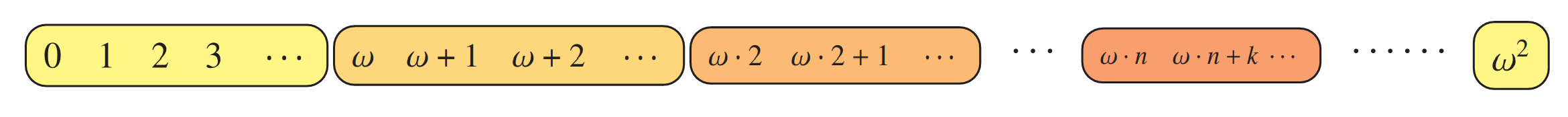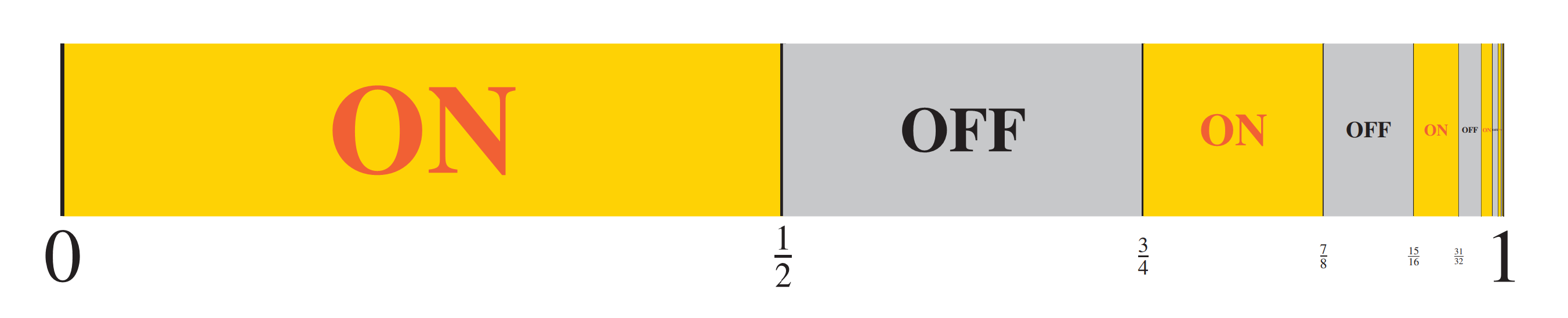This will be a talk for the Logic Seminar at the University of Notre Dame, 14 April 2026, 2pm, Room 125 Hayes-Healey.
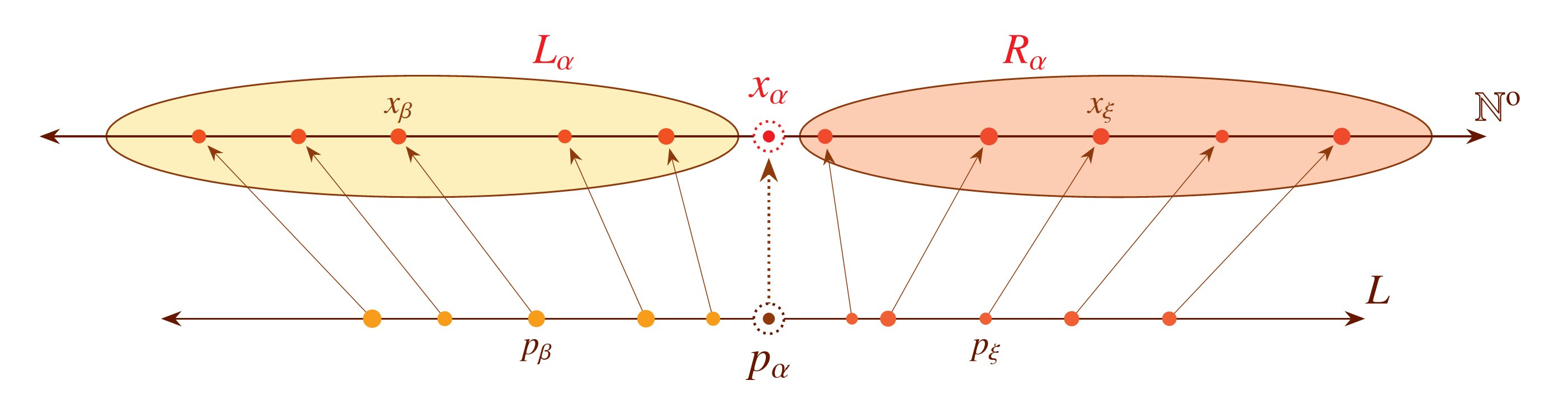
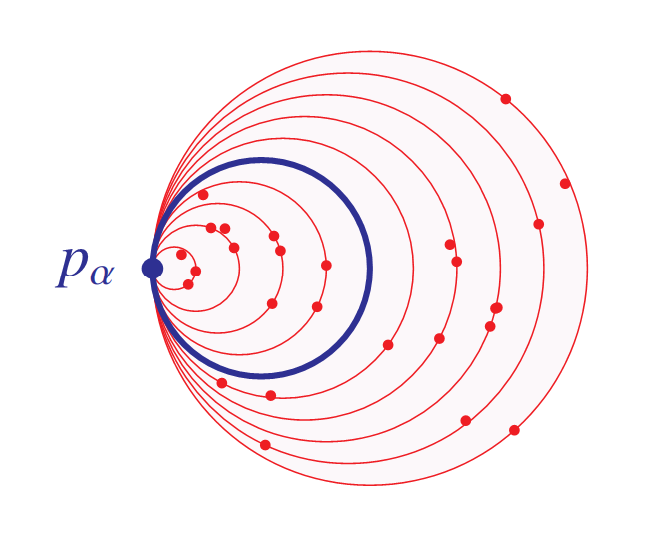
Abstract After establishing several general features of the hierarchy of consistency strength, we shall consider the possible spectrum of assertions of the form $n\in W$, where $W$ is a given computably enumerable set. If $W$ is c.e. but not computably decidable, many of these statements must be independent of PA, as well as ZFC, and indeed any consistent c.e. theory extending these. What kind of consistency strengths can be exhibited by these statements? In this work, we investigate the possible hierarchies of consistency strengths that arise. For example, there is a c.e. set $Q$ for which the consistency strengths of the assertions $n\in Q$ are linearly ordered like the rational line. More generally, I shall prove that every computable preorder relation on the natural numbers is realized exactly as the hierarchy of consistency strength for the membership statements $n\in W$ of some computably enumerable set $W$. After this, we shall consider the c.e. preorder relations. This is in part joint work with Atticus Stonestrom (Notre Dame).
Come, let us explore infinity! We shall visit all my favorite paradoxes and conundrums. The ancient puzzles, confounding or intractable, will yield at times to our analysis. And what a joy it is to experience those Aha! moments—a flash of clarity lights the way out of the labyrinth. But alas, having escaped one maze, we shall often find ourselves immediately lost in another—a new paradox with new questions to answer. The puzzles of infinity are endless riddles nestled within one another.
The Book of Infinity was the original motivation for me to begin my substack Infinitely More. When I first arrived a few years ago at the University of Notre Dame from Oxford, I was asked by my new department what course I would most want to teach. My answer was a new course on infinity that I had long dreamed about—what fun it would be to share my ideas and puzzles with enthusiastic students, tracing the concept from ancient times to contemporary issues. I set furiously to work preparing this book, a series of vignettes on infinity, and we offered the course. I serialized the chapters on Infinitely More as they were completed—see the section The Book of Infinity. I’ve since taught the course several more times, and with further polishing and editing, the book is finally completed.
400 pages and 26 chapters:
The Book of Numbers
The Sand Reckoner
Zeno’s Paradox
The Method of Exhaustion
Supertasks
The Infinite Coastline Paradox
The Paradox of Giants
The Paradox of the Largest Tweetable Number
Potential Versus Actual Infinity
Equinumerosity and Comparison of Size
What Is the Infinite?
Hilbert’s Grand Hotel
Uncountable Infinity
How to Count
Transfinite Recursive Constructions
Slaying the Hydra
The Continuum Hypothesis
Throwing Darts at the Real Line
The Orders of Infinity
The Surreal Numbers
The Axiom of Choice
Infinitary Hat Puzzles and the Aftermath
The Guessing-Box Puzzle
We Can Predict the Future
Infinite Liars
Common Knowledge
Here are a few snippets from the index, to give you an idea of what’s covered…
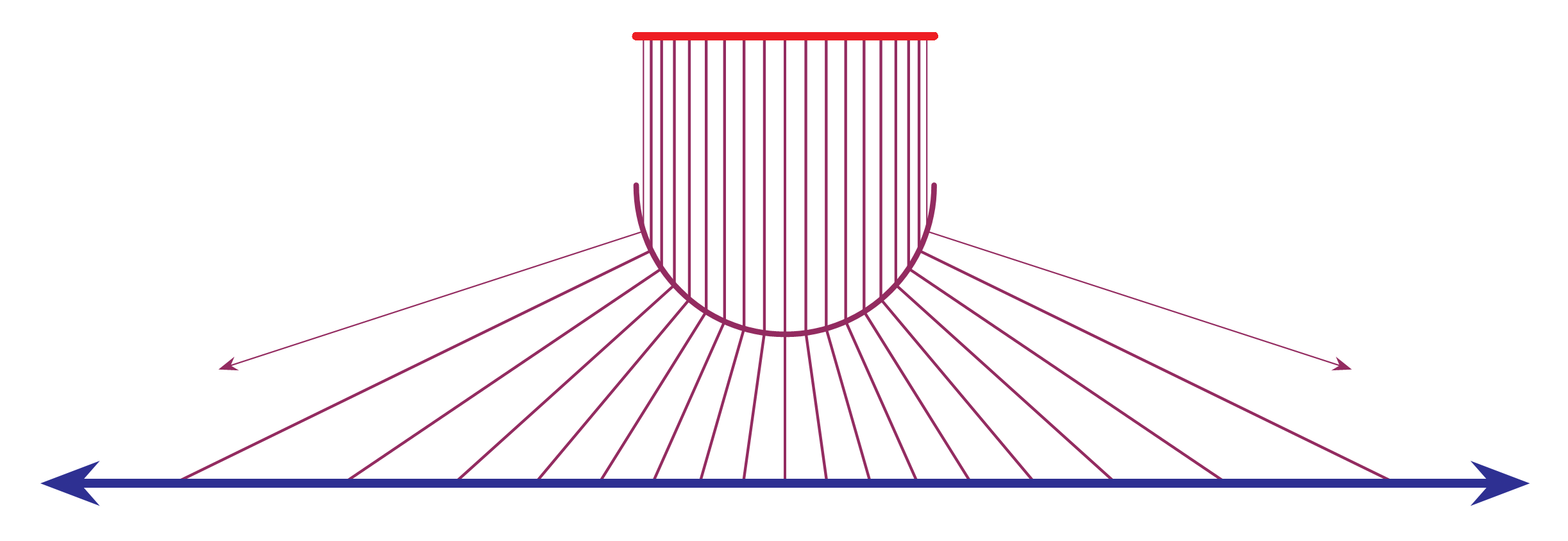
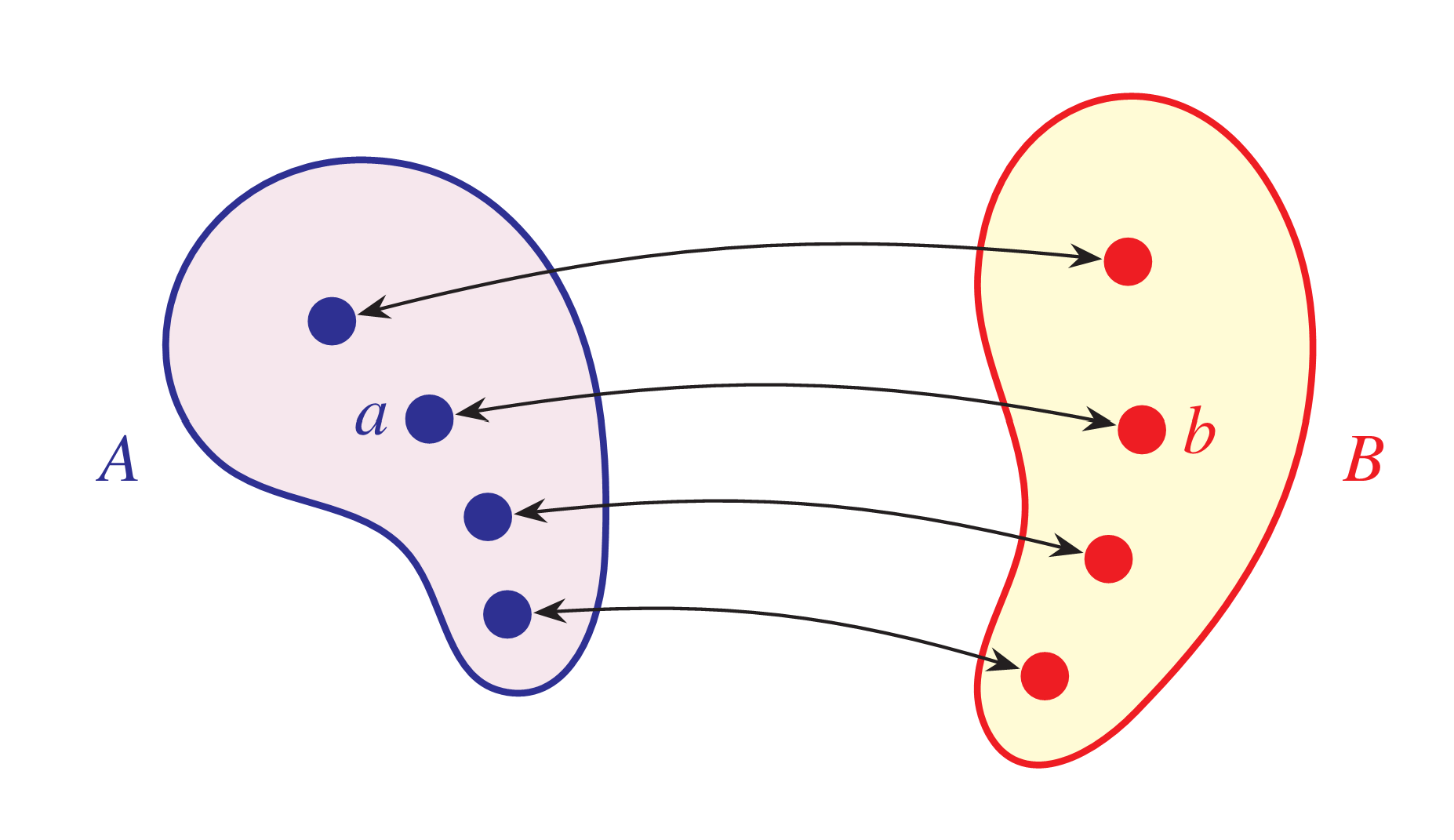
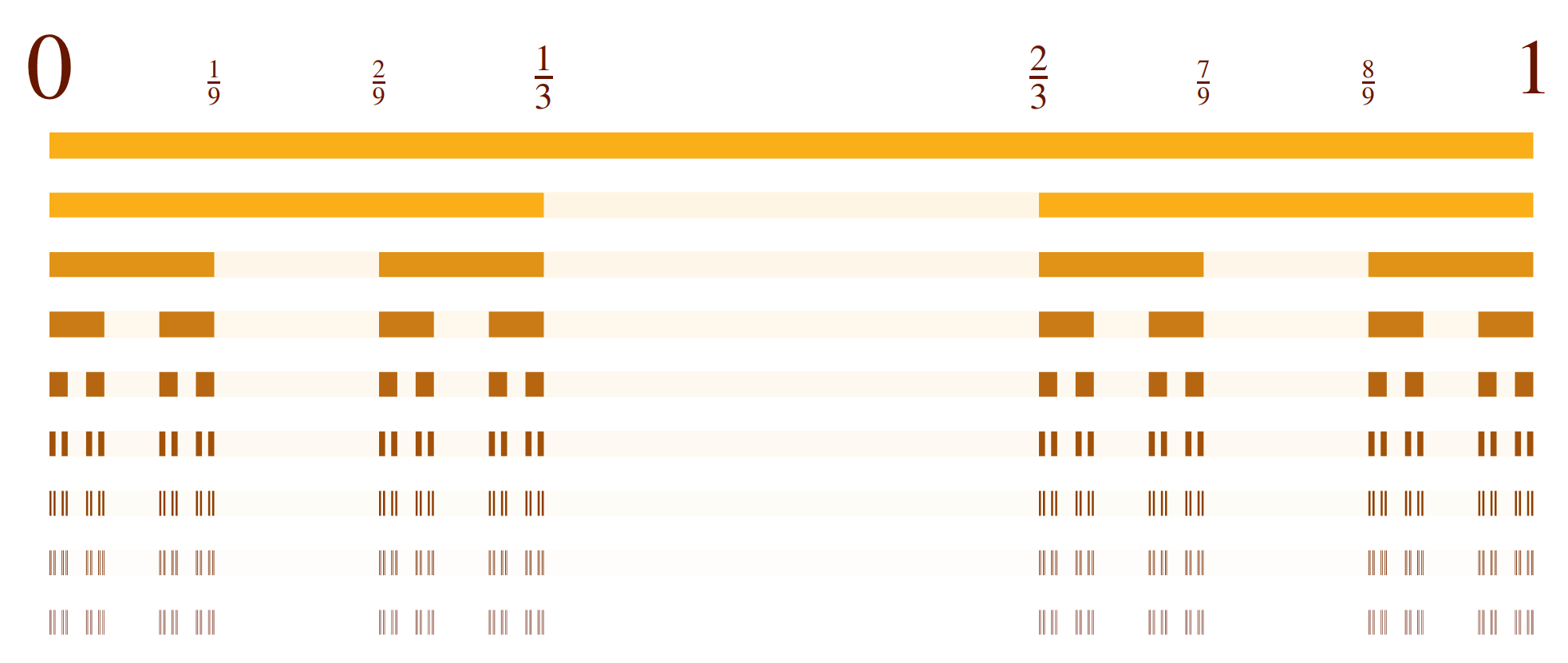
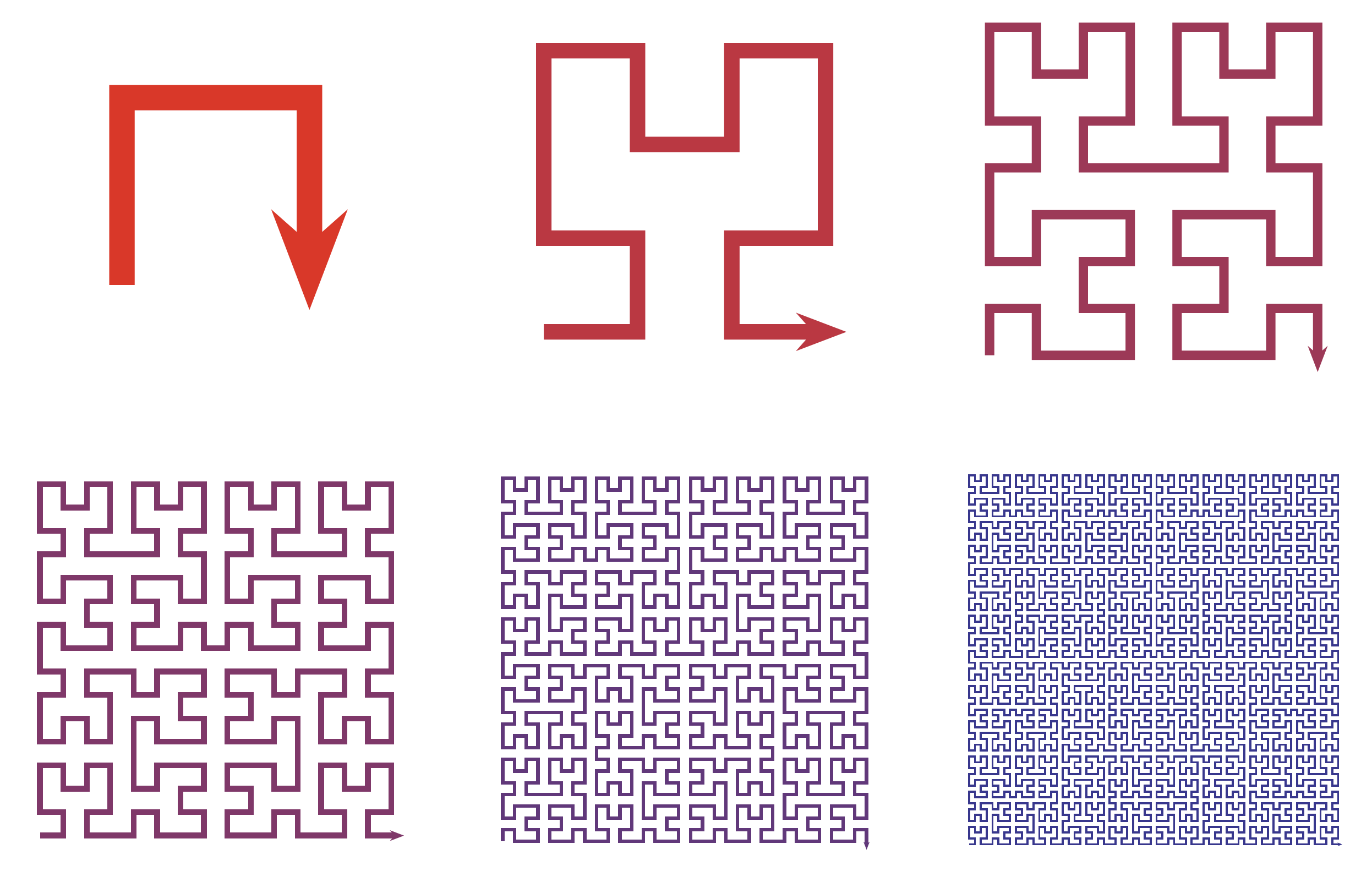
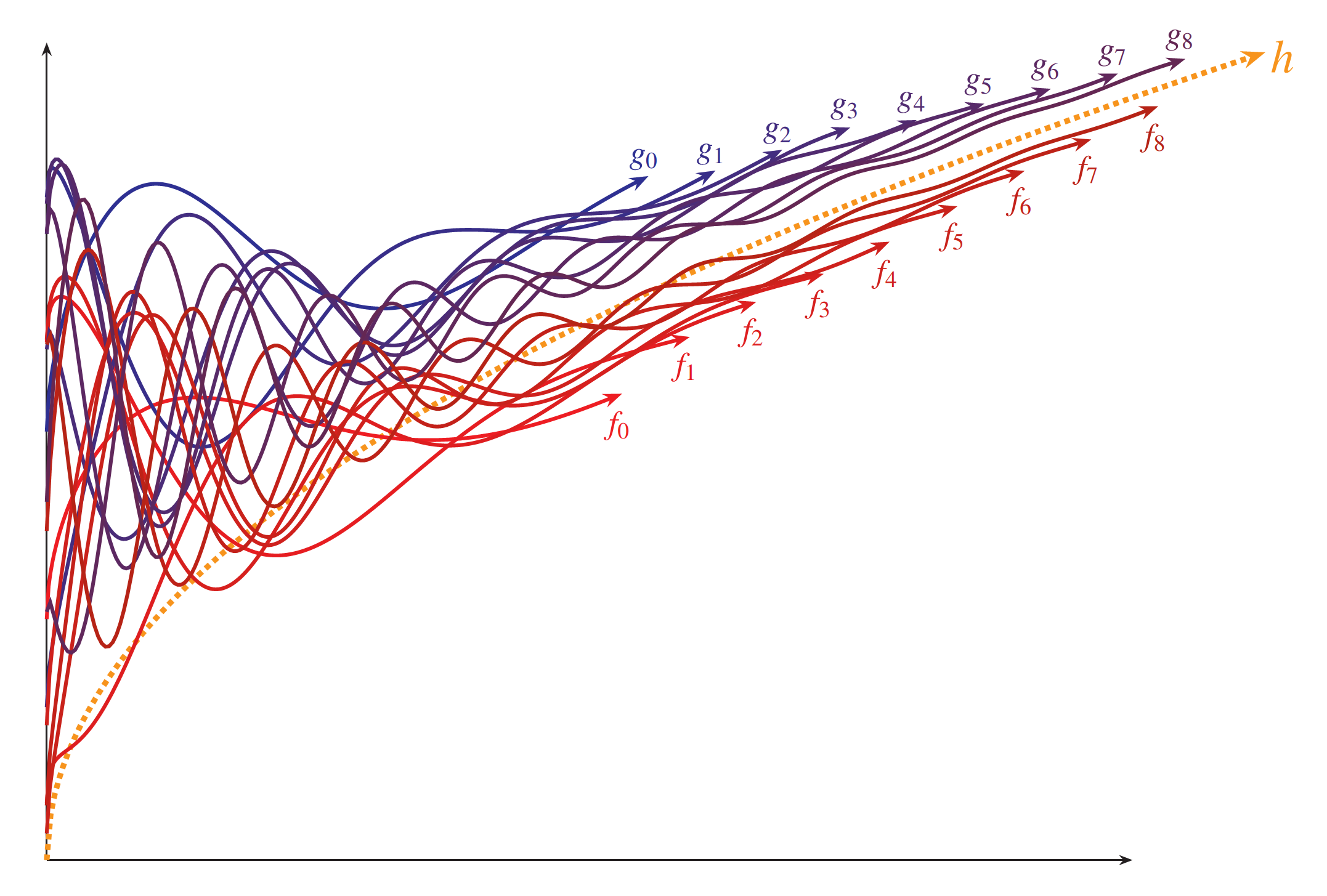
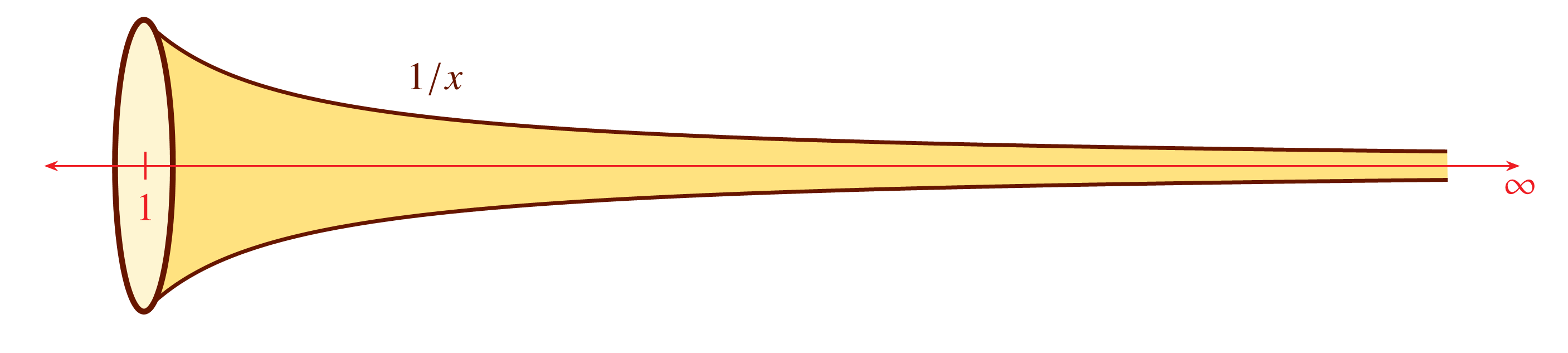
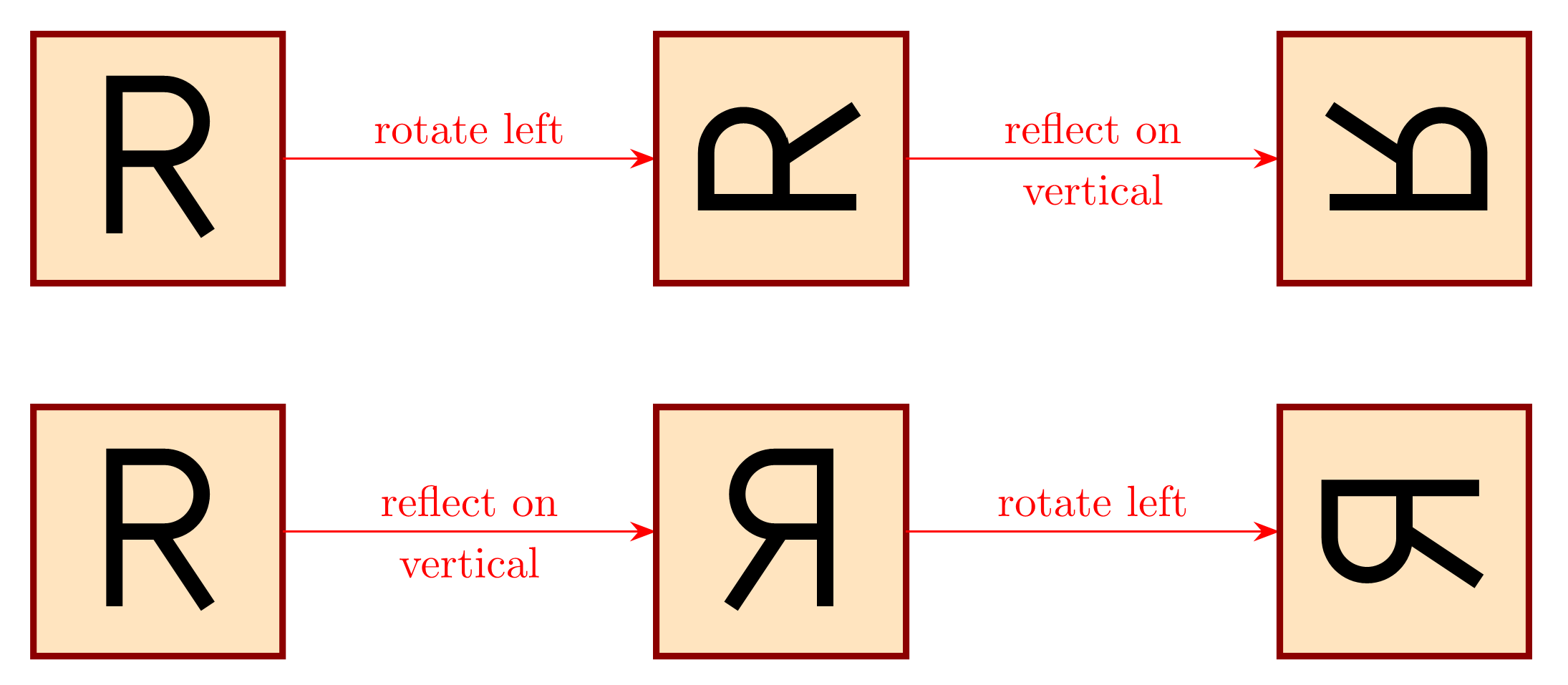
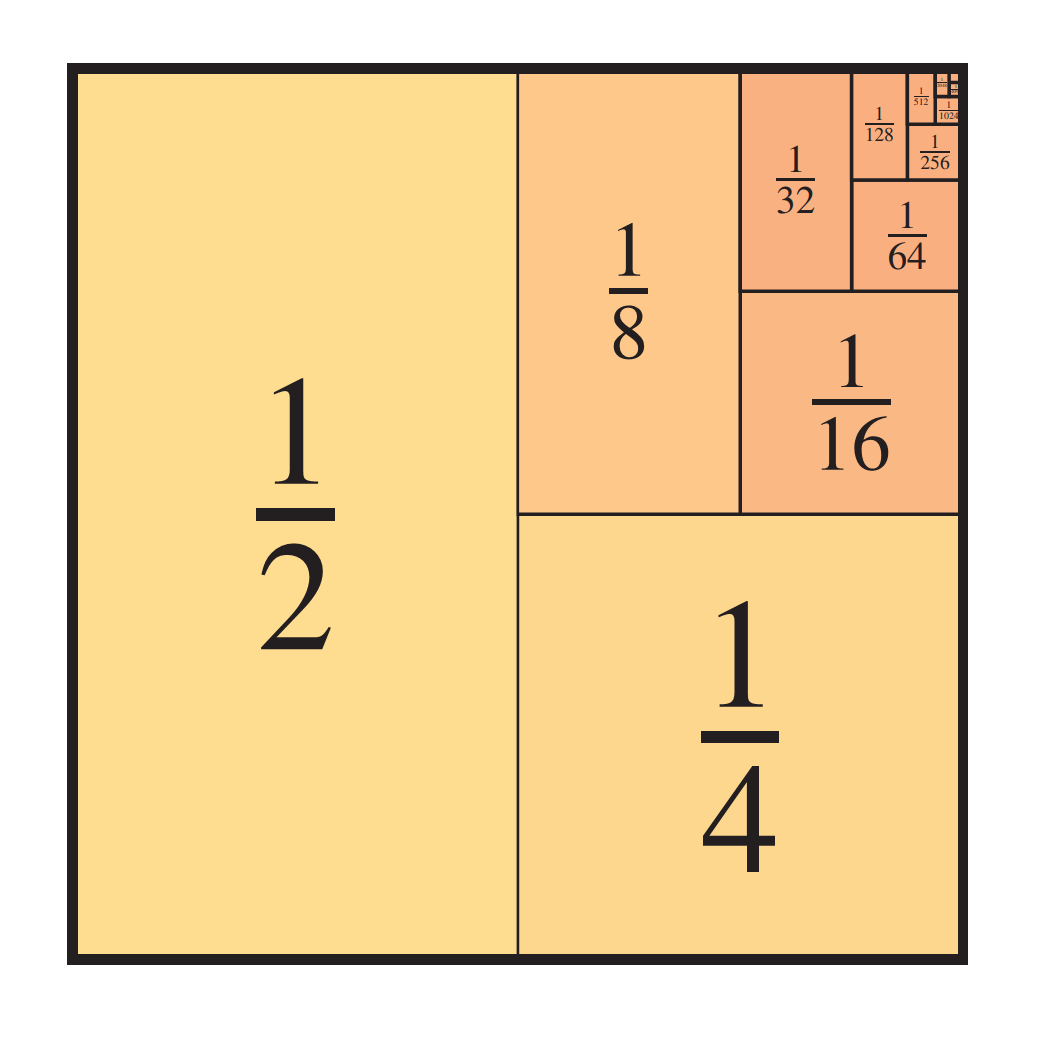
The book is packed with full-color mathematical figures—over 200 color figures, of my own design, which I produced in LaTeX using TikZ. Here are a few samples:
And many others! Each figure is woven into the text to help explain a mathematical or philosophical idea.
Order now!
Meanwhile, I am serializing all my other books-in-progress on Infinitely More—subscribe now for full access to all my current work, including the surreal numbers, games, logic, philosophy of mathematics, and more.
I am honored to be invited to give the Owen G. Owens Memorial Lecture at Wayne State University on 16 April 2026, joining a distinguished list of luminaries giving previous Owens lectures, including Gregory Margulis, John Milnor, Mikhael Gromov, John Conway, and many others.
Abstract. Let us explore the theory of finite and infinite games, from the hypergame paradox to the fundamental theorem of finite games, which generalizes to vast classes of infinite games. We shall see how the ideas play out in infinite chess, infinite draughts (checkers), infinite Hex, infinite Wordle, and many other games.
I have been asked by the ASL to fill in as a last-minute substitute speaker for the ASL session at the upcoming 2026 APA Central Division Meeting in Chicago, February 18-21, 2026, due to a late cancellation of one of the plenary speakers, James Walsh, who regrettably is unable to speak. My talk will be part of the Wednesday evening ASL session 6-7:50.
Please join me in Chicago at the elegant Palmer House hotel—we have a great lineup of talks.
Title: Mathematicians do not agree on the essential structure of the complex numbers
Abstract: What is the essential structure of the complex numbers? Mathematicians, it turns out, do not generally agree—indeed one can find sharply worded disagreements. Do we have a purely algebraic conception of the complex numbers, taking it as an algebraically closed field with only its algebraic structure? Or do we have an analytic view, as a field over the real numbers, distinguished as a particular subfield? Or should we have a topological view? Perhaps we have a rigid conception of the complex plane, with the coordinate structure of real and imaginary parts. Many mathematicians find it fundamentally wrong to break the symmetry between i and -i, and indeed the various perspectives give rise to fundamentally different understandings of the automorphism group, and they are not all fully bi-interpretable nor even mutually interpretable. I shall place the whole discussion into the context of the philosophy of structuralism and the question of what is a number.
This will be a talk at the CUNY Logic Workshop on 13 March 2026, held at the CUNY Graduate Center.
Abstract. I shall introduce the elementary theory of surreal arithmetic (SA), a first-order theory that is true in the surreal field when equipped with its birthday order structure. This structure, I shall prove, is bi-interpretable with the set-theoretic universe (V,∈), and indeed the theory of surreal arithmetic SA is bi-interpretable with ZFC. This is joint work in progress with myself, Junhong Chen, and Ruizhi Yang, of Fudan University, Shanghai.
This will be a talk for the Logic Seminar at the University of Notre Dame, Tuesday 18 November 20215 2pm 125 Hayes-Healy Building.
Abstract. I shall introduce what I call the first-order elementary theory of surreal arithmetic, a theory that is true in the surreal field when equipped with its birthday order structure. This structure, I shall prove, is bi-interpretable with the set-theoretic universe (V,∈), and indeed the theory of surreal arithmetic SA is bi-interpretable with ZFC. This is very new joint work in progress with myself, Junhong Chen, and Ruizhi Yang, of Fudan University, Shanghai.
I am honored to be giving the 2025-26 Charles R. DePrima Memorial Lecture for the Mathematics Department of the California Institute of Technology. This lecture series aims to bring mathematical researchers to Caltech to give talks for a primarily undergraduate audience.
This invitation truly gives me a lot of pleasure, first, because Caltech is my alma mater (B.S. Mathematics 1988), but second, because my daughter is currently an undergraduate student at Caltech, majoring in mathematics. So I am looking forward to this talk.
I feel a special affinity with Jörg, since we had both first come to Japan in 1998 at almost exactly the same time, within a week of each other, and naturally we were faced with similar bewildering differences in language and culture in those first early days after arriving in Japan. I had taken up a one-year JSPS Research Fellowship at Kobe University, while Jörg had entered into his permanent position there. He went on to build an impressive research career there with many accomplishments and many students. My own stay in Japan was a formative period in my life, greatly enjoyed.
At the banquet, I related some anecdotes from the early days, but also expressed heartfelt philosophical reflections on the significance of major life decisions and the sanguineity one might feel about alternative life paths not taken. What a blissful enjoyable life I might have had, for example, if I had somehow managed to remain in Japan and build a life there as Jörg has done.
I proceed to continue my remarks as follows regarding the Sannoymiya incident…
Allow me, finally, to relate what I know of the infamous Sannomiya incident, an event which marks to my way of thinking the time when Jörg first made his big splash in the Japanese art world, the time when he first hit the big stage.
It was a late summer afternoon, early evening, and Jörg, wearing his customary straw hat, was walking home down the mountain from the university into town. Carrying some newly procured oil paints, he was full of anticipation and artistic plans. Inadvisably, however, in his excitement he opened some of the tubes while he was walking, in order to judge the quality, in part by smelling the oils. At this, he was startled by a coarse grunt behind him on the trail—an inoshishi* had noticed the smell of the oils and begun to follow Jörg. And it wasn’t one of those small inoshishi that you can scare away by grunting yourself, but rather a large bold inoshishi. Jörg nervously quickened his pace to get away, gripping the oils tightly, but the inoshishi was gaining on him.
In his preoccupation with the inoshishi, Jörg hadn’t noticed the large crane flying over head. But the crane had definitely noticed Jörg, or more specifically, his straw hat, which I suppose the bird coveted for his nest. The bird swooped down and, with surprising speed, grabbed the hat directly off Jörg’s head!
Of course Jörg was not going to let a bird steal his hat, and he held fast onto it. In the struggle, with the bird’s great wings flapping and Jörg holding tight to the hat, he was stretched upward. The inoshishi saw his chance and charged right between Jörg’s legs, who was thrust up onto the back of the inoshishi, finding himself to be riding it like a horse.
The three of them were set galloping down the mountain. The great crane ahead, flapping its wings and pulling the hat, to which Jörg clung, while riding the squealing inoshishi, who carried them all down the mountain trail at full speed. Imagine the sight. Caught in the tight grasp of Jörg’s hands, paint began to ooze out of the tubes, which began to make a mess on Jörg, dripping also onto the inoshishi, who became increasingly splotched with various bright colors.
The trail came down to the precipice, where normally one would make the turn and continue on the trail downhill. But the crane had no reason to turn, and instead flew straight out over the edge. Inexplicably, Jörg did not let go and found himself dangling precariously as the bird flew out over the neighborhood below. The inoshishi, wrapped in Jörg’s legs and taken completely by surprise with this new situation, was gripping for dear life on to Jörg. In the frantic struggle, the inoshishi had bitten off both of Jörg’s shoes, which fell away below.
Thus the absurd triple—the great flying crane holding the hat, with now barefoot Jörg dangling below and the squealing inoshishi, covered with paint—soared over the city, heading to Sannomiya in the Kobe city center.
At that time there was a Matsuri summer festival taking place downtown, and people strolled about in elegant yukatas*, browsing the various fine fabrics on display, the theme of the festival. A great linen fabric, with an almost imperceptible white on white pattern, was spread across the big stage at the center of the festival, surrounded by onlookers who stood around it taking in its subtle, starkly spare nature.
Presently all attention turned skyward—the festival crowd gasped with bewilderment as Jörg and the crane and the squealing inoshishi came into view overhead. By this time, of course, the crane was tiring, and suddenly it just let go. The tangled paint-smeared mess of Jörg and the inoshishi fell to Earth, Splash!, landing right on the great white linen canvas spread upon the big stage.
The inoshishi stood up, grunting and squealing, but then, looking at the spot of the fall, let off a strange twitch and became suddenly transfixed, relaxed and silent. The crowd, initially full of shouts and alarm, also became suddenly calm, every person looking intently before them. Stepping back in his awkward barefootedness, Jörg realized that the people were not looking at him or at the inoshishi at all, but rather directly at the fabric, right at the spot right where they had landed. The inoshishi seemed as though hypnotized by the canvas, of course now smeared with paint from the crash, overcome with its……beauty. The people were similarly dumbstruck, overcome with emotion and profound meaning—to a person they gazed at the sublime work of art that Jörg and the inoshishi had created on the canvas.
A voice broke through the silence Ichi man en!*, an opening bid in the hotly contested impromptu auction that ensued. Soon, the work was sold for a great sum. Jörg was asked to sign his mark.
So that is what I know of the story of the Sannomiya incident, in which Jörg first made his big splash in the Japanese art scene, the time when he hit the big stage.
Now, I have heard that some people doubt this story, but then again, some people doubt the existence of a unique absolute set-theoretic universe, so evidently like Descartes one can doubt absolutely anything, even incontrovertible truths such as the account I have just related.
Joel David Hamkins 4 September 2025 Kobe, Japan
*An inoshishi is a kind of wild boar, commonly seen in the early evenings in the Kobe hills, including the university campus
*A yukata is a traditional cotton summer kimono, often worn by both men and women at summer festivals
*The phrase “ichi man en” means ten-thousand yen
Art Show next week
Incidentally, Jörg has an art show exhibition in Japan next week. Follow the links to the main show, which lists a few of his pieces there. Look under the category “Award Winning”.
Many years ago, I was a JSPS Fellow at Kobe University, at the same time that Jörg first took up his position in Japan, a time when Philip Welch also had his professorship there.
Title The elementary theory of surreal arithmetic is bi-interpretable with set theory
Speaker Joel David Hamkins, O’Hara Professor of Logic, University of Notre Dame
Abstract I shall introduce the first-order elementary theory of surreal arithmetic, a theory that is true in the surreal field when equipped with its birthday order. This structure is bi-interpretable with the set-theoretic universe (V,∈), and indeed the theory of surreal arithmetic SA is bi-interpretable with ZFC. This is a preliminary report on very new joint work in progress with myself, Junhong Chen, and Ruizhi Yang, both of Fudan University, Shanghai.
This will be a talk I shall give for the History and Philosophy of Science (HPS) Colloquium at the University of Notre Dame, 17 October 2025, 12:30-1:30 pm, 201 O’Shaughnessy Hall.
Did Turing ever halt?
Abstract. Alan Turing’s 1936 paper on computable numbers, perhaps one of the most impactful papers ever written, arguably spawned the fields of computability theory, complexity theory, and computer science, helping to usher in the computer age. He introduced Turing machines, provided the first universal computers, launched the investigation of the computable numbers, and proved the first instances of computable undecidability. Turing 1936 is widely credited, in nearly all the standard computability textbooks, for the undecidability of the halting problem, often viewed today as the seminal undecidability result, leading to all the others. The curious historical situation, however, is that there is no mention at all of the halting problem in Turing’s article and in fact Turing never considers the halting of his machines—he specifically designed them to run forever. In this talk (joint work with Theodor Nenu, Oxford), I shall discuss the curious history of the halting problem and the question of whether we rightly credit the undecidability result to Turing. I shall come eventually to a nuanced conclusion.
This will be a talk for the Fudan Logic Seminar at Fudan University, to be followed immediately by two talks for the Fudan Logic student seminar, forming a mini-conference for the logic group on 23 July 2025.
Abstract. I shall give an account of the theory of computable surreal numbers, proving that these form a real-closed field. Which real numbers arise as computable surreal numbers? You may be surprised to learn that some noncomputable real numbers are computable as surreal numbers, and indeed the computable surreal real numbers are exactly the hyperarithmetic reals. More generally, the computable surreal numbers are exactly those with a hyperarithmetic surreal sign sequence. This is joint work with Dan Turetsky, but we subsequently found that it is a rediscovery in part of earlier work of Jacob Lurie.
This will be a talk for the Seminar on Frontier Issues in Logic and Philosophy
The First Forum on Logic and Philosophy
逻辑与哲学前沿问题研究”学术研讨会暨第一届逻辑与哲学论坛
Changchun, China, 18-20 July 2025
Pointwise definable end-extensions of models of arithmetic and set theory
Abstract. The existence of pointwise definable models of set theory offers a fundamental engagement with what has become known as the Math Tea argument, according to which there must be undefinable real numbers, since there are only countable many definitions, but uncountably many real numbers. I shall present a new flexible model-theoretic method showing that every countable model of Peano Arithmetic (PA) admits a pointwise definable end-extension, one in which every object is definable without parameters. The argument makes a fundamental use of the universal algorithm. Also, any model of PA of size at most continuum admits an extension that is Leibnizian, meaning that any two distinct points are separated by some expressible property. Similar results hold in set theory, where one can also achieve V=L in the extension, or indeed any suitable theory holding in an inner model of the original model.
This will be a lecture series on the Philosophy of Mathematics at Fudan University in Shanghai, China, 30 June – 25 July 2025, as a part of the International Summer School program at Fudan University. Lectures given by Ruizhi Yang and myself.
My lectures begin 7 July, with the following themes:
How the continuum hypothesis might have been a fundamental axiom
Abstract. I shall describe a historical thought experiment showing how our attitude toward the continuum hypothesis could easily have been very different than it is. If our mathematical history had been just a little different, I claim, if certain mathematical discoveries had been made in a slightly different order, then we would naturally view the continuum hypothesis as a fundamental axiom of set theory, necessary for mathematics and indeed indispensable for calculus.
This will be a talk for the Conference on Infinity, a collaborative meeting of logicians and specialists in Chinese philosophy here at Peking University, 24 June 2025, in the philosophy department.
Abstract. I shall lay out a spectrum of fundamentally different potentialist conceptions of infinity. The differences in these potentialist ideas become especially clear when adopting a modal perspective on potentialism, grounded in the ideas of modal logic. I shall argue that some forms of potentialism, the “convergent” forms, are implicitly actualist, whereas the radical branching form of potentialism is more truly potentialist in nature.