
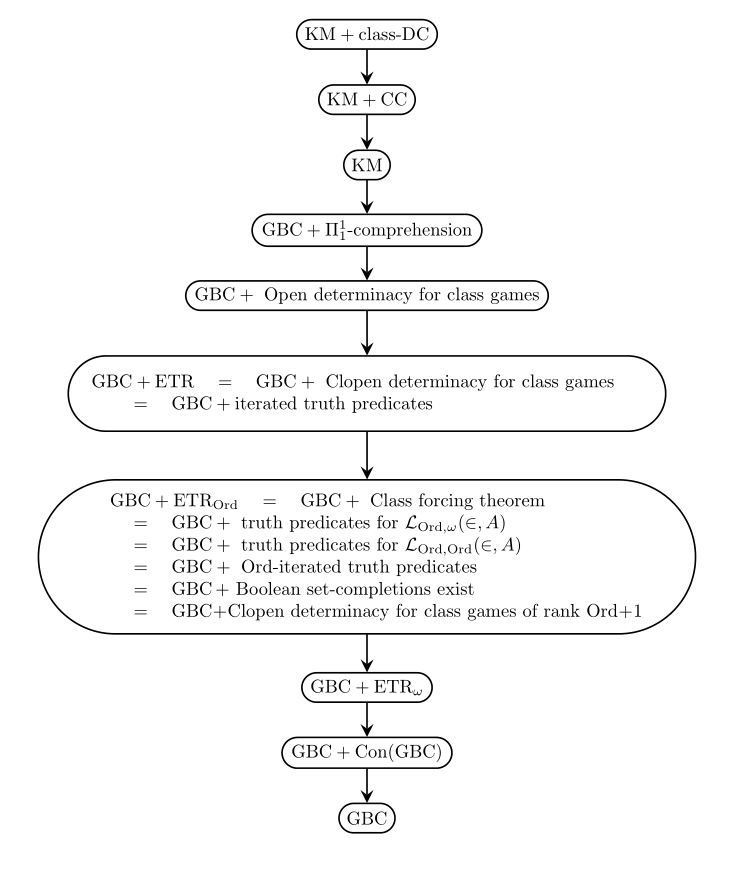
I’d like to continue a bit further my exploration of some principles of determinacy for proper-class games; it turns out that these principles have a surprising set-theoretic strength. A few weeks ago, I explained that the determinacy of proper-class open games and even clopen games implies Con(ZFC) and much more. Today, I’d like to prove that clopen determinacy is exactly equivalent over GBC to the principle of transfinite recursion along proper-class well-founded relations. Thus, GBC plus either of these principles is a strictly intermediate set theory between GBC and KM.
The principle of clopen determinacy for class games is the assertion that in any two-player infinite game of perfect information whose winning condition is a clopen class, there is a winning strategy for one of the players. Players alternately play moves in a playing space , thereby creating a particular play , and the winner is determined according to whether is in a certain fixed payoff class or not. One has an open game when this winning condition class is open in the product topology (using the discrete topology on ). A game is open for a player if and only if every winning play for that player has an initial segment, all of whose extensions are also winning for that player. So the game is won for an open player at a finite stage of play. A clopen game, in contrast, has a payoff set that is open for both players. Clopen games can be equivalently cast in terms of the game tree, consisting of positions in the game where the winner is not yet determined, and where play terminates when the winner is known. Namely, a game is clopen exactly when this game tree is well-founded, so that in every play, the outcome is known already at a finite stage.
A strategy is a class function that instructs the player what to play next, given a position of partial play, and the strategy is winning for a player if all plays that accord with it satisfy the winning condition for that player.
The principle of transfinite recursion along well-founded class relations is the assertion that we may undertake recursive definitions along any class well-founded partial order relation. That is, suppose that is a class well-founded partial order relation on a class , and suppose that is a formula, using only first-order quantifiers but having a class variable , which is functional in the sense that for any class and any set there is a unique such that . The idea is that expresses the recursive rule to be iterated, and a solution of the recursion is a class function such that holds for every , where means the restriction of to the class . Thus, the value is determined by the class of previous values for . The principle of transfinite recursion along class well-founded relations is the assertion scheme that for every such well-founded partial order class and any recursive rule as above, there is a solution.
In the case that the relation is set-like, which means that the predecessors of any point form a set (rather than a proper class), then GBC easily proves that there is a unique solution class, which furthermore is definable from . Namely, one can show that every has a partial solution that obeys the recursive rule at least up to , and furthermore all such partial solutions agree below , because there can be no -minimal violation of this. It follows that the class function unifying these partial solutions is a total solution to the recursion. Similarly, GBC can prove that there are solutions to other transfinite recursion instances where the well-founded relation is not necessarily set-like, such as a recursion of length or even much longer.
Meanwhile, if GBC is consistent, then it cannot in general prove that transfinite recursions along non-set-like well-founded relations always succeed, since this principle would imply that there is a truth-predicate for first-order truth, as the Tarskian conditions are precisely such a recursion on a well-founded relation based on the complexity of formulas. (That relation is not set-like, since when considering the truth of , we want to consider the truth of for any parameter , and there are a proper class of such .) Thus, GBC plus transfinite recursion (or plus clopen determinacy) is strictly stronger than GBC, although it is provable in Kelley-Morse set theory KM essentially the same as GBC proves the set-like special case.
Theorem. Assume GBC. Then the following are equivalent.
- Clopen determinacy for class games. That is, for any two-player game of perfect information whose payoff class is both open and closed, there is a winning strategy for one of the players.
- Transfinite recursion for proper class well-founded relations (not necessarily set-like).
Proof. () Assume the principle of transfinite recursion for proper class well-founded relations, and suppose we are faced with a clopen game. Consider the game tree , consisting of positions arising during play, up to the moment that a winner is known. This tree is well-founded because the game is clopen. Let us label the terminal nodes of the tree with I or II according to who has won the game in that position, and more generally, let us label all the nodes of the tree with I or II according to the following transfinite recursion: if a node has I to play, then it will have label I if there is a move to a node labeled I, and otherwise II; and similarly when it is II to play. By the principle of transfinite recursion, there is a labeling of the entire tree that accords with this recursive rule. It is now easy to see that if the initial node is labeled with I, then player I has a winning strategy, which is simply to stay on the nodes labeled I. Note that player II cannot play in one move from a node labeled I to one labeled II. Similarly, if the initial node is labeled II, then player II has a winning strategy; and so the game is determined, as desired.
() Conversely, let us assume the principle of clopen determinacy for class games. Suppose we are faced with a recursion along a class relation on a class , using a recursion rule . We shall define a certain clopen game, and prove that any winning strategy for this game will produce a solution for the recursion.
It will be convenient to assume that is strongly functional, meaning that not only does it define a function as we have mentioned in , but also that defines a function when used over any model for any class . The strongly functional property can be achieved simply by replacing the formula with the assertion that , if is unique such that this holds, and otherwise .
At first, let us consider a slightly easier game, which will be open rather than clopen; a bit later, we shall revise this game to a clopen game. The game is the recursion game, which will be very much like the truth-telling game of my previous post, Open determinacy for proper class games implies Con(ZFC) and much more. Namely, we have two players, the challenger and the truth-teller. The challenger will issues challenges about truth in a structure , where is the well-founded class relation and is a class function, not yet specified. Specifically, the challenger is allowed to ask about the truth of any formula in this structure, and to inquire as to the value of for any particular . The truth-teller, as before, will answer the challenges by saying either that is true or false, and in the case and the formula was declared true, by also giving a witness and declaring is true; and the truth-teller must specify a specific value for for any particular . The truth-teller loses immediately, if she should ever violate Tarski’s recursive definition of truth; and she also loses unless she declares the recursive rules to be true. Since these violations occur at a finite stage of play if they do at all, the game is open for the challenger.
Lemma. The challenger has no winning strategy in the recursion game.
Proof. Suppose that is a strategy for the challenger. So is a class function that instructs the challenger how to play next, given a position of partial play. By the reflection theorem, there is an ordinal such that is closed under , and using the satisfaction class that comes from clopen determinacy, we may actually also arrange that . Consider the relation , which is a well-founded relation on . The important point is that this relation is now a set, and in GBC we may certainly undertake transfinite recursions along well-founded set relations. Thus, there is a function such that satisfies for all , where means restricting to the predecessors of in , and this may not be all the predecessors of with respect to , which may not be set-like. Note that this is the place where we use our assumption that was strongly functional, since we want to ensure that it can still be used to define a valid recursion over . (We are not claiming that models .)
Consider now the play of the recursion game in , where the challenger uses the strategy and the truth-teller plays in accordance with . Since was closed under , the challenger will never issue challenges outside of . And since the function fulfills the recursion in this structure, the truth-teller will not be trapped in any violation of the Tarski conditions or the recursion condition. Thus, the truth-teller will win this instance of the game, and so was not a winning strategy for the challenger, as desired. QED
Lemma. The truth-teller has a winning strategy in the recursion game if and only if there is a solution of the recursion.
Proof. If there is a solution of the recursion, then by clopen determinacy, we also get a satisfaction class for the structure , and the truth-teller can answer all queries of the challenger by referring to what is actually true in this structure. This will be winning for the truth-teller, since the actual truth obeys the Tarskian conditions and the recursive rule.
Conversely, suppose that is a winning strategy for the truth-teller in the recursion game. We claim that the truth assertions made by do not depend on the order in which challenges are made by the challenger; they all cohere with one another. This is easy to see for formulas not involving by induction on formulas, for if the truth of a formula is independent of play, then also the truth of is as well, and similarly if is declared true with witness , then by induction is independent of the play, in which case must always be declared true by independently of the order of play by the challenger (although the particular witness provided by may depend on the play). Now, let us also argue that the values of declared by are also independent of the order of play. If not, there is some -least where this fails. (Note that such an exists, since is a class, and we can define from the class of for which the value of declared by depends on the order of play; without , one might have expected to need -comprehension to find a minimal where the recursion fails.) As in the truth-telling game, the truth assertions made by about , where is the class function of values that are determined by on , must not depend on the order of play. Since the recursion rule is functional, there is only one value for which this formula can be truthfully held, and so if some play causes to play a different value for , the challenger can in finitely many additional moves (bounded by the syntactic complexity of ) trap the truth-teller in a violation of the Tarskian conditions or the recursion condition. Thus, the values of declared by must in fact all cohere independently of the order of play, and so is describing a class function such that is true for every . So the recursion has a solution, as desired. QED
So far, we have established that the principle of open determinacy implies the principle of transfinite recursion along well-founded class relations. In order to improve this implication to use only clopen determinacy rather than open determinacy, we modify the game to become a clopen game rather than an open game.
Consider the clopen form of the recursion game, where we insist also that the challenger announce on the first move a natural number , such that the challenger loses if the truth-teller survives for at least moves. This is now a clopen game, since the winner will be known by that time, either because the truth-teller will violate the Tarski conditions or the recursion condition, or else the challenger’s limit on play will expire.
Since the modified version of the game is even harder for the challenger, there can still be no winning strategy for the challenger. So by the principle of clopen determinacy, there is a winning strategy for the truth-teller. This strategy is allowed to make decisions based on the number announced by the challenger on the first move, and it will no longer necessarily be the case that the theory declared true by will be independent of the order of play. Nevertheless, it will be the case, we claim, that the theory declared true by for all plays with sufficiently large (and with sufficiently many remaining moves) will be independent of the order of play. One can see this by observing that if an assertion is independent in this sense, then also will be independent in this sense, for otherwise there would be plays with large giving different answers for and we could then challenge with , which would have to give different answers or else would not win. Similarly, since is winning, one can see that allowing the challenger to specify a bound on the total length of play does not prevent the arguments above showing that describes a coherent solution function satisfying the recursion , provided that one looks only at plays in which there are sufficiently many moves remaining. There cannot be a -least where the value of is not determined in this sense, and so on as before.
Thus, we have proved that the principle of clopen determinacy for class games is equivalent to the principle of transfinite recursion along well-founded class relations. QED
The material in this post will become part of a joint project with Victoria Gitman and Thomas Johnstone. We are currently investigating several further related issues.























 [CC BY-SA 3.0 (http://creativecommons.org/licenses/by-sa/3.0)], via Wikimedia Commons")

