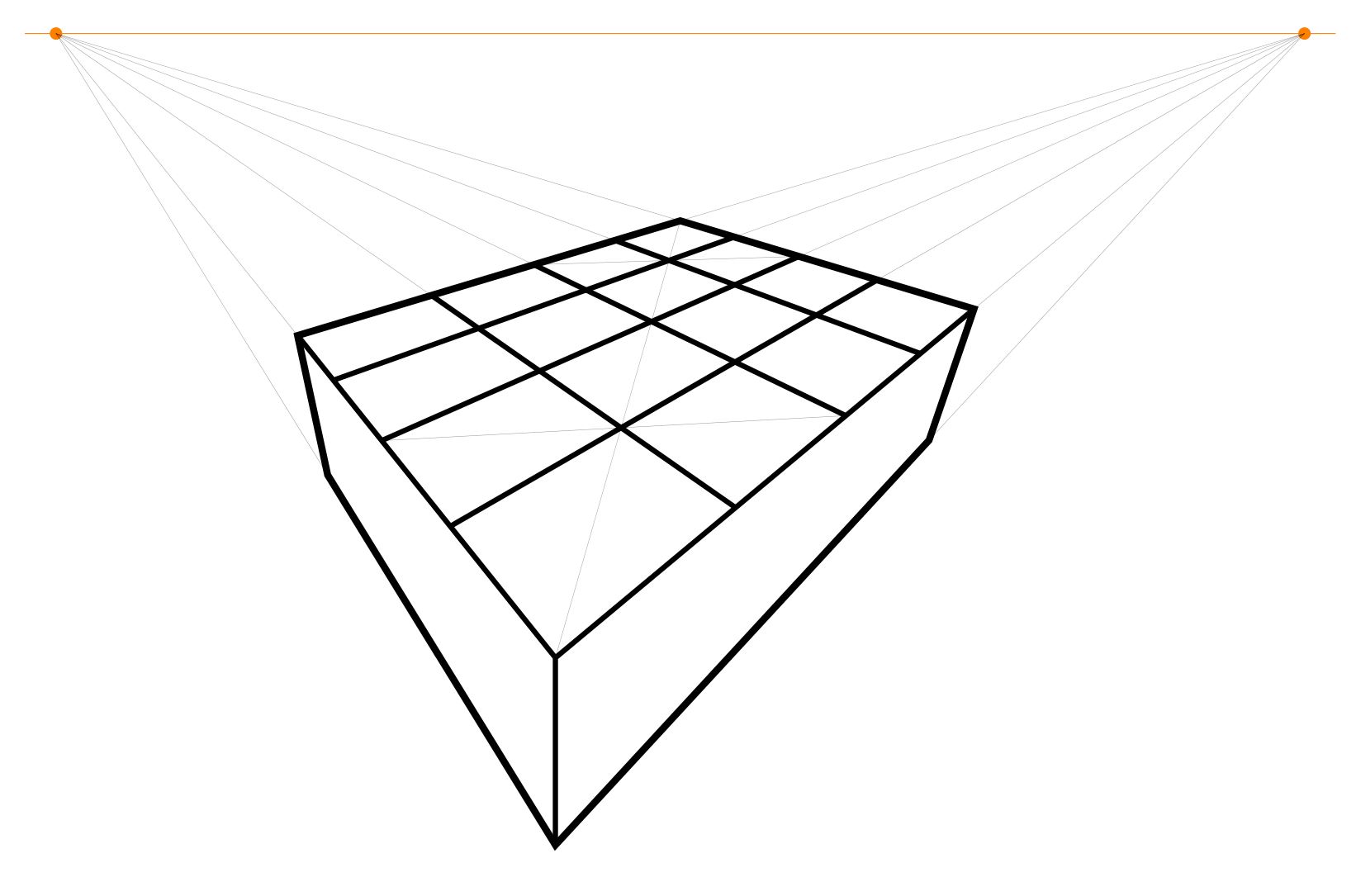



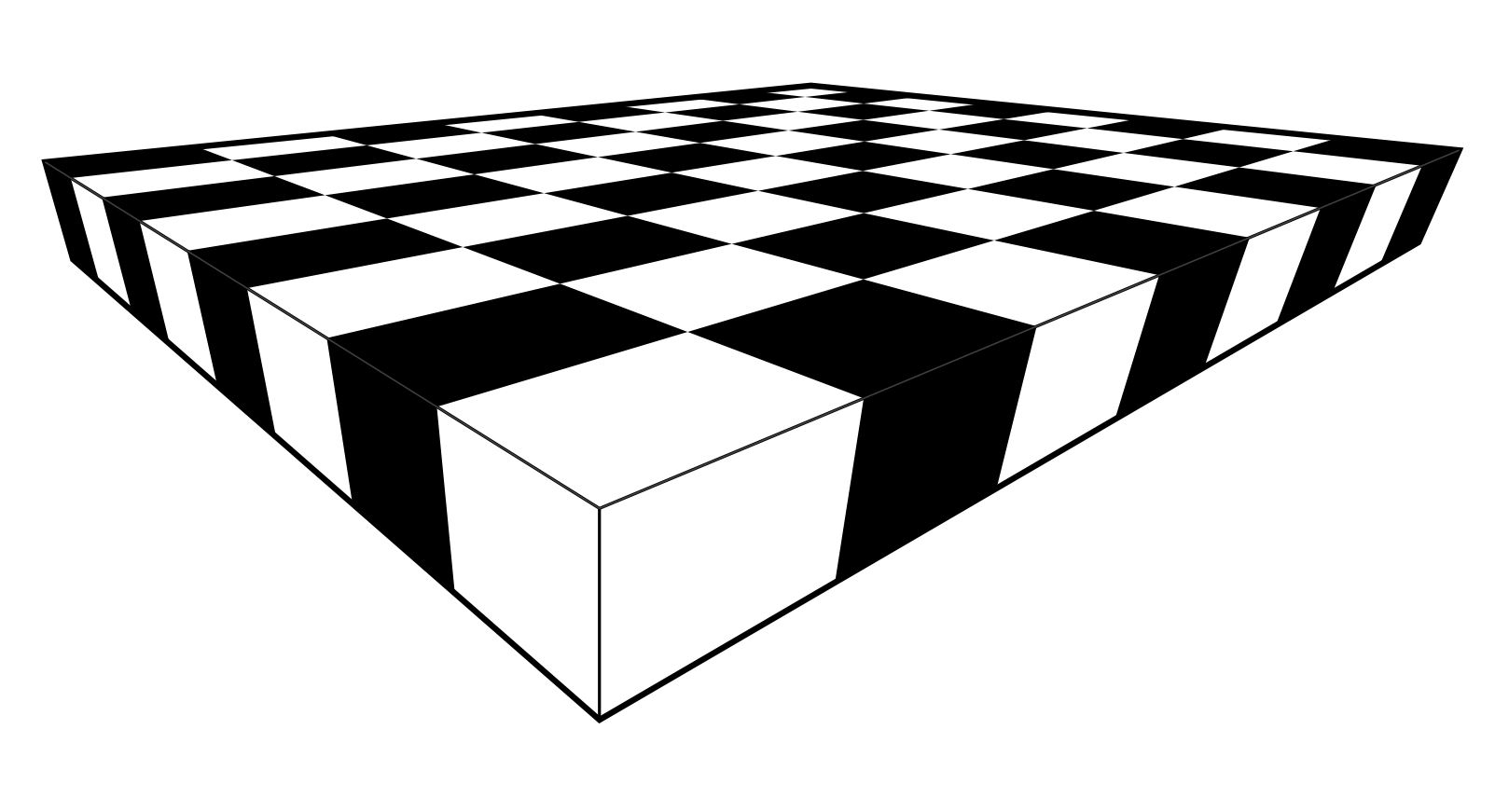

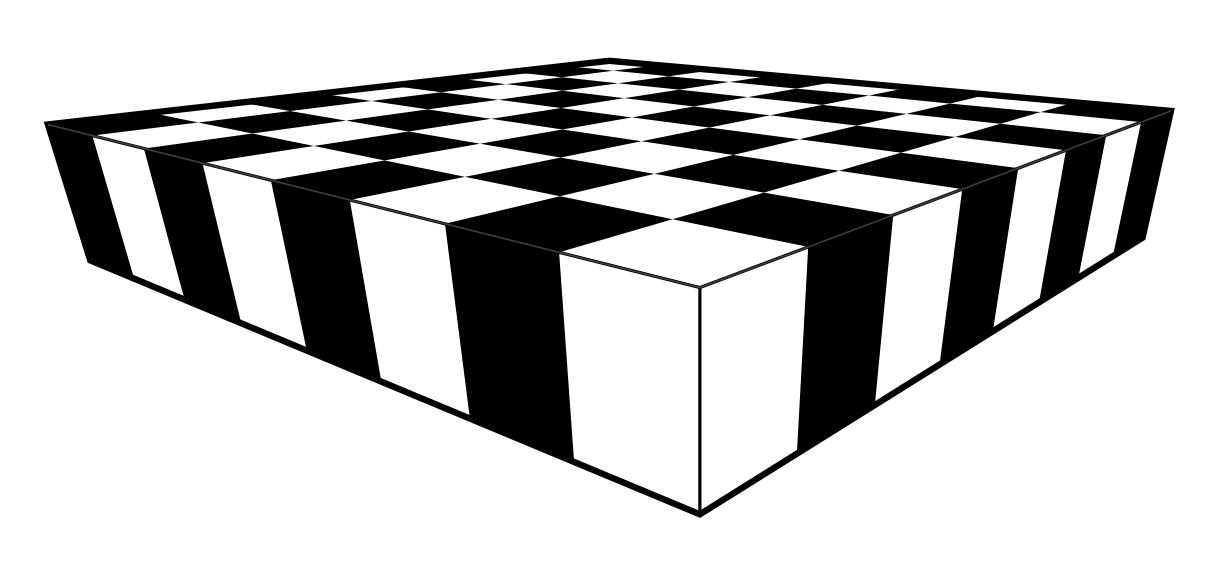
 [Public domain], via Wikimedia Commons")
 public domain image")




 ([1]) [Public domain], via Wikimedia Commons")
