What a pleasure it was to be interviewed by Evelyn Lamb and Kevin Knudson for their wonderful podcast series, My Favorite Theorem, available on Apple, Spotify, and any number of other aggregators.
I had a chance to talk about one my most favorite theorems, the fundamental theorem of finite games.
Theorem.(Zermelo 1913) In any two-player finite game of perfect information, one of the players has a winning strategy, or both players have drawing strategies.
Listen to the podcast here: My Favorite Theorem. A transcript is also available.
I was interviewed 26 August 2021 by mathematician Daniel Rubin on his show, and we had a lively, wideranging discussion spanning mathematics, infinity, and the philosophy of mathematics. Please enjoy!
Abstract. The principle of open determinacy for class games — two-player games of perfect information with plays of length ω, where the moves are chosen from a possibly proper class, such as games on the ordinals — is not provable in Zermelo-Fraenkel set theory ZFC or Gödel-Bernays set theory GBC, if these theories are consistent, because provably in ZFC there is a definable open proper class game with no definable winning strategy. In fact, the principle of open determinacy and even merely clopen determinacy for class games implies Con(ZFC) and iterated instances Con(Con(ZFC)) and more, because it implies that there is a satisfaction class for first-order truth, and indeed a transfinite tower of truth predicates $\text{Tr}_\alpha$ for iterated truth-about-truth, relative to any class parameter. This is perhaps explained, in light of the Tarskian recursive definition of truth, by the more general fact that the principle of clopen determinacy is exactly equivalent over GBC to the principle of elementary transfinite recursion ETR over well-founded class relations. Meanwhile, the principle of open determinacy for class games is strictly stronger, although it is provable in the stronger theory GBC+$\Pi^1_1$-comprehension, a proper fragment of Kelley-Morse set theory KM.
Welcome to Cantor’s Ice Cream Shoppe! A huge choice of flavors—pile your cone high with as many scoops as you want!
Have two scoops, or three, four, or more! Why not infinitely many? Would you like $\omega$ many scoops, or $\omega\cdot2+5$ many scoops? You can have any countable ordinal number of scoops on your cone.
And furthermore, after ordering your scoops, you can order more scoops to be placed on top—all I ask is that you let me know how many such extra orders you plan to make. Let’s simply proceed transfinitely. You can announce any countable ordinal $\eta$, which will be the number of successive orders you will make; each order is a countable ordinal number of ice cream scoops to be placed on top of whatever cone is being assembled.
In fact, I’ll even let you change your mind about $\eta$ as we proceed, so as to give you more orders to make a taller cone.
So the process is:
You pick a countable ordinal $\eta$, which is the number of orders you will make.
For each order, you can pick any countable ordinal number of scoops to be added to the top of your ice-cream cone.
After making your order, you can freely increase $\eta$ to any larger countable ordinal, giving you the chance to make as many additional orders as you like.
At each limit stage of the ordering process, the ice cream cone you are assembling has all the scoops you’ve ordered so far, and we set the current $\eta$ value to the supremum of the values you had chosen so far.
If at any stage, you’ve used up your $\eta$ many orders, then the process has completed, and I serve you your ice cream cone. Enjoy!
Question. Can you arrange to achieve uncountably many scoops on your cone?
Although at each stage we place only countably many ice cream scoops onto the cone, nevertheless we can keep giving ourselves extra stages, as many as we want, simply by increasing $\eta$. Can you describe a systematic process of increasing the number of steps that will enable you to make uncountably many orders? This would achieve an unountable ice cream cone.
What is your solution? Give it some thought before proceeding. My solution appears below.
Alas, I claim that at Cantor’s Ice Cream Shoppe you cannot make an ice cream cone with uncountably many scoops. Specifically, I claim that there will inevitably come a countable ordinal stage at which you have used up all your orders.
Suppose that you begin by ordering $\beta_0$ many scoops, and setting a large value $\eta_0$ for the number of orders you will make. You subsequently order $\beta_1$ many additional scoops, and then $\beta_2$ many on top of that, and so on. At each stage, you may also have increased the value of $\eta_0$ to $\eta_1$ and then $\eta_2$ and so on. Probably all of these are enormous countable ordinals, making a huge ice cream cone.
At each stage $\alpha$, provided $\alpha<\eta_\alpha$, then you can make an order of $\beta_\alpha$ many scoops on top of your cone, and increase $\eta_\alpha$ to $\eta_{\alpha+1}$, if desired, or keep it the same.
At a limit stage $\lambda$, your cone has $\sum_{\alpha<\lambda}\beta_\alpha$ many scoops, and we update the $\eta$ value to the supremum of your earlier declarations $\eta_\lambda=\sup_{\alpha<\lambda}\eta_\alpha$.
What I claim now is that there will inevitably come a countable stage $\lambda$ for which $\lambda=\eta_\lambda$, meaning that you have used up all your orders with no possibility to further increase $\eta$. To see this, consider the sequence $$\eta_0\leq \eta_{\eta_0}\leq \eta_{\eta_{\eta_0}}\leq\cdots$$ We can define the sequence recursively by $\lambda_0=\eta_0$ and $\lambda_{n+1}=\eta_{\lambda_n}$. Let $\lambda=\sup_{n<\omega}\lambda_n$, the limit of this sequence. This is a countable supremum of countable ordinals and hence countable. But notice that $$\eta_\lambda=\sup_{n<\omega}\eta_{\lambda_n}=\sup_{n<\omega}\lambda_{n+1}=\lambda.$$ That is, $\eta_\lambda=\lambda$ itself, and so your orders have run out at $\lambda$, with no possibility to add more scoops or to increase $\eta$. So your order process completed at a countable stage, and you have therefore altogether only a countable ordinal number of scoops of ice cream. I’m truly very sorry at your pitiable impoverishment.
This will be accessible online talk about infinite chess and other infinite games for the Talk Math With Your Friends seminar, June 18, 2020 4 pm EST (9 pm UK). Zoom access information. Please come talk math with me!
Abstract. I will give an introduction to the theory of infinite games, with examples drawn from infinite chess in order to illustrate various concepts, such as the transfinite game value of a position.
I saw the following image on Twitter and Reddit, an image suggesting an entire class of infinitary analogues of the game Connect-Four. What fun! Let’s figure it out!
I’m not sure to whom the image or the idea is due. Please comment if you have information. (See comments below for current information.)
Update: Please read my essay Infinite Connect Four for my current thinking on this topic, which grew out of this blog post, but the new ideas in that essay give ultimately a far more satisfactory analysis.
The rules will naturally generalize those in Connect-Four. Namely, starting from an empty board, the players take turns placing their coins into the $\omega\times 4$ grid. When a coin is placed in a column, it falls down to occupy the lowest available cell. Let us assume for now that the game proceeds for $\omega$ many moves, whether or not the board becomes full, and the goal is to make a connected sequence in a row of $\omega$ many coins of your color (you don’t have to fill the whole row, but rather a connected infinite segment of it suffices). A draw occurs when neither or both players achieve their goals.
In the $\omega\times 6$ version of the game that is shown, and indeed in the $\omega\times n$ version for any finite $n$, I claim that neither player can force a win; both players have drawing strategies.
Theorem. In the game Connect-$\omega$ on a board of size $\omega\times n$, where $n$ is finite, neither player has a winning strategy; both players have drawing strategies.
Proof. For a concrete way to see this, observe that either player can ensure that there are infinitely many of their coins on the bottom row: they simply place a coin into some far-out empty column. This blocks a win for the opponent on the bottom row. Next, observe that neither player can afford to follow the strategy of always answering those moves on top, since this would lead to a draw, with a mostly empty board. Thus, it must happen that infinitely often we are able to place a coin onto the second row. This blocks a win for the opponent on the second row. And so on. In this way, either players can achieve infinitely many of their coins on each row, thereby blocking any row as a win for their opponent. So both players have drawing strategies. $\Box$
Let me point out that on a board of size $\omega\times n$, where $n$ is odd, we can also make this conclusion by a strategy-stealing argument. Specifically, I argue first that the first player can have no winning strategy. Suppose $\sigma$ is a winning strategy for the first player on the $\omega\times n$ board, with $n$ odd, and let us describe a strategy for the second player. After the first move, the second player mentally ignores a finite left-initial segment of the playing board, which includes that first move and with a odd number of cells altogether in it (and hence an even number of empty cells remaining); the second player will now aim to win on the now-empty right-side of the board, by playing as though playing first in a new game, using strategy $\sigma$. If the first player should ever happen to play on the ignored left side of the board, then the second player can answer somewhere there (it doesn’t matter where). In this way, the second player plays with $\sigma$ as though he is the first player, and so $\sigma$ cannot be winning for the first player, since in this way the second player would win in this stolen manner.
Similarly, let us argue by strategy-stealing that the second player cannot have a winning strategy on the board $\omega\times n$ for odd finite $n$. Suppose that $\tau$ is a winning strategy for the second player on such a board. Let the first player always play at first in the left-most column. Because $n$ is odd, the second player will eventually have to play first in the second or later columns, leaving an even number of empty cells in the first column (perhaps zero). At this point, the first player can play as though he was the second player on the right-side board containing only that fresh move. If the opponent plays again to the left, then our player can also play in that region (since there were an even number of empty cells). Thus, the first player can steal the strategy $\tau$, and so it cannot be winning for the second player.
I am unsure about how to implement the strategy stealing arguments when $n$ is even. I shall give this more thought. In any case, the theorem for this case was already proved directly by the initial concrete argument, and in this sense we do not actually need the strategy stealing argument for this case.
Meanwhile, it is natural also to consider the $n\times\omega$ version of the game, which has only finitely many columns, each infinite. The players aim to get a sequence of $\omega$-many coins in a column. This is clearly impossible, as the opponent can prevent a win by always playing atop the most recent move. Thus:
Theorem. In the game Connect-$\omega$ on a board of size $n\times\omega$, where $n$ is finite, neither player has a winning strategy; both players have drawing strategies.
Perhaps the most natural variation of the game, however, occurs with a board of size $\omega\times\omega$. In this version, like the original Connect-Four, a player can win by either making a connected row of $\omega$ many coins, or a connected column or a connected diagonal of $\omega$ many coins. Note that we orient the $\omega$ size column upwards, so that there is no top cell, but rather, one plays by selecting a not-yet-filled column and then occupying the lowest available cell in that column.
Theorem. In the game Connect-$\omega$ on a board of size $\omega\times\omega$, neither player has a winning strategy. Both players have drawing strategies.
Proof. Consider the strategy-stealing arguments. If the first player has a winning strategy $\sigma$, then let us describe a strategy for the second player. After the first move, the second player will ignore finitely many columns at the left, including that first actual move, aiming to play on the empty right-side of the board as though the first player using stolen strategy $\sigma$ (but with colors swapped). This will work fine, as long as the first player also plays on that part of the board. Whenever the first player plays on the ignored left-most part, simply respond by playing atop. This prevents a win in that part of the part, and so the second player will win on the right-side by pretending to be first there. So there can be no such winning strategy $\sigma$ for the first player.
If the second player has a winning strategy $\tau$, then as before let the first player always play in the first column, until $\tau$ directs the second player to play in another column, which must eventually happen if $\tau$ is winning. At that moment, the first player can pretend to be second on the subboard omitting the first column. So $\tau$ cannot have been winning after all for the second player. $\Box$
In the analysis above, I was considering the game that proceeded in time $\omega$, with $\omega$ many moves. But such a play of the game may not actually have filled the board completely. So it is natural to consider a version of the game where the players continue to play transfinitely, if the board is not yet full.
So let us consider now the transfinite-play version of the game, where play proceeds transfinitely through the ordinals, until either the board is filled or one of the players has achieved the winning goal. Let us assume that the first player also plays first at limit stages, at $\omega$ and $\omega\cdot 2$ and $\omega^2$, and so on, if game play should happen to proceed for that long.
The concrete arguments that I gave above continue to work for the transfinite-play game on the boards of size $\omega\times n$ and $n\times\omega$.
Theorem. In the transfinite-play version of Connect-$\omega$ on boards of size $\omega\times n$ or $n\times\omega$, where $n$ is finite, neither player can have a winning strategy. Indeed, both players can force a draw while also filling the board in $\omega$ moves.
Proof. It is clear that on the $n\times\omega$ board, either player can force each column to have infinitely many coins of their color, and this fills the board, while also preventing a win for the opponent, as desired.
On the $\omega\times n$ board, consider a variation of the strategy I described above. I shall simply always play in the first available empty column, thereby placing my coin on the bottom row, until the opponent also plays in a fresh column. At that moment, I shall play atop his coin, thereby placing another coin in the second row; immediately after this, I also play subsequently in the left-most available column (so as to force the board to be filled). I then continue playing in the bottom row, until the opponent also does, which she must, and then I can add another coin to the second row and so on. By always playing the first-available second-row slot with all-empty second rows to the right, I can ensure that the opponent will eventually also make a second-row play (since otherwise I will have a winning condition on the second row), and at such a moment, I can also make a third-row play. By continuing in this way, I am able to place infinitely many coins on each row, while also forcing that the board becomes filled. $\Box$
Unfortunately, the transfinite-play game seems to break the strategy-stealing arguments, since the play is not symmetric for the players, as the first player plays first at limit stages.
Nevertheless, following some ideas of Timothy Gowers in the comments below, let me show that the second player has a drawing strategy.
Theorem. In the transfinite-play version of Connect-$\omega$ on a board of size $\omega\times\omega$, the second player has a drawing strategy.
Proof. We shall arrange that the second player will block all possible winning configurations for the first player, or to have column wins for each player. To block all row wins, the second player will arrange to occupy infinitely many cells in each row; to block all diagonal wins, the second player will aim to occupy infinitely many cells on each possible diagonal; and to block the column wins, the second player will aim either to have infinitely many cells on each column or to copy a winning column of the opponent on another column.
To achieve these things, we simply play as follows. Take the columns in successive groups of three. On the first column in each block of three, that is on the columns indexed $3m$, the second player will always answer a move by the first player on this column. In this way, the second player occupies every other cell on these columns—all at the same height. This will block all diagonal wins, because every diagonal winning configuration will need to go through such a cell.
On the remaining two columns in each group of three, columns $3m+1$ and $3m+2$, let the second player simply copy moves of the opponent on one of these columns by playing on the other. These moves will therefore be opposite colors, but at the same height. In this way, the second player ensures that he has infinitely many coins on each row, blocking the row wins. And also, this strategy ensures that in these two columns, at any limit stage, either neither player has achieved a winning configuration or both have.
Thus, we have produced a drawing strategy for the second player. $\Box$
Thus, there is no advantage to going first. What remains is to determine if the first player also has a drawing strategy, or whether the second player can actually force a win.
Gowers explains in the comments below also how to achieve such a copying mechanism to work on a diagonal, instead of just on a column.
I find it also fascinating to consider the natural generalizations of the game to larger ordinals. We may consider the game of Connect-$\alpha$ on a board of size $\kappa\times\lambda$, for any ordinals $\alpha,\kappa,\lambda$, with transfinite play, proceeding until the board is filled or the winning conditions are achieved. Clearly, there are some instances of this game where a player has a winning strategy, such as the original Connect-Four configuration, where the first player wins, and presumably many other instances.
Question. In which instances of Connect-$\alpha$ on a board of size $\kappa\times\lambda$ does one of the players have a winning strategy?
It seems to me that the groups-of-three-columns strategy described above generalizes to show that the second player has at least a drawing strategy in Connect-$\alpha$ on board $\kappa\times\lambda$, whenever $\alpha$ is infinite.
Consider what I call the Sudoku game, recently introduced in the MathOverflow question Who wins two-player Sudoku? posted by Christopher King (user PyRulez). Two players take turns placing numbers on a Sudoku board, obeying the rule that they must never explicitly violate the Sudoku condition: the numbers on any row, column or sub-board square must never repeat. The first player who cannot continue legal play loses. Who wins the game? What is the winning strategy?
The game is not about building a global Sudoku solution, since a move can be legal in this game even when it is not part of any global Sudoku solution, provided only that it doesn’t yet explicitly violate the Sudoku condition. Rather, the Sudoku game is about trying to trap your opponent in a maximal such position, a position which does not yet explicitly violate the Sudoku condition but which cannot be further extended.
In my answer to the question on MathOverflow, I followed an idea suggested to me by my daughter Hypatia, namely that on even-sized boards $n^2\times n^2$ where $n$ is even, then the second player can win with a mirroring strategy: simply copy the opponent’s moves in reflected mirror image through the center of the board. In this way, the second player ensures that the position on the board is always symmetric after her play, and so if the previous move was safe, then her move also will be safe by symmetry. This is therefore a winning strategy for the second player, since any violation of the Sudoku condition will arise on the opponent’s play.
This argument works on even-sized boards precisely because the reflection of every row, column and sub-board square is a totally different row, column and sub-board square, and so any new violation of the Sudoku conditions would reflect to a violation that was already there. The mirror strategy definitely does not work on the odd-sized boards, including the main $9\times 9$ case, since if the opponent plays on the central row, copying directly would immediately introduce a Sudoku violation.
After posting that answer, Orson Peters (user orlp) pointed out that one can modify it to form a winning strategy for the first player on odd-sized boards, including the main $9\times 9$ case. In this case, let the first player begin by playing $5$ in the center square, and then afterwards copy the opponent’s moves, but with the ten’s complement at the reflected location. So if the opponent plays $x$, then the first player plays $10-x$ at the reflected location. In this way, the first player can ensure that the board is ten’s complement symmetric after her moves. The point is that again this is sufficient to know that she will never introduce a violation, since if her $10-x$ appears twice in some row, column or sub-board square, then $x$ must have already appeared twice in the reflected row, column or sub-board square before that move.
This idea is fully general for odd-sized Sudoku boards $n^2\times n^2$, where $n$ is odd. If $n=2k-1$, then the first player starts with $k$ in the very center and afterward plays the $2k$-complement of her opponent’s move at the reflected location.
Conclusion.
On even-sized Sudoku boards, the second player wins the Sudoku game by the mirror copying strategy.
On odd-sized Sudoku boards, the first players wins the Sudoku game by the complement-mirror copying strategy.
Note that on the even boards, the second player could also play complement mirror copying just as successfully.
What I really want to tell you about, however, is the infinite Sudoku game (following a suggestion of Sam Hopkins). Suppose that we try to play the Sudoku game on a board whose subboard squares are $\mathbb{Z}\times\mathbb{Z}$, so that the full board is a $\mathbb{Z}\times\mathbb{Z}$ array of those squares, making $\mathbb{Z}^2\times\mathbb{Z}^2$ altogether. (Or perhaps you might prefer the board $\mathbb{N}^2\times\mathbb{N}^2$?)
One thing to notice is that on an infinite board, it is no longer possible to get trapped at a finite stage of play, since every finite position can be extended simply by playing a totally new label from the set of labels; such a move would never lead to a new violation of the explicit Sudoku condition.
For this reason, I should like to introduce the Sudoku Solver-Spoiler game variation as follows. There are two players: the Sudoku Solver and the Sudoku Spoiler. The Solver is trying to build a global Sudoku solution on the board, while the Spoiler is trying to prevent this. Both players must obey the Sudoku condition that labels are never to be explicitly repeated in any row, column or sub-board square. On an infinite board, the game proceeds transfinitely, until the board is filled or there are no legal moves. The Solver wins a play of the game, if she successfully builds a global Sudoku solution, which means not only that every location has a label and there are no repetitions in any row, column or sub-board square, but also that every label in fact appears in every row, column and sub-board square. That is, to count as a solution, the labels on any row, column and sub-board square must be a bijection with the set of labels. (On infinite boards, this is a stronger requirement than merely insisting on no repetitions.)
The Solver-Spoiler game makes sense in complete generality on any set $S$, whether finite or infinite. The sub-boards are $S^2=S\times S$, and one has an $S\times S$ array of them, so $S^2\times S^2$ for the whole board. Every row and column has the same size as the sub-board square $S^2$, and the set of labels should also have this size.
Upon reflection, one realizes that what matters about $S$ is just its cardinality, and we really have for every cardinal $\kappa$ the $\kappa$-Sudoku Solver-Spoiler game, whose board is $\kappa^2\times\kappa^2$, a $\kappa\times\kappa$ array of $\kappa\times\kappa$ sub-boards. In particular, the game $\mathbb{Z}^2\times\mathbb{Z}^2$ is actually isomorphic to the game $\mathbb{N}^2\times\mathbb{N}^2$, despite what might feel initially like a very different board geometry.
What I claim is that the Solver has a winning strategy in the all the infinite Sudoku Solver-Spoiler games, in a very general and robust manner.
Theorem. For every infinite cardinal $\kappa$, the Solver has a winning strategy to win the $\kappa$-Sudoku Solver-Spoiler game.
The strategy will win in $\kappa$ many moves, producing a full Sudoku solution.
The Solver can win whether she goes first or second, starting from any legal position of size less than $\kappa$.
The Solver can win even when the Spoiler is allowed to play finitely many labels at once on each turn, or fewer than $\kappa$ many moves (if $\kappa$ is regular), even if the Solver is only allowed one move each turn.
In the countably infinite Sudoku game, the Solver can win even if the Spoiler is allowed to make infinitely many moves at once, provided only that the resulting position can in principle be extended to a full solution.
Proof. Consider first the countably infinite Sudoku game, and assume the initial position is finite and that the Spoiler will make finitely many moves on each turn. Consider what it means for the Solver to win at the limit. It means, first of all, that there are no explicit repetitions in any row, column or sub-board. This requirement will be ensured since it is part of the rules for legal play not to violate it. Next, the Solver wants to ensure that every square has a label on it and that every label appears at least once in every row, every column and every sub-board. If we think of these as individual specific requirements, we have countably many requirements in all, and I claim that we can arrange that the Solver will simply satisfy the $n^{th}$ requirement on her $n^{th}$ play. Given any finite position, she can always find something to place in any given square, using a totally new label if need be. Given any finite position, any row and any particular label $k$, since can always find a place on that row to place the label, which has no conflict with any column or sub-board, since there are infinitely many to choose from and only finitely many conflicts. Similarly with columns and sub-boards. So each of the requirements can always be fulfilled one-at-a-time, and so in $\omega$ many moves she can produce a full solution.
The argument works equally well no matter who goes first or if the Spoiler makes arbitrary finite play, or indeed even infinite play, provided that the play is part of some global solution (perhaps a different one each time), since on each move the Solve can simply meet the requirement by using that solution at that stage.
An essentially similar argument works when $\kappa$ is uncountable, although now the play will proceed for $\kappa$ many steps. Assuming $\kappa^2=\kappa$, a consequence of the axiom of choice, there are $\kappa$ many requirements to meet, and the Solve can meet requirement $\alpha$ on the $\alpha^{th}$ move. If $\kappa$ is regular, we can again allow the Spoiler to make arbitrary size-less-than-$\kappa$ size moves, so that at any stage of play before $\kappa$ the position will still be size less than $\kappa$. (If $\kappa$ is singular, one can allow Spoiler to make finitely many moves at once or indeed even some uniform bounded size $\delta<\kappa$ many moves at once. $\Box$
I find it interesting to draw out the following aspect of the argument:
Observation. Every finite labeling of an infinite Sudoku board that does not yet explicitly violate the Sudoku condition can be extended to a global solution.
Similarly, any size less than $\kappa$ labeling that does not yet explicitly violate the Sudoku condition can be extended to a global solution of the $\kappa$-Sudoku board for any infinite cardinal $\kappa$.
What about asymmetric boards? It has come to my attention that people sometimes look at asymmetric Sudoku boards, whose sub-boards are not square, such as in the six-by-six Sudoku case. In general, one could take Sudoku boards to consist of a $\lambda\times\kappa$ array of sub-boards of size $\kappa\times\lambda$, where $\kappa$ and $\lambda$ are cardinals, not necessarily the same size and not necessarily both infinite or both finite. How does this affect the arguments I’ve given?
In the finite $(n\times m)\times (m\times n)$ case, if one of the numbers is even, then it seems to me that the reflection through the origin strategy works for the second player just as before. And if both are odd, then the first player can again play in the center square and use the mirror-complement strategy to trap the opponent. So that analysis will work fine.
In the case $(\kappa\times\lambda)\times(\lambda\times\kappa)$ where $\lambda\leq\kappa$ and $\kappa=\lambda\kappa$ is infinite, then the proof of the theorem seems to break, since if $\lambda<\kappa$, then with only $\lambda$ many moves, say putting a common symbol in each of the $\lambda$ many rectangles across a row, we can rule out that symbol in a fixed row. So this is a configuration of size less than $\kappa$ that cannot be extended to a full solution. For this reason, it seems likely to me that the Spoiler can win the Sudoko Solver-Spoiler game in the infinite asymmetric case.
Finally, let’s consider the Sudoku Solver-Spoiler game in the purely finite case, which actually is a very natural game, perhaps more natural than what I called the Sudoku game above. It seems to me that the Spoiler should be able to win the Solver-Spoiler game on any nontrivial finite board. But I don’t yet have an argument proving this. I asked a question on MathOverflow: The Sudoku game: Solver-Spoiler variation.
This will be a talk for the CUNY Set Theory Seminar, April 27, 2018, GC Room 6417, 10-11:45am (please note corrected date).
Abstract. Open class determinacy is the principle of second order set theory asserting of every two-player game of perfect information, with plays coming from a (possibly proper) class $X$ and the winning condition determined by an open subclass of $X^\omega$, that one of the players has a winning strategy. This principle finds itself about midway up the hierarchy of second-order set theories between Gödel-Bernays set theory and Kelley-Morse, a bit stronger than the principle of elementary transfinite recursion ETR, which is equivalent to clopen determinacy, but weaker than GBC+$\Pi^1_1$-comprehension. In this talk, I’ll given an account of my recent joint work with W. Hugh Woodin, proving that open class determinacy is preserved by forcing. A central part of the proof is to show that in any forcing extension of a model of open class determinacy, every well-founded class relation in the extension is ranked by a ground model well-order relation. This work therefore fits into the emerging focus in set theory on the interaction of fundamental principles of second-order set theory with fundamental set theoretic tools, such as forcing. It remains open whether clopen determinacy or equivalently ETR is preserved by set forcing, even in the case of the forcing merely to add a Cohen real.
This will be a talk for the Prague set theory seminar, January 24, 11:00 am to about 2pm (!).
Abstract. The class forcing theorem is the assertion that every class forcing notion admits corresponding forcing relations. This assertion is not provable in Zermelo-Fraenkel ZFC set theory or Gödel-Bernays GBC set theory, if these theories are consistent, but it is provable in stronger second-order set theories, such as Kelley-Morse KM set theory. In this talk, I shall discuss the exact strength of this theorem, which turns out to be equivalent to the principle of elementary transfinite recursion ETRord for class recursions on the ordinals. The principle of clopen determinacy for class games, in contrast, is strictly stronger, equivalent over GBC to the full principle of ETR for class recursions over arbitrary class well-founded relations. These results and others mark the beginnings of the emerging subject I call the reverse mathematics of second-order set theory.
Let me tell you about a fascinating paradox arising in certain infinitary two-player games of perfect information. The paradox, namely, is that there are games for which our judgement of who has a winning strategy or not depends on whether we insist that the players play according to a deterministic computable procedure. In the the space of computable play for these games, one player has a winning strategy, but in the full space of all legal play, the other player can ensure a win.
The fundamental theorem of finite games, proved in 1913 by Zermelo, is the assertion that in every finite two-player game of perfect information — finite in the sense that every play of the game ends in finitely many moves — one of the players has a winning strategy. This is generalized to the case of open games, games where every win for one of the players occurs at a finite stage, by the Gale-Stewart theorem 1953, which asserts that in every open game, one of the players has a winning strategy. Both of these theorems are easily adapted to the case of games with draws, where the conclusion is that one of the players has a winning strategy or both players have draw-or-better strategies.
Let us consider games with a computable game tree, so that we can compute whether or not a move is legal. Let us say that such a game is computably paradoxical, if our judgement of who has a winning strategy depends on whether we restrict to computable play or not. So for example, perhaps one player has a winning strategy in the space of all legal play, but the other player has a computable strategy defeating all computable strategies of the opponent. Or perhaps one player has a draw-or-better strategy in the space of all play, but the other player has a computable strategy defeating computable play.
Examples of paradoxical games occur in infinite chess. We described such a paradoxical position in my paper Transfinite games values in infinite chess by giving a computable infinite chess position with the property that both players had drawing strategies in the space of all possible legal play, but in the space of computable play, then white had a computable strategy defeating any particular computable strategy for black.
For a related non-chess example, let $T$ be a computable subtree of $2^{<\omega}$ having no computable infinite branch, and consider the game in which black simply climbs in this tree as white watches, with black losing whenever he is trapped in a terminal node, but winning if he should climb infinitely. This game is open for white, since if white wins, this is known at a finite stage of play. In the space of all possible play, Black has a winning strategy, which is simply to climb the tree along an infinite branch, which exists by König’s lemma. But there is no computable strategy to find such a branch, by the assumption on the tree, and so when black plays computably, white will inevitably win.
For another example, suppose that we have a computable linear order $\lhd$ on the natural numbers $\newcommand\N{\mathbb{N}}\N$, which is not a well order, but which has no computable infinite descending sequence. It is a nice exercise in computable model theory to show that such an order exists. If we play the count-down game in this order, with white trying to build a descending sequence and black watching. In the space of all play, white can succeed and therefore has a winning strategy, but since there is no computable descending sequence, white can have no computable winning strategy, and so black will win every computable play.
There are several proofs of open determinacy (and see my MathOverflow post outlining four different proofs of the fundamental theorem of finite games), but one of my favorite proofs of open determinacy uses the concept of transfinite game values, assigning an ordinal to some of the positions in the game tree. Suppose we have an open game between Alice and Bob, where the game is open for Alice. The ordinal values we define for positions in the game tree will measure in a sense the distance Alice is away from winning. Namely, her already-won positions have value $0$, and if it is Alice’s turn to play from a position $p$, then the value of $p$ is $\alpha+1$, if $\alpha$ is minimal such that she can play to a position of value $\alpha$; if it is Bob’s turn to play from $p$, and all the positions to which he can play have value, then the value of $p$ is the supremum of these values. Some positions may be left without value, and we can think of those positions as having value $\infty$, larger than any ordinal. The thing to notice is that if a position has a value, then Alice can always make it go down, and Bob cannot make it go up. So the value-reducing strategy is a winning strategy for Alice, from any position with value, while the value-maintaining strategy is winning for Bob, from any position without a value (maintaining value $\infty$). So the game is determined, depending on whether the initial position has value or not.
What is the computable analogue of the ordinal-game-value analysis in the computably paradoxical games? If a game is open for Alice and she has a computable strategy defeating all computable opposing strategies for Bob, but Bob has a non-computable winning strategy, then it cannot be that we can somehow assign computable ordinals to the positions for Alice and have her play the value-reducing strategy, since if those values were actual ordinals, then this would be a full honest winning strategy, even against non-computable play.
Nevertheless, I claim that the ordinal-game-value analysis does admit a computable analogue, in the following theorem. This came out of a discussion I had recently with Noah Schweber during his recent visit to the CUNY Graduate Center and Russell Miller. Let us define that a computable open game is an open game whose game tree is computable, so that we can tell whether a given move is legal from a given position (this is a bit weaker than being able to compute the entire set of possible moves from a position, even when this is finite). And let us define that an effective ordinal is a computable relation $\lhd$ on $\N$, for which there is no computable infinite descending sequence. Every computable ordinal is also an effective ordinal, but as we mentioned earlier, there are non-well-ordered effective ordinals. Let us call them computable pseudo-ordinals.
Theorem. The following are equivalent for any computable game, open for White.
White has a computable strategy defeating any computable play by Black.
There is an effective game-value assignment for white into an effective ordinal $\lhd$, giving the initial position a value. That is, there is a computable assignment of some positions of the game, including the first position, to values in the field of $\lhd$, such that from any valued position with White to play, she can play so as to reduce value, and with Black to play, he cannot increase the value.
Proof. ($2\to 1$) Given the computable values into an effective ordinal, then the value-reducing strategy for White is a computable strategy. If Black plays computably, then together they compute a descending sequence in the $\lhd$ order. Since there is no computable infinite descending sequence, it must be that the values hit zero and the game ends with a win for White. So White has a computable strategy defeating any computable play by Black.
($1\to 2$) Conversely, suppose that White has a computable strategy $\sigma$ defeating any computable play by Black. Let $\tau$ be the subtree of the game tree arising by insisting that White follow the strategy $\sigma$, and view this as a tree on $\N$, a subtree of $\N^{<\omega}$. Imagine the tree growing downwards, and let $\lhd$ be the Kleene-Brouwer order on this tree, which is the lexical order on incompatible positions, and otherwise longer positions are lower. This is a computable linear order on the tree. Since $\sigma$ is computably winning for White, the open player, it follows that every computable descending sequence in $\tau$ eventually reaches a terminal node. From this, it follows that there is no computable infinite descending sequence with respect to $\lhd$, and so this is an effective ordinal. We may now map every node in $\tau$, which includes the initial node, to itself in the $\lhd$ order. This is a game-value assignment, since on White’s turn, the value goes down, and it doesn’t go up on Black’s turn. QED
Corollary. A computable open game is computably paradoxical if and only if it admits an effective game value assignment for the open player, but only with computable pseudo-ordinals and not with computable ordinals.
Proof. If there is an effective game value assignment for the open player, then the value-reducing strategy arising from that assignment is a computable strategy defeating any computable strategy for the opponent. Conversely, if the game is paradoxical, there can be no such ordinal-assignment where the values are actually well-ordered, or else that strategy would work against all play by the opponent. QED
Let me make a few additional observations about these paradoxical games.
Theorem. In any open game, if the closed player has a strategy defeating all computable opposing strategies, then in fact this is a winning strategy also against non-computable play.
Proof. If the closed player has a strategy $\sigma$ defeating all computable strategies of the opponent, then in fact it defeats all strategies of the opponent, since any winning play by the open player against $\sigma$ wins in finitely many moves, and therefore there is a computable strategy giving rise to the same play. QED
Corollary. If an open game is computably paradoxical, it must be the open player who wins in the space of computable play and the closed player who wins in the space of all play.
Proof. The theorem shows that if the closed player wins in the space of computable play, then that player in fact wins in the space of all play. QED
Corollary. There are no computably paradoxical clopen games.
Proof. If the game is clopen, then both players are closed, but we just argued that any computable strategy for a closed player winning against all computable play is also winning against all play. QED
Abstract. The principle of open determinacy for class games — two-player games of perfect information with plays of length $\omega$, where the moves are chosen from a possibly proper class, such as games on the ordinals — is not provable in Zermelo-Fraenkel set theory ZFC or Gödel-Bernays set theory GBC, if these theories are consistent, because provably in ZFC there is a definable open proper class game with no definable winning strategy. In fact, the principle of open determinacy and even merely clopen determinacy for class games implies Con(ZFC) and iterated instances Con(Con(ZFC)) and more, because it implies that there is a satisfaction class for first-order truth, and indeed a transfinite tower of truth predicates $\text{Tr}_\alpha$ for iterated truth-about-truth, relative to any class parameter. This is perhaps explained, in light of the Tarskian recursive definition of truth, by the more general fact that the principle of clopen determinacy is exactly equivalent over GBC to the principle of elementary transfinite recursion ETR over well-founded class relations. Meanwhile, the principle of open determinacy for class games is provable in the stronger theory GBC+$\Pi^1_1$-comprehension, a proper fragment of Kelley-Morse set theory KM. New work by Hachtman and Sato, respectively has clarified the separation of clopen and open determinacy for class games.
This will be a talk January 10, 2017 for the Basic Notions Seminar, aimed at students, post-docs, faculty and guests of the Mathematics Institute, University of Bonn.
Abstract. I shall give a general introduction to the theory of infinite games, using infinite chess — chess played on an infinite edgeless chessboard — as a central example. Since chess, when won, is won at a finite stage of play, infinite chess is an example of what is known technically as an open game, and such games admit the theory of transfinite ordinal game values. I shall exhibit several interesting positions in infinite chess with very high transfinite game values. The precise value of the omega one of chess is an open mathematical question. This talk will include some of the latest progress, which includes a position with game value $\omega^4$.
It happens that I shall be in Bonn also for the dissertation defense of Regula Krapf, who will defend the same week, and who is one of the organizers of the seminar.
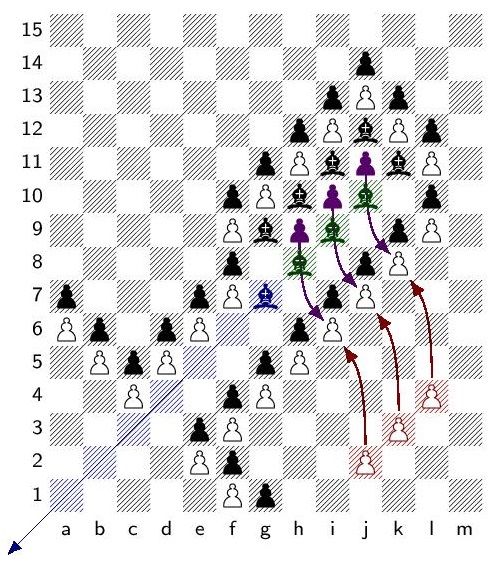
Abstract. We present a position in infinite chess exhibiting an ordinal game value of $\omega^4$, thereby improving on the previously largest-known values of $\omega^3$ and $\omega^3\cdot 4$.
This is a joint work with Cory Evans and Norman Perlmutter, continuing the research program of my previous article with Evans, Transfinite game values in infinite chess, namely, the research program of finding positions in infinite chess with large transfinite ordinal game values. In the previous article, Cory and I presented a position with game value $\omega^3$. In the current paper, with Norman Perlmutter now having joined us accompanied by some outstanding ideas, we present a new position having game value $\omega^4$, breaking the previous record.
A position in infinite chess with value $\omega^4$
In the new position, above, the kings sit facing each other in the throne room, an uneasy détente, while white makes steady progress in the rook towers. Meanwhile, at every step black, doomed, mounts increasingly desperate bouts of long forced play using the bishop cannon battery, with bishops flying with force out of the cannons, and then each making a long series of forced-reply moves in the terminal gateways. Ultimately, white wins with value omega^4, which exceeds the previously largest known values of omega^3.
In the throne room, if either black or white places a bishop on the corresponding diagonal entryway, then checkmate is very close. A key feature is that for white to place a white-square white bishop on the diagonal marked in red, it is immediate checkmate, whereas if black places a black-square black bishop on the blue diagonal, then checkmate comes three moves later. The bishop cannon battery arrangement works because black threatens to release a bishop into the free region, and if white does not reply to those threats, then black will be three steps ahead, but otherwise, only two.
The throne room
The rook towers are similar to the corresponding part of the previous $\omega^3$ position, and this is where white undertakes most of his main line progress towards checkmate. Black will move the key bishop out as far as he likes on the first move, past $n$ rook towers, and the resulting position will have value $\omega^3\cdot n$. These towers are each activated in turn, leading to a long series of play for white, interrupted at every opportunity by black causing a dramatic spectacle of forced-reply moves down in the bishop cannon battery.
The rook towers
At every opportunity, black mounts a long distraction down in the bishop cannon battery. Shown here is one bishop cannon. The cannonballs fire out of the cannon with force, in the sense that when each green bishop fires out, then white must reply by moving the guard pawns into place.
Bishop cannon
Upon firing, each bishop will position itself so as to attack the entrance diagonal of a long bishop gateway terminal wing. This wing is arranged so that black can make a series of forced-reply threats successively, by moving to the attack squares (marked with the blue squares). Black is threatening to exit through the gateway doorway (in brown), but white can answer the threat by moving the white bishop guards (red) into position. Thus, each bishop coming out of a cannon (with force) can position itself at a gateway terminal of length $g$, making $g$ forced-reply moves in succession. Since black can initiate firing with an arbitrarily large cannon, this means that at any moment, black can cause a forced-reply delay with game value $\omega^2$. Since the rook tower also has value $\omega^2$ by itself, the overall position has value $\omega^4=\omega^2\cdot\omega^2$.
Bishop gateway terminal wing
With future developments in mind, we found that one can make a more compact arrangement of the bishop cannon battery, freeing up a quarter board for perhaps another arrangement that might lead to a higher ordinal values.
Alternative compact version of bishop cannon battery
Read more about it in the article, which is available at the arxiv (pdf).
Abstract. The principle of open determinacy for class games — two-player games of perfect information with plays of length $\omega$, where the moves are chosen from a possibly proper class, such as games on the ordinals — is not provable in Zermelo-Fraenkel set theory ZFC or Gödel-Bernays set theory GBC, if these theories are consistent, because provably in ZFC there is a definable open proper class game with no definable winning strategy. In fact, the principle of open determinacy and even merely clopen determinacy for class games implies Con(ZFC) and iterated instances Con(Con(ZFC)) and more, because it implies that there is a satisfaction class for first-order truth, and indeed a transfinite tower of truth predicates $\text{Tr}_\alpha$ for iterated truth-about-truth, relative to any class parameter. This is perhaps explained, in light of the Tarskian recursive definition of truth, by the more general fact that the principle of clopen determinacy is exactly equivalent over GBC to the principle of elementary transfinite recursion ETR over well-founded class relations. Meanwhile, the principle of open determinacy for class games is provable in the stronger theory GBC+$\Pi^1_1$-comprehension, a proper fragment of Kelley-Morse set theory KM.
This is joint work with Victoria Gitman, with the helpful participation of Thomas Johnstone.
I should like to argue that the axiom of determinacy is true for all games having a small payoff set. In particular, the size of the smallest non-determined set, in the sense of the axiom of determinacy, is the continuum; every set of size less than the continuum is determined, even when the continuum is enormous.
We consider two-player games of perfect information. Two players, taking turns, play moves from a fixed space $X$ of possible moves, and thereby together build a particular play or instance of the game $\vec a=\langle a_0,a_1,\ldots\rangle\in X^\omega$. The winner of this instance of the game is determined according to whether the play $\vec a$ is a member of some fixed payoff set $U\subset X^\omega$ specifying the winning condition for this game. Namely, the first player wins in the case $\vec a\in U$.
A strategy in such a game is a function $\sigma:X^{<\omega}\to X$ that instructs a particular player how to move next, given the sequence of partial play, and such a strategy is a winning strategy for that player, if all plays made against it are winning for that player. (The first player applies the strategy $\sigma$ only on even-length input, and the second player only to the odd-length inputs.) The game is determined, if one of the players has a winning strategy.
It is not difficult to see that if $U$ is countable, then the game is determined. To see this, note first that if the space of moves $X$ has at most one element, then the game is trivial and hence determined; and so we may assume that $X$ has at least two elements. If the payoff set $U$ is countable, then we may enumerate it as $U=\{s_0,s_1,\ldots\}$. Let the opposing player now adopt the strategy of ensuring on the $n^{th}$ move that the resulting play is different from $s_n$. In this way, the opposing player will ensure that the play is not in $U$, and therefore win. So every game with a countable payoff set is determined.
Meanwhile, using the axiom of choice, we may construct a non-determined set even for the case $X=\{0,1\}$, as follows. Since a strategy is function from finite binary sequences to $\{0,1\}$, there are only continuum many strategies. By the axiom of choice, we may well-order the strategies in order type continuum. Let us define a payoff set $U$ by a transfinite recursive procedure: at each stage, we will have made fewer than continuum many promises about membership and non-membership in $U$; we consider the next strategy on the list; since there are continuum many plays that accord with that strategy for each particular player, we may make two additional promises about $U$ by placing one of these plays into $U$ and one out of $U$ in such a way that this strategy is defeated as a winning strategy for either player. The result of the recursion is a non-determined set of size continuum.
So what is the size of the smallest non-determined set? For a lower bound, we argued above that every countable payoff set is determined, and so the smallest non-determined set must be uncountable, of size at least $\aleph_1$. For an upper bound, we constructed a non-determined set of size continuum. Thus, if the continuum hypothesis holds, then the smallest non-determined set has size exactly continuum, which is $\aleph_1$ in this case. But what if the continuum hypothesis fails? I claim, nevertheless, that the smallest non-determined set still has size continuum.
Theorem. Every game whose winning condition is a set of size less than the continuum is determined.
Proof. Suppose that $U\subset X^\omega$ is the payoff set of the game under consideration, so that $U$ has size less than continuum. If $X$ has at most one element, then the game is trivial and hence determined. So we may assume that $X$ has at least two elements. Let us partition the elements of $X^\omega$ according to whether they have exactly the same plays for the second player. So there are at least continuum many classes in this partition. If $U$ has size less than continuum, therefore, it must be disjoint from at least one (and in fact from most) of the classes of this partition (since otherwise we would have an injection from the continuum into $U$). So there is a fixed sequence of moves for the second player, such that any instance of the game in which the second player makes those moves, the result is not in $U$ and hence is a win for the second player. This is a winning strategy for the second player, and so the game is determined. QED
This proof generalizes the conclusion of the diagonalization argument against a countable payoff set, by showing that for any winning condition set of size less than continuum, there is a fixed play for the opponent (not depending on the play of the first player) that defeats it.
The proof of the theorem uses the axiom of choice in the step where we deduce that $U$ must be disjoint from a piece of the partition, since there are continuum many such pieces and $U$ had size less than the continuum. Without the axiom of choice, this conclusion does not follow. Nevertheless, what the proof does show without AC is that every set that does not surject onto $\mathbb{R}$ is determined, since if $U$ contained an element from every piece of the partition it would surject onto $\mathbb{R}$. Without AC, the assumption that $U$ does not surject onto $\mathbb{R}$ is stronger than the assumption merely that it has size less the continuum, although these properties are equivalent in ZFC. Meanwhile, these issues are relevant in light of the model suggested by Asaf Karagila in the comments below, which shows that it is consistent with ZF without the axiom of choice that there are small non-determined sets. Namely, the result of Monro shows that it is consistent with ZF that $\mathbb{R}=A\sqcup B$, where both $A$ and $B$ have cardinality less than the continuum. In particular, in this model the continuum injects into neither $A$ nor $B$, and consequently neither player can have a strategy to force the play into their side of this partition. Thus, both $A$ and $B$ are non-determined, even though they have size less than the continuum.













 This is joint work with Victoria Gitman. See our article,
This is joint work with Victoria Gitman. See our article, 





 [CC BY-SA 3.0 (http://creativecommons.org/licenses/by-sa/3.0)], via Wikimedia Commons")