Today I gave a lecture on what I call number sense, using a process of estimation and approximation in order to calculate various unknown quantities, including a few fantastical ones. How much coffee is made per day in New York City? Would it fill up the Statue of Liberty? Approximately how many babies are born in New York City each day? If you made a stack of quarters to reach the distance to the moon, what would the dollar-value be? If you piled those quarters in a heap, would it fit in Central Park? How much does the Empire State Building weigh?
These kinds of back-of-the-envelope calculations, in my view, have at their heart the idea that one can solve a difficult or seemingly impossible problem by breaking it into more manageable pieces. We don’t just pull a final answer out of the air, but rather make simplifying assumptions and informed estimates for related quantities that we are more familiar with or have knowledge about, and then use that information to derive a better estimate for the main quantity. For most of these questions, at the outset we may have little idea what would be a reasonable answer, but by the end, we gain some insight and find ourselves a little closer to the truth.
These kind of calculations are also known as Fermi estimations, in light of Fermi’s remarkable ability to make surprisingly accurate estimations on the basis of little or no hard data. The wikipedia page (thanks to Artie Prendergrast-Smith for mentioning this link in the comments) emphasizes that even in a case where the estimate is significantly off the true value, nevertheless we may still find value in the Fermi calculation, because it focusses our attention to the reasons for the divergence. In discovering which of the assumptions underlying our calculations was wrong, we come to a deeper understanding of the true situation.
In the lecture, I began with some very easy cases. For example, how many seats were in the auditorium? The students estimated that there were approximately 12 seats per row and about 10 rows, so 120 seats in all. How old was one of the students, in seconds? Well, he was 18 years old, and so we could simply multiply each year by 365 days, times 24 hours per day, times 60 minutes per hour, times 60 seconds per minute, to get
$$18\times 365\times 24\times 60\times 60\approx 600,000,000 \text{ seconds}.$$
One student objected about leap days, since 365 should be 365.25 or so. But I pointed out that this difference was not as important as it might seem, since already we had made far larger rounding assumptions. For example, the student was not exactly 18 years old, but 18 years old and some several months; by using 18 years only, we made a bigger difference in the answer than caused by the leap-day issue, which would be a difference of only five days or so over 18 years. For the same reason, we should feel free to round the numbers to make the calculation easier. We are aiming at a ballpark estimate rather than an exact answer.
Let’s now do some more interesting cases.
 Coffee in New York. How much coffee is made each day in New York? Would it fill the Statue of Liberty? First, let me say that I really don’t have any definite information about how much coffee is made each day in New York, and I fear that my own coffee-obsessed perspective will lead me to over-estimate the amount, but let’s give it a try. New York City has a population of approximately 10 million people. Some of those people, like myself, drink a large amount of coffee each day, but many of the others do not drink coffee at all. I would think that a sizable percentage of the NYC population does drink coffee, perhaps as much as a third or even half consumes coffee daily. Many of those coffee-drinkers have more than one cup per day, and also surely more coffee is made than consumed. So it seems reasonable to me to estimate that we have approximately one medium cup of coffee per person on average per day in New York. Basically, we’re saying that the heavy coffee drinkers and the made-but-not-sold coffee approximately makes up for those who abstain, making the average about one cup per person. So we are talking about 10 million cups of coffee per day. A medium cup of brewed coffee at Starbucks is I think about 12-16 ounces, a little less than a pint, and so let’s say about 3 cups per liter. This amounts to roughly 3 million liters of coffee.
Coffee in New York. How much coffee is made each day in New York? Would it fill the Statue of Liberty? First, let me say that I really don’t have any definite information about how much coffee is made each day in New York, and I fear that my own coffee-obsessed perspective will lead me to over-estimate the amount, but let’s give it a try. New York City has a population of approximately 10 million people. Some of those people, like myself, drink a large amount of coffee each day, but many of the others do not drink coffee at all. I would think that a sizable percentage of the NYC population does drink coffee, perhaps as much as a third or even half consumes coffee daily. Many of those coffee-drinkers have more than one cup per day, and also surely more coffee is made than consumed. So it seems reasonable to me to estimate that we have approximately one medium cup of coffee per person on average per day in New York. Basically, we’re saying that the heavy coffee drinkers and the made-but-not-sold coffee approximately makes up for those who abstain, making the average about one cup per person. So we are talking about 10 million cups of coffee per day. A medium cup of brewed coffee at Starbucks is I think about 12-16 ounces, a little less than a pint, and so let’s say about 3 cups per liter. This amounts to roughly 3 million liters of coffee.
Would it fill the Statue of Liberty? The statue itself is, I estimate, about twenty stories tall, counting the base, and if each story is 15 ft, or 5 meters, that would mean 100 meters tall, counting the base. But I think that the base is about half the height, so let’s say 50 meters for the actual statue itself. I’ve never been inside the statue, but my students say that it is about 10 meters across inside, a little more at the bottom than near the top. If we approximated it as a rectangular solid, that would give a volume of $10\times 10\times 50$ cubic meters, or 5000 cubic meters. But since the statue tapers as you go up, particularly in the arm holding the torch, it really is more like a cone than a rectangular solid, and so we should divide by three. But let’s divide just by two, because she isn’t quite as tapered as a cone. So the Statue of Liberty has a volume of approximately 2500 cubic meters. One cubic meter can be thought of as a 10 by 10 by 10 array of little 10cm cubes, and each of those is exactly one liter. So a cubic meter is 1000 liters, and therefore the Statue of Liberty has a volume of $2500\times 1000=2.5$ million liters. But since we had 3 million liters of coffee, the answer our calculation arrives at is: Yes, one day’s worth of New York coffee would fill up the Statue of Liberty!
Well, we do not have perfect confidence in our estimates and assumptions — for example, perhaps there are many fewer coffee drinkers in New York than we estimated or perhaps we underestimated the volume of the Statue of Liberty. Since the estimated volumes were of basically similar magnitudes, we aren’t really entitled to say that definitely the coffee would fill up the Statue of Liberty. Rather, what we have come to know is that those two volumes are comparably similar in size; they are in the same ballpark.
Elevator trips. While riding downtown last weekend with my son on the subway, a crowded 4 train, we overheard the group standing next to us talking about elevators. One lady said, “My elevator company serves as many elevator trips in New York City in five days as the population of the entire world,” and the rest of her group, impressed, nodded affirmatively in reply. But my thoughts, upon hearing that, were to make a quick calculation. Suppose all 10 million NYC residents rode an elevator 10 times every day, which is way too high (probably one trip per person per day is more reasonable, since many people live and work in buildings without elevators). Even in this extreme case of ten trips per person per day, it would mean only 100 million trips total per day, or 500 million trips over 5 days. This is much less than the world population, and so no way is that person’s claim true, especially since there are also many elevator companies. I thought of mentioning my calculation to those people on the subway, but decided against it. Walking out of the subway in the East Village, however, I asked my son (14 years old) whether he heard those people talking about elevators, and he replied, “Oh, yes, and when they said that, I calculated it in my head: no way is that true.” He then proceeded to explain his calculation, similar to mine. Yay, Horatio!
The Chicago marathon. In the run-up to the Chicago marathon this year, on a route that would wind through the windy city streets, Newsweek magazine reported, “Chicago Marathon organizers expect 1.7 million fans to line the route this year.” (Thanks to the critical math commentary of Mark Iris for bringing this example to my attention.) The organizers had emphasized the economic impact of these spectators, many of whom would presumably be eating in Chicago restaurants and staying at Chicago hotels. But is this a reasonable number?
Let’s calculate. A marathon is approximately 26 miles, and the route has two sides for spectators, so let’s round it to 50 miles of spectator viewing spots. Each mile is about 1800 yards, so we have $50\times 1800=90000$ yards of viewing spots. Each spectator, standing shoulder-to-shoulder, with all their stuff, takes up about a yard of space. So if the marathon was lined on both sides for the entire route with spectators standing shoulder-to-shoulder, this would amount to about 90,000 spectators. In order to have 1.7 million spectators, therefore, they would have to be lined up behind each other. But even if the spectators were 10 people deep on each side for the entire route, which is a vast crowd, it would still amount only to 900,000 people. We would have basically to double this to get to 1.7 million. So, if the live event really had 1.7 million spectators lining the route, then it would mean that the race was lined 20 people deep on each side for the entire route. No way is this number correct! I have never had the chance to attend the Chicago marathon, but at the New York marathon, which I assume is comparable, I know that while there are thick crowds at the finish line in Central Park and at some of the other prominent or especially interesting race locations, most of the rest of the route is much thinner, and at the typical nothing-special location, one could expect easily to have a front-row spot.
 How many bricks on the college campus? Our campus, covered with some lovely woods and green meadows, has a number of brick Georgian buildings. Most of these are the same standard size as the mathematics department, but there are also some larger buildings such as the library, the performing arts center, the campus center and the gymnasium. At my lecture, the students and I agreed that altogether it amounted to about 30 buildings of the size of the math building. This building is approximately 30 meters by 70 meters, which would make a perimeter of 200 meters, but because the building has wings and is not purely rectangular, let’s add another 100 meters for the folds in the walls, so about 300 meters around the base of the building. The building is two stories tall, about 10 meters tall, making the area of the walls about 3000 square meters. Of course, there are windows and doors that cut out of these walls, but let’s say that they are approximately accounted for by the extra bricks used in the trimming flourishes at the corners and top of the building. So we have 3000 square meters of brick. Each brick is approximately 10 cm by 30 cm, and so one square meter of brick would have about ten rows of a little more than three bricks across, or about 20 bricks. So each building has about $3000\times 20=60,000$ bricks. And with 30 buildings, this amounts to $30\times 60,000=1,800,000$ bricks in the buildings on campus. There are also some bricks in the central fountain, a few small brick walls and some bricks lining some of the walkways. So let’s add another ten percent for those extra bricks, arriving at about 2,000,000 bricks on campus in all.
How many bricks on the college campus? Our campus, covered with some lovely woods and green meadows, has a number of brick Georgian buildings. Most of these are the same standard size as the mathematics department, but there are also some larger buildings such as the library, the performing arts center, the campus center and the gymnasium. At my lecture, the students and I agreed that altogether it amounted to about 30 buildings of the size of the math building. This building is approximately 30 meters by 70 meters, which would make a perimeter of 200 meters, but because the building has wings and is not purely rectangular, let’s add another 100 meters for the folds in the walls, so about 300 meters around the base of the building. The building is two stories tall, about 10 meters tall, making the area of the walls about 3000 square meters. Of course, there are windows and doors that cut out of these walls, but let’s say that they are approximately accounted for by the extra bricks used in the trimming flourishes at the corners and top of the building. So we have 3000 square meters of brick. Each brick is approximately 10 cm by 30 cm, and so one square meter of brick would have about ten rows of a little more than three bricks across, or about 20 bricks. So each building has about $3000\times 20=60,000$ bricks. And with 30 buildings, this amounts to $30\times 60,000=1,800,000$ bricks in the buildings on campus. There are also some bricks in the central fountain, a few small brick walls and some bricks lining some of the walkways. So let’s add another ten percent for those extra bricks, arriving at about 2,000,000 bricks on campus in all.
Positive test result for a rare disease. Suppose that as part of your check-up, your doctor randomly administers a clinical test for a certain rare medical condition. The test is 99 percent accurate, in terms of false positives and false negatives, in the sense that 99 percent of people taking the test have an accurate result with the test. Suppose also that the disease itself is rare, held by only one in a million people. If your test comes back positive, what is the likelihood that you actually have the disease?
This is a subtle question. It might seem to make sense initially that there is a 99 percent chance that you have the disease, since that is the accuracy of the test. But this isn’t actually right, because it doesn’t account for the fact that the disease itself is extremely rare, and so the total number of false positives will actually far outweigh the true positive results. For example, suppose that one million people take the test. About one of these people actually has the disease, and that person is 99 percent likely to test positive. So we expect about one true positive result. And for the others, who don’t have the disease, 99 percent of them will test negative. In other words, about 990,000 people will test negative. The remaining 10,000 people, however, one percent of the total, will have false positive results! So you are in this group of 10,000 people who tested positive, with only one of them actually having the disease. So the odds that you actually have the disease are only about one in ten thousand.
Quarters to the moon. How many quarters would you have to stack to reach the moon? How much would it be worth? how much would it weigh? More than the earth? More than the Empire state building? If you put all those quarters into a pile, would it fit in Central Park?
Well, OK, the question is a little absurd, and there are all kinds of problematic issues: we couldn’t ever actually make such a tower of quarters, as it would topple over; it doesn’t make sense to build a tower to the moon, since the moon is in orbit around the earth and it is moving; the quarters would begin to orbit the earth themselves, or fall back down to the earth or to the moon. But let’s just try to ignore all those problematic issues, and just try to answer how many quarters it would take to make a pile that high.
How far is the moon? I don’t really know, and we could look it up to see what the astronomers say about it, but that would go against the back-of-the-envelope spirit of these problems. So I am just going to use two facts that I picked up years ago: first, I know that the speed of light is about 300,000 km per second; and second, I happen to know that it takes radio signals traveling at the speed of light about one second to get to the moon (eight minutes to the sun), and so the moon is about one light-second away. I remember this fact from having learned it in my childhood, because it was important in a science fiction story I had read, in which radio communication from earth to the moon base had a two-second delay: you send a message, it takes a second to get there, and then a second for the answer to come back. So the moon is one light second away, and light travels 300,000 km in one second. So the moon is about 300,000 kilometers distant (actual value: 387400 km).
Let’s now stack up the quarters. By eyeballing a quarter I had in my pocket, I’d say each quarter is about 2 mm thick, which means 500 quarters per meter, or 500,000 quarters per km. So altogether, we have $300,000\times500,000=150,000,000,000$ many quarters in the stack. A hundred and fifty billion quarters to the moon! It takes four quarters to make a dollar, so that is worth about $40 billion dollars, which might be less than you would have expected initially.
Let’s put those quarters in a big pile, packed as tightly as possible. Each quarter is a little over 2 cm in diameter, and so the volume of the rectangular solid bounding the quarter is a little more than 2 cm by 2 cm by 2 mm, or about 800 cubic mm, which we can round up to 1 cubic centimeter. That makes sense, because we can imagine folding a quarter up into a little 1 cm cube. So 1000 quarters takes up about one liter. Thus, our quarters-to-the-moon have a volume of about 150 million liters. There are 1000 liters in a cubic meter, and so this is 150,000 cubic meters. Since a cube 10 meters on a side, has a volume of 1000 cubic meters, we can fit all those quarters into 150 such cubes. I can easily imagine a giant art installation, with 150 such 10 meter cubes placed in Sheep Meadow in Central Park. They would definitely fit.
How much would the quarters weigh? Some of the students in my lecture had worked as cashiers, and so they were familiar with quarter rolls from the bank, which fit in your palm and have ten dollars worth of quarters, or forty quarters. I can imagine a quarter roll in one hand balancing the weight of a half-pound of gouda cheese at the deli in my other hand. So 40 quarters is .5 pound, which makes 100 quarters about 2.2 pounds, which is about 1 kg. We had 150 billion quarters, which is 1.5 billion times 100 quarters, so 1.5 billion kilograms.
Since we already imagined the quarters in Sheep Meadow in those 150 large boxes, clearly they weigh far less than the earth and perhaps comparable to the Empire State Building.
How much does the Empire State Building weigh? After posing this question, I found out that it is also evidently a famous Google interview question, and you can easily find other blog posts about it. But let me tell you how I thought about it. The Empire State Building is about 100 stories tall, and if we assume 12-15 feet per floor, or about 4 meters, this makes the total height (without tower) about 400 meters. The CUNY Graduate Center where I work is across the corner on Fifth Avenue and 34th street, and I have walked past the Empire State Building many times. I estimate that the base is about 75 meters on Fifth Avenue by 150 meters on 34th Street. But because of the step-backs, the middle part of the tower is considerably less than that, probably 30 by 80 near the top. Let’s say the average cross section of the building is 50 by 100 meters. Now, how much does that weigh? Of course, there is a lot of steel and masonary in the floors and walls, and concrete floors, and also all the contents of the building, with desks and paper files and books and interior walls and doors. Those things are heavy. I really have no idea how much those things weigh, but let me imagine that we build a virtual copy of a complete floor from the Empire State Building, without any of those floor beams or concrete or desks or walls or anything, and instead we flood that virtual room with water, until it has the same weight. Of course, the metal and concrete and masonary is much heavier than water, but the actual space is mostly empty air. How much water would it take to have the same weight? Well, let me just guess that we’d have to flood the virtual room about one-quarter deep with water to have the same weight as the actual materials. At 50 by 100 meters by 4 meters tall for each floor, this would mean a pool of water 50 by 100 meters, one meter deep, for a volume of 5000 cubic meters of water. We already said that one cubic meter of water is 1000 liters, each of which weighs one kilogram, so we are talking about $5000\times 1000$ kilograms or 5 million kilograms per floor. With 100 floors, this is 500 million kilograms, or 500,000 metric tons. So according to this estimate, the Empire State Building with all its contents weighs about 500,000 metric tons.
So it weighs less than the quarters to the moon (1.5 billion kilograms) —the Empire state building weighs about one-third as much as the quarters to the moon — but these two quantities are in the same ball park.
How many babies are born each day in New York City? The population of New York is approximately ten million people. And those people live about 70 years. Let’s imagine spreading those births out uniformly over the 70 year period. That means one million people born in 7 years. This is about 150,000 people born in one year, which is about 3000 births per week, or about 400 births per day. This estimate would be accurate if the city population were in a steady state, with births balancing deaths, but of course the population is increasing. On the other hand, most of that increase is from people moving here, not just being born here. But then again, the people moving to New York I expect are mainly young adults looking for a career, and so they will contribute to a heightened birth rate as they have children. Shall we add 25 percent more to account for the fact that the city is growing and not in a steady state? In that case, our estimate is that there are about 500 births each day in New York City.
There is an endless supply of such questions that can be calculated. I have been talking about them in the lectures for my course Math for Liberal Arts, an undergraduate course aimed at non-math students at my college. In this course, we are fairly free to cover some imaginative topics, and I’ve covered some game theory, some elementary graph theory, a little bit logic, and now this number sense topic, which I use to try to develop the students ability to attack a technical problem by breaking it down into more managable problems. But meanwhile, I also look upon it just as plain fun.
So here are a few more questions that you might enjoy thinking about. And please make your own.
- What is the total volume of air that you have breathed in your lifetime? If you filled a balloon with all your hot air, how big would it be?
- If you used that balloon as a hot-air balloon (with the hot air at your body temperature), would it have enough bouyency to lift you and all your possessions? See my post A lifetime of hot air for a detailed answer.
- How many NYC metro cards exist? (Each lasts about a year or two; they get thrown out, but still exist in the landfill; the system has used metro cards for about twenty years; there is a large stock of new not-yet-used cards.)
- How many doorknobs are there in your building?
- How many subway tiles are there in the NYC subway system?
- How many riders were on my crowded 4 train downtown this morning?
- How many lightswitches are there on your university campus?
- How much water does NYC use each day?
- What are the odds that you drank a molecule of water that was once also drank by Julius Caesar?
- How many people have there been? What fraction are currently alive?
Please try to figure them out, and post your solutions in the comments below!


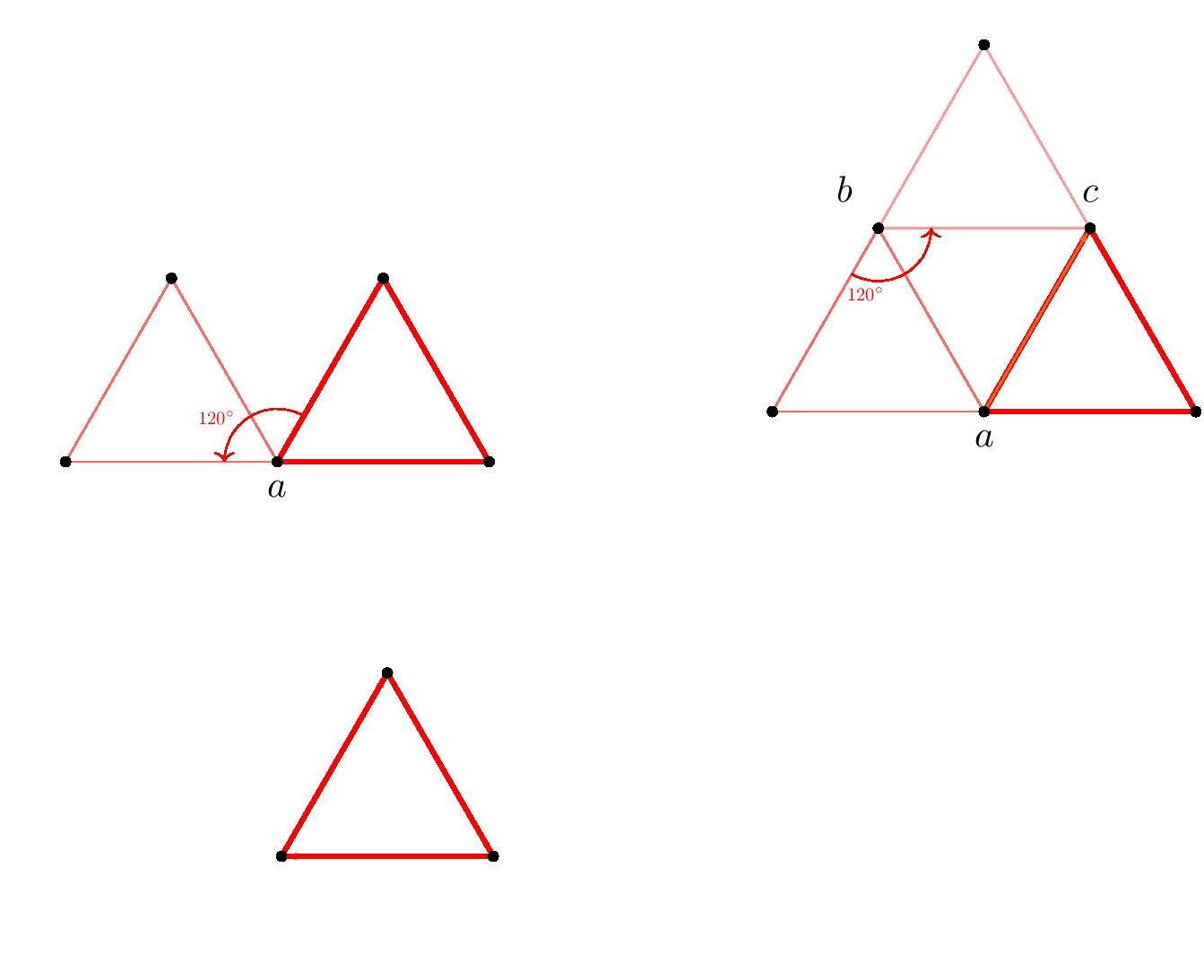
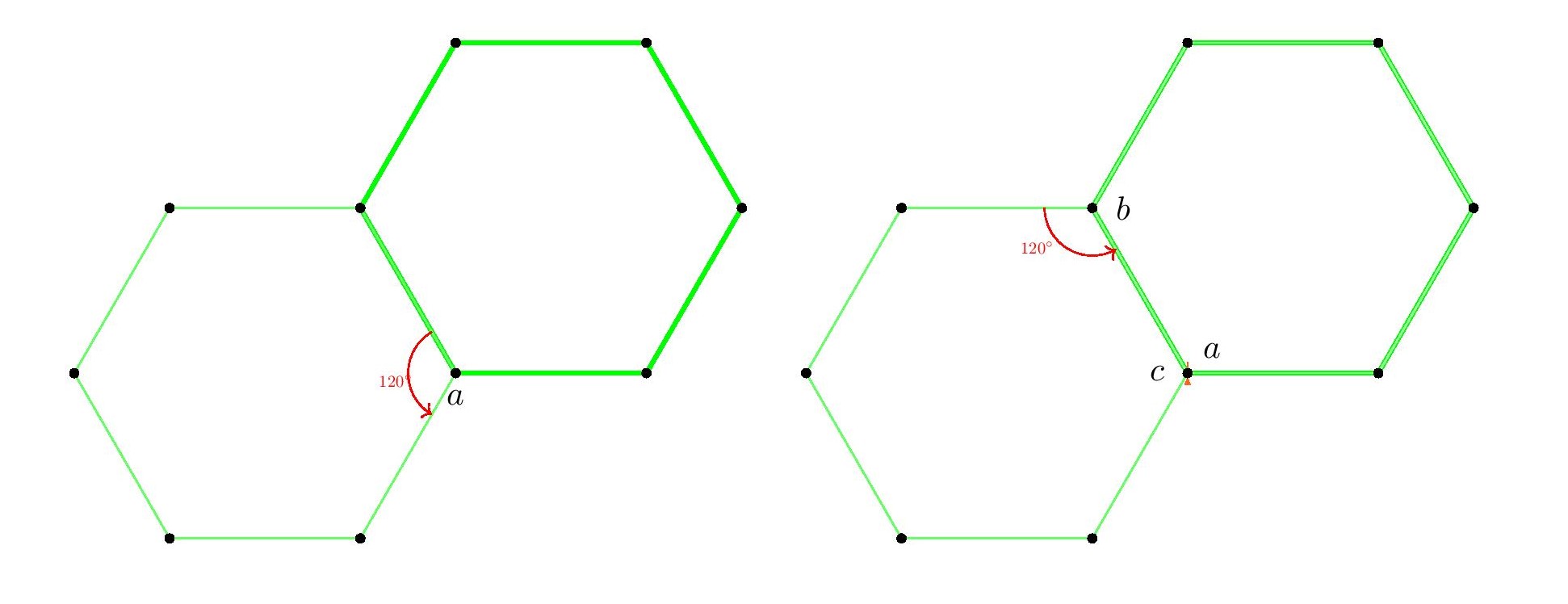
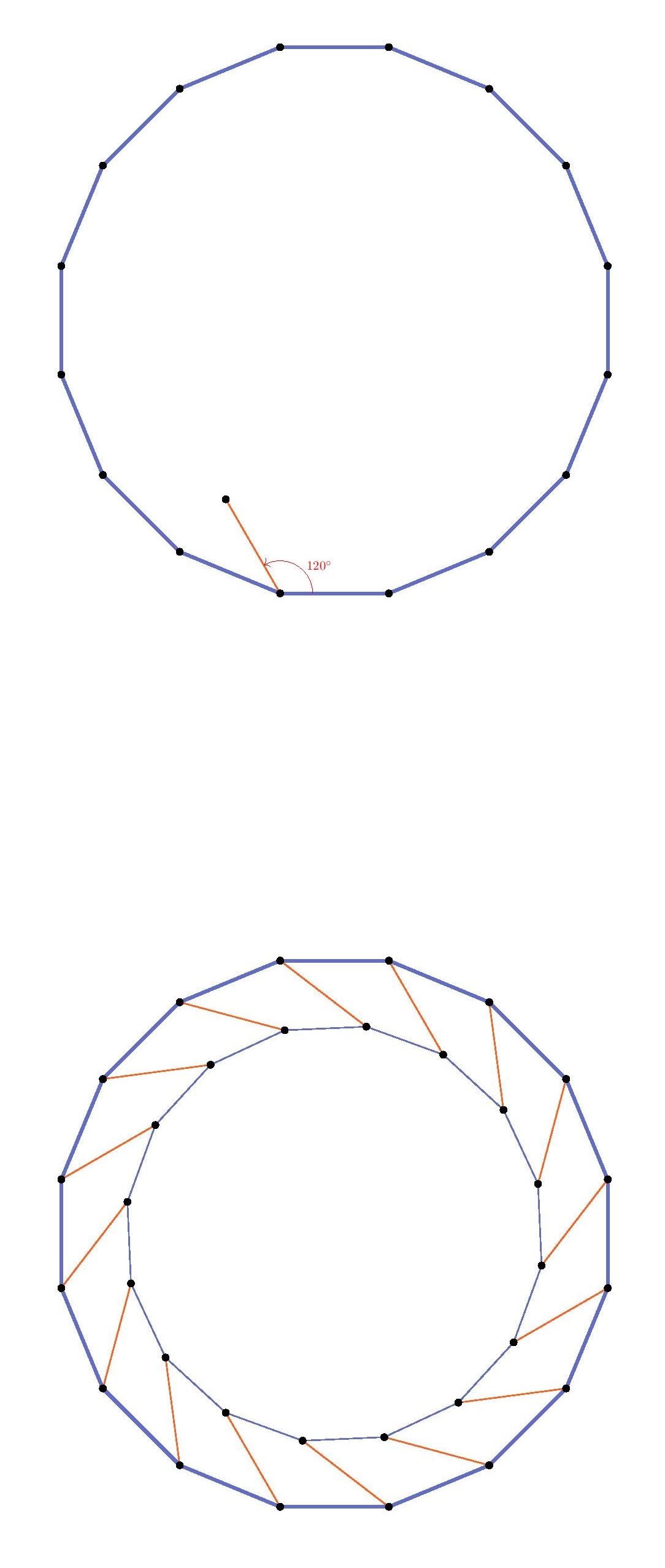
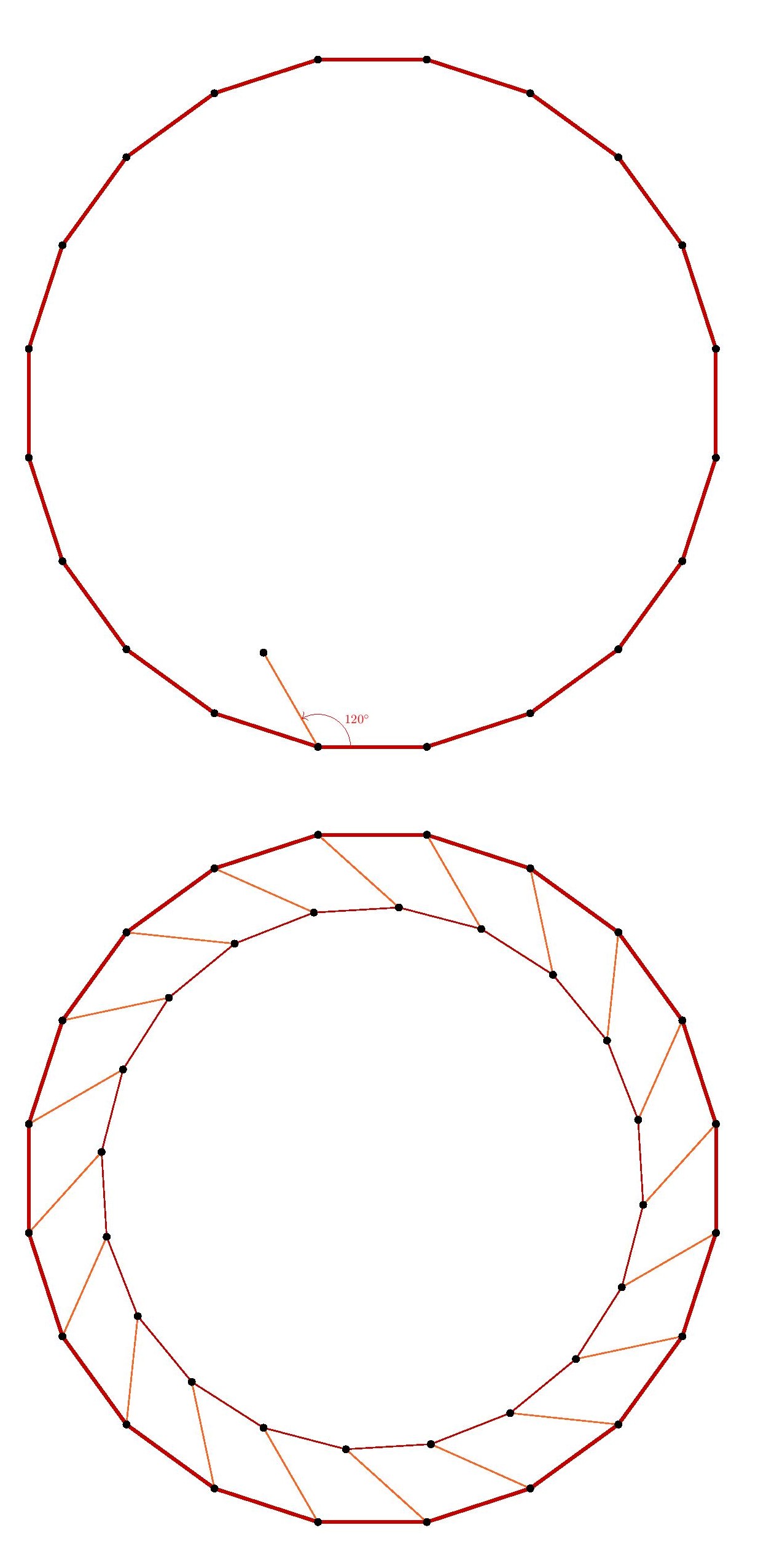
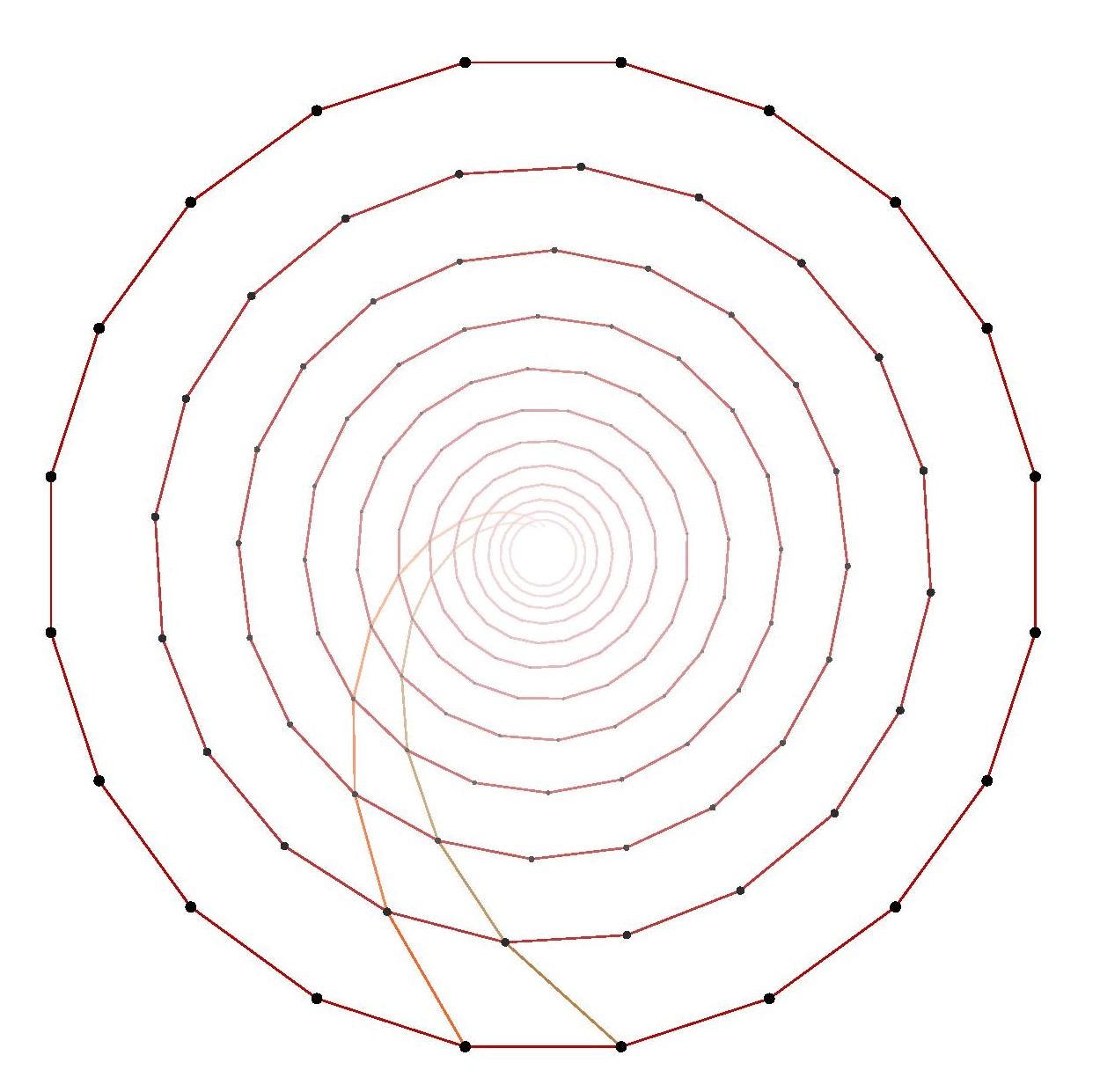
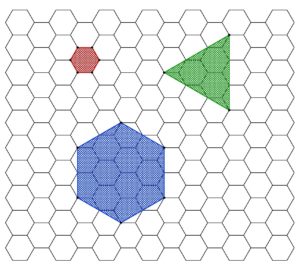
 Indeed, the triangular and hexagonal lattices are each refinements of the other, so they will allow exactly the same shapes arising from lattice points.
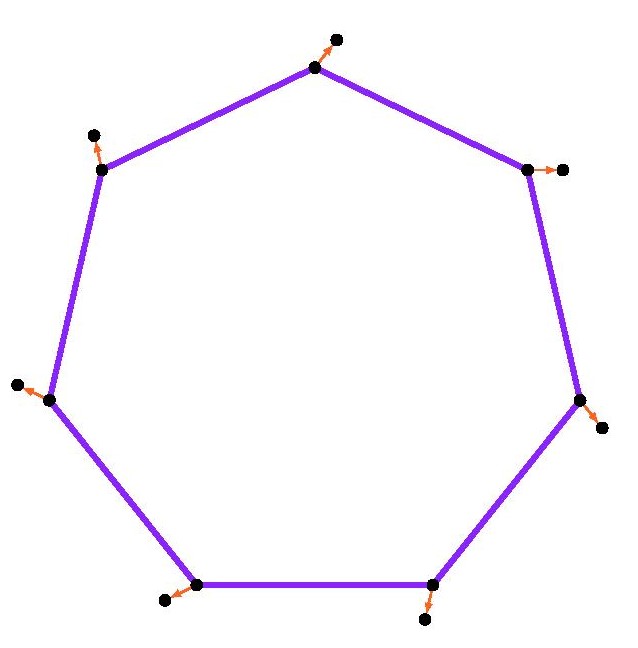
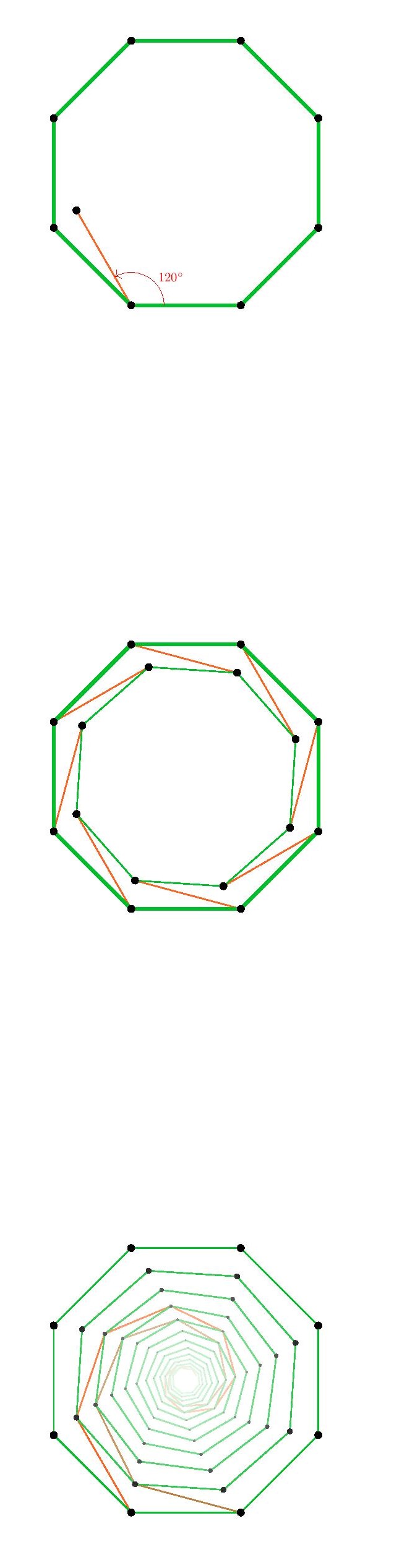
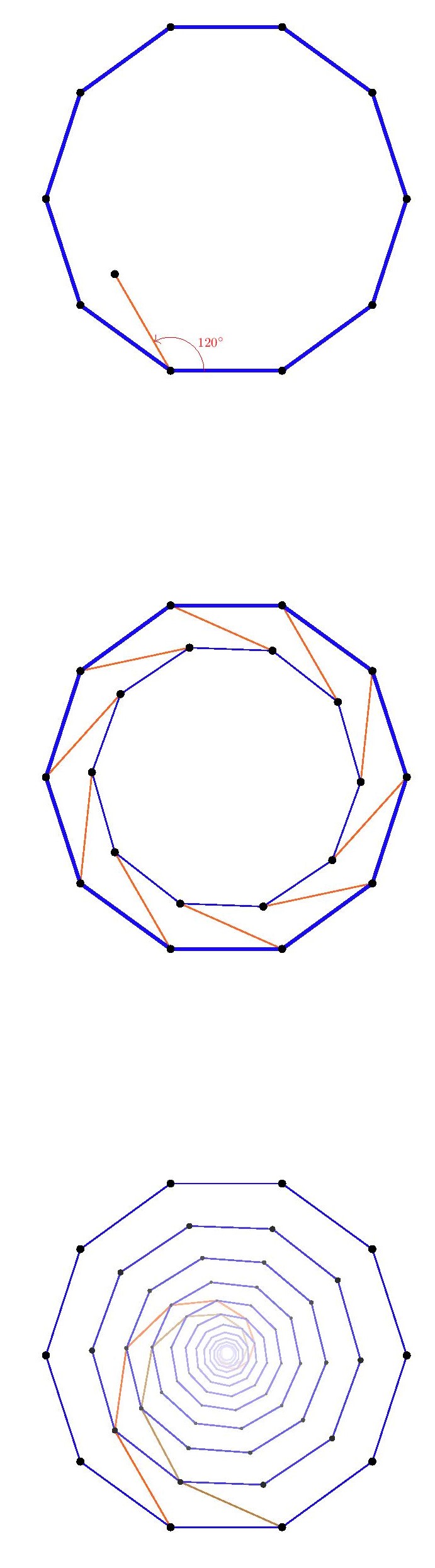
Indeed, the triangular and hexagonal lattices are each refinements of the other, so they will allow exactly the same shapes arising from lattice points.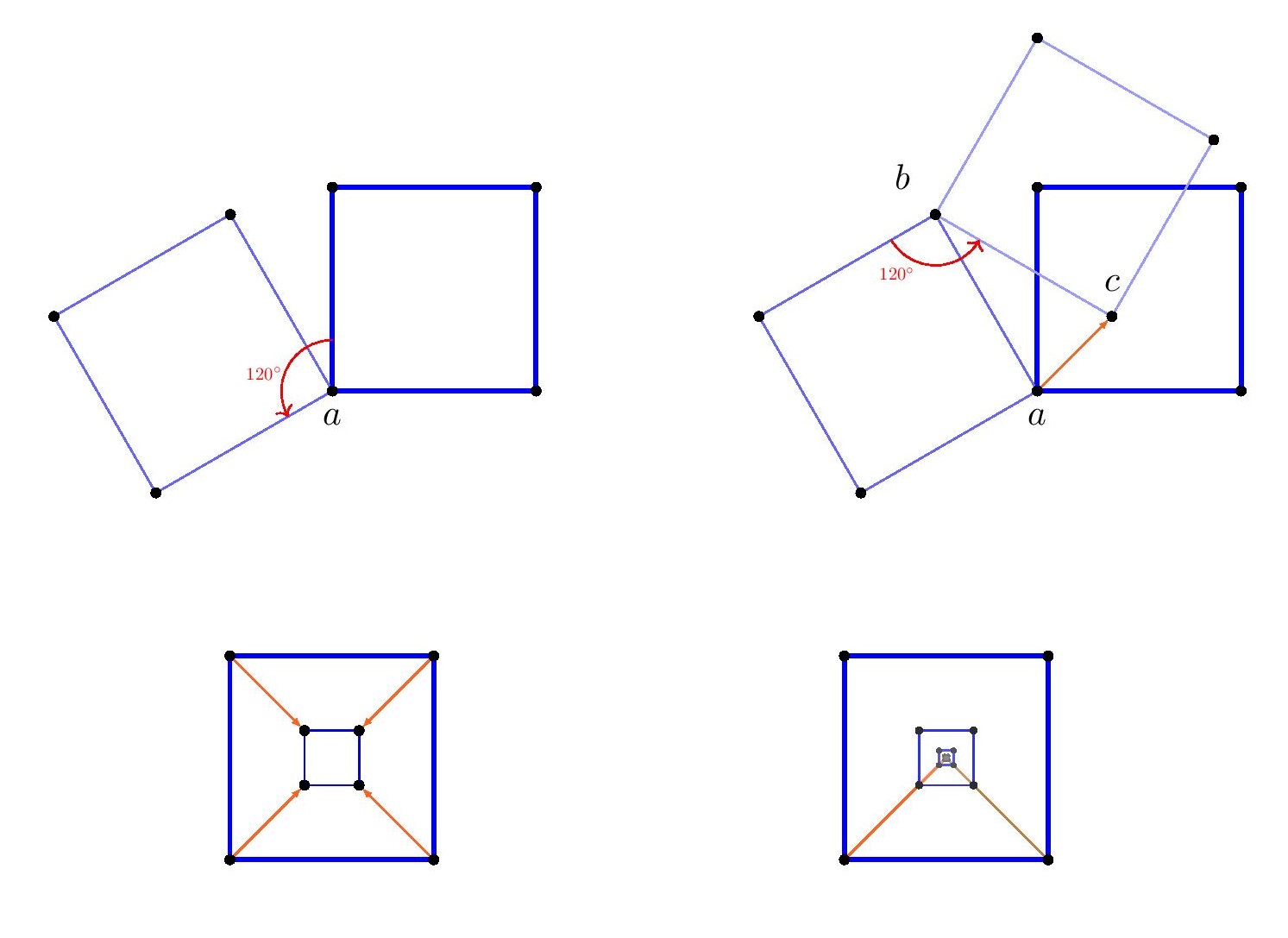 We may rotate this square by $120^\circ$ about the vertex $a$, and the square vertices will all land on lattice-vertex points. Next, we may rotate the resulting square about the point $b$, and again the vertices will land on lattice points. So we have described how to transform any square vertex point $a$ to another lattice point $c$ which is strictly inside the square. By applying that operation to each of the four vertices of the square, we thereby arrive by symmetry at a strictly smaller square. Thus, for any square in the hexagonal or triangular lattice, there is a strictly smaller square. But if there were any square in the lattice at all, there would have to be a square with smallest side-length, since there are only finitely many lattice distances less than any given length. So there can be no square in the hexagonal or triangular lattice.
We may rotate this square by $120^\circ$ about the vertex $a$, and the square vertices will all land on lattice-vertex points. Next, we may rotate the resulting square about the point $b$, and again the vertices will land on lattice points. So we have described how to transform any square vertex point $a$ to another lattice point $c$ which is strictly inside the square. By applying that operation to each of the four vertices of the square, we thereby arrive by symmetry at a strictly smaller square. Thus, for any square in the hexagonal or triangular lattice, there is a strictly smaller square. But if there were any square in the lattice at all, there would have to be a square with smallest side-length, since there are only finitely many lattice distances less than any given length. So there can be no square in the hexagonal or triangular lattice.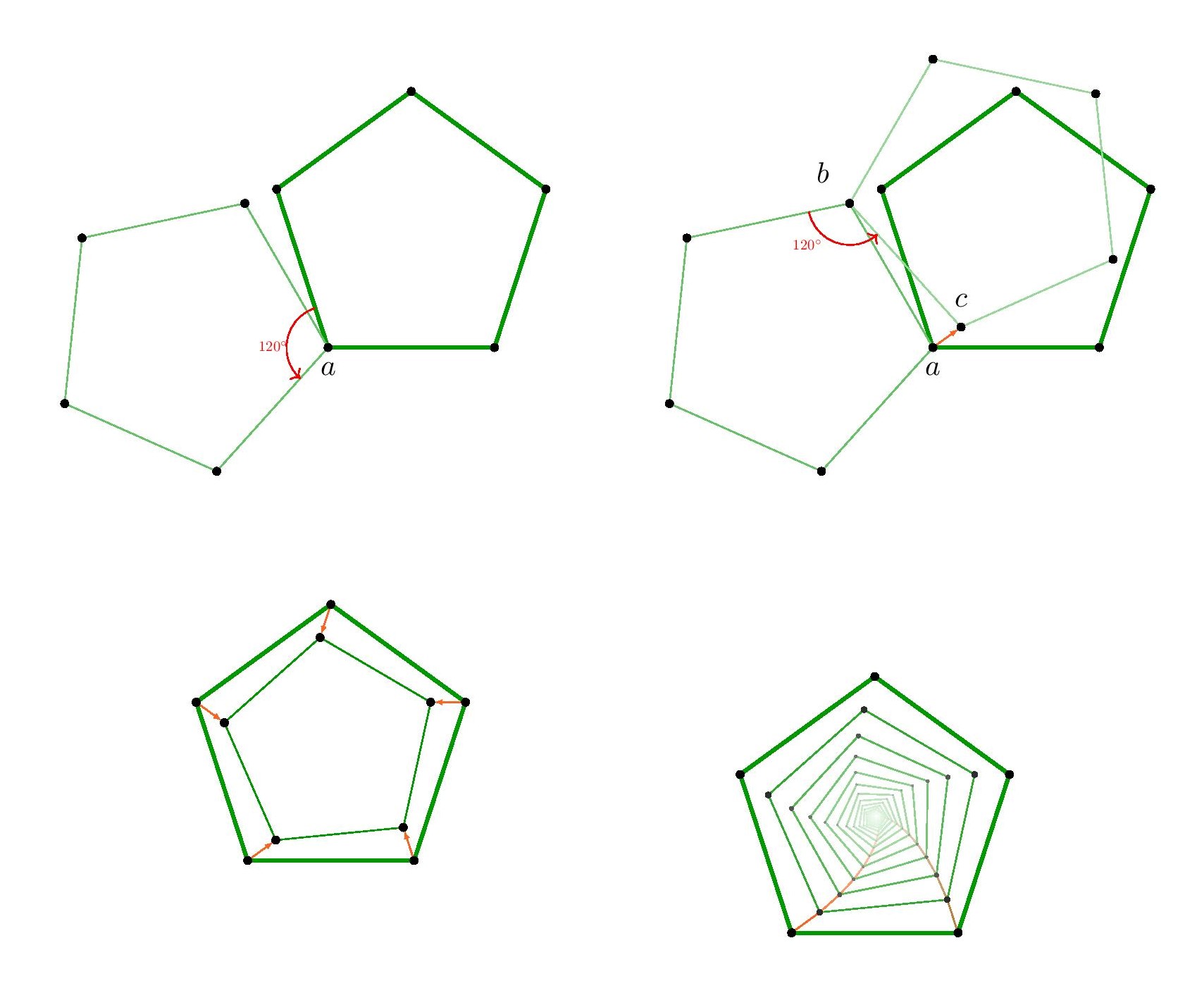
















![By fdecomiteAnetode at en.wikipedia (Tunnels of Time Transferred from en.wikipedia) [CC BY 2.0 (http://creativecommons.org/licenses/by/2.0)], from Wikimedia Commons](https://upload.wikimedia.org/wikipedia/commons/8/85/Swirlyclock.png "By fdecomiteAnetode at en.wikipedia (Tunnels of Time Transferred from en.wikipedia) [CC BY 2.0 (http://creativecommons.org/licenses/by/2.0)], from Wikimedia Commons") I should like to consider a family of natural questions concerning the Gödel sentence — the sentence asserting its own non-provability, used by Gödel to prove the incompleteness theorem — and specifically the question whether we are really entitled to speak of the Gödel sentence. Is it unique? Is it unique up to equivalence? Up to provable equivalence? Could there be more than one Gödel sentence, perhaps for different manners of arithmetizing the syntax? Are they all provably equivalent? These questions have come up a number of times in various contexts, and since
I should like to consider a family of natural questions concerning the Gödel sentence — the sentence asserting its own non-provability, used by Gödel to prove the incompleteness theorem — and specifically the question whether we are really entitled to speak of the Gödel sentence. Is it unique? Is it unique up to equivalence? Up to provable equivalence? Could there be more than one Gödel sentence, perhaps for different manners of arithmetizing the syntax? Are they all provably equivalent? These questions have come up a number of times in various contexts, and since 






 The continuum hypothesis CH is the assertion that the size of the power set of a countably infinite set $\aleph_0$ is the next larger cardinal $\aleph_1$, or in other words, that $2^{\aleph_0}=\aleph_1$. The generalized continuum hypothesis GCH makes this same assertion about all infinite cardinals, namely, that the power set of any infinite cardinal $\kappa$ is the successor cardinal $\kappa^+$, or in other words, $2^\kappa=\kappa^+$.
The continuum hypothesis CH is the assertion that the size of the power set of a countably infinite set $\aleph_0$ is the next larger cardinal $\aleph_1$, or in other words, that $2^{\aleph_0}=\aleph_1$. The generalized continuum hypothesis GCH makes this same assertion about all infinite cardinals, namely, that the power set of any infinite cardinal $\kappa$ is the successor cardinal $\kappa^+$, or in other words, $2^\kappa=\kappa^+$.![By PeterPan23 [Public domain], via Wikimedia Commons](https://upload.wikimedia.org/wikipedia/commons/f/fb/Darts_in_a_dartboard.jpg)




.jpg#/media/File:Lorde_Laneway_7_(cropped).jpg "De Annette Geneva - Flickr: LORDE, CC BY-SA 2.0")
 or GFDL (http://www.gnu.org/copyleft/fdl.html)], from Wikimedia Commons")















.jpg#/media/File:Meat_Loaf_in_performance_(New_York,_2004).jpg "By Mr.Mushnik at English Wikipedia, CC BY 2.5, https://commons.wikimedia.org/w/index.php?curid=1537525")


.jpg#/media/File:Theodor_Seuss_Geisel_(01037v).jpg)


, CC BY-SA 3.0")

.jpg#/media/File:Emily_Dickinson_daguerreotype_(cropped).jpg)



.jpg)



